
Authors : Zihan Zhang, Meng Fang, Ling Chen, Mohammad-Reza Namazi-Rad, Jun Wang
Institution : University of Technology Sydney, University of Liverpool, University of Wollongong, University College London
Publication Date : Oct 11, 2023
Paper link : https://arxiv.org/abs/2310.07343v1
소개
이 논문은 계속 변화하는 세상의 지식을 어떻게 처리할 지에 대한 최근 연구들을 소개합니다.
지식을 처리하는 방식을 fig2 처럼 크게 2가지 방법으로 분리합니다.
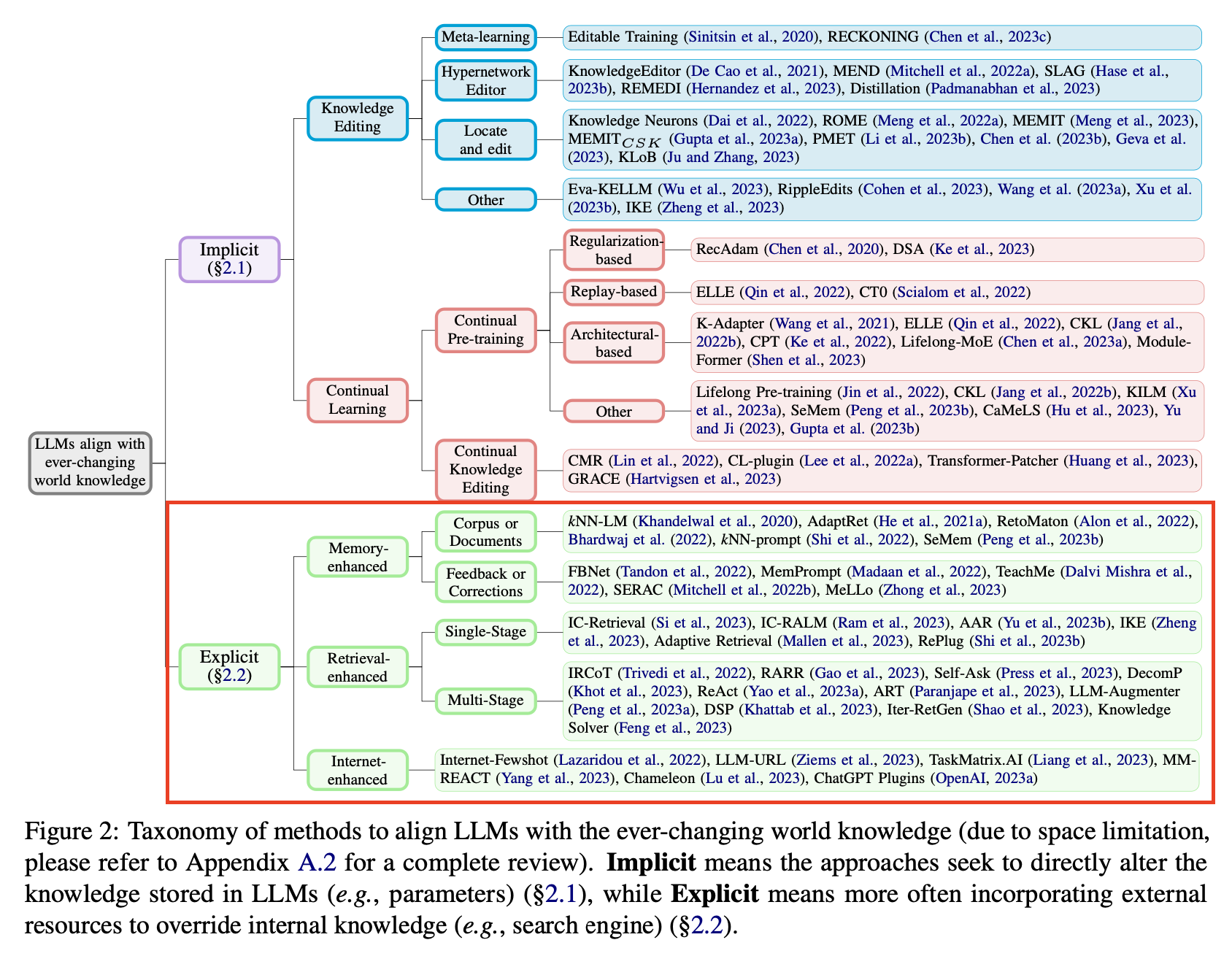
- Implicit(내재적 방식): 모델 학습 방식
- Explicit(외재적 방식): 외부 지식 활용 방식
요즘은 1, 2번 둘 다 활용하는 추세고 둘 다 필요하다는 입장이지만 제가 하는 일이 2번이고 현재 2번에서 성능 개선을 바라고 있기 때문에 2번에 대해서만 각 방식의 특징에 대해 다루도록 하겠습니다.
외재적 방식의 공통점은 다음 table1에서 확인할 수 있습니다.
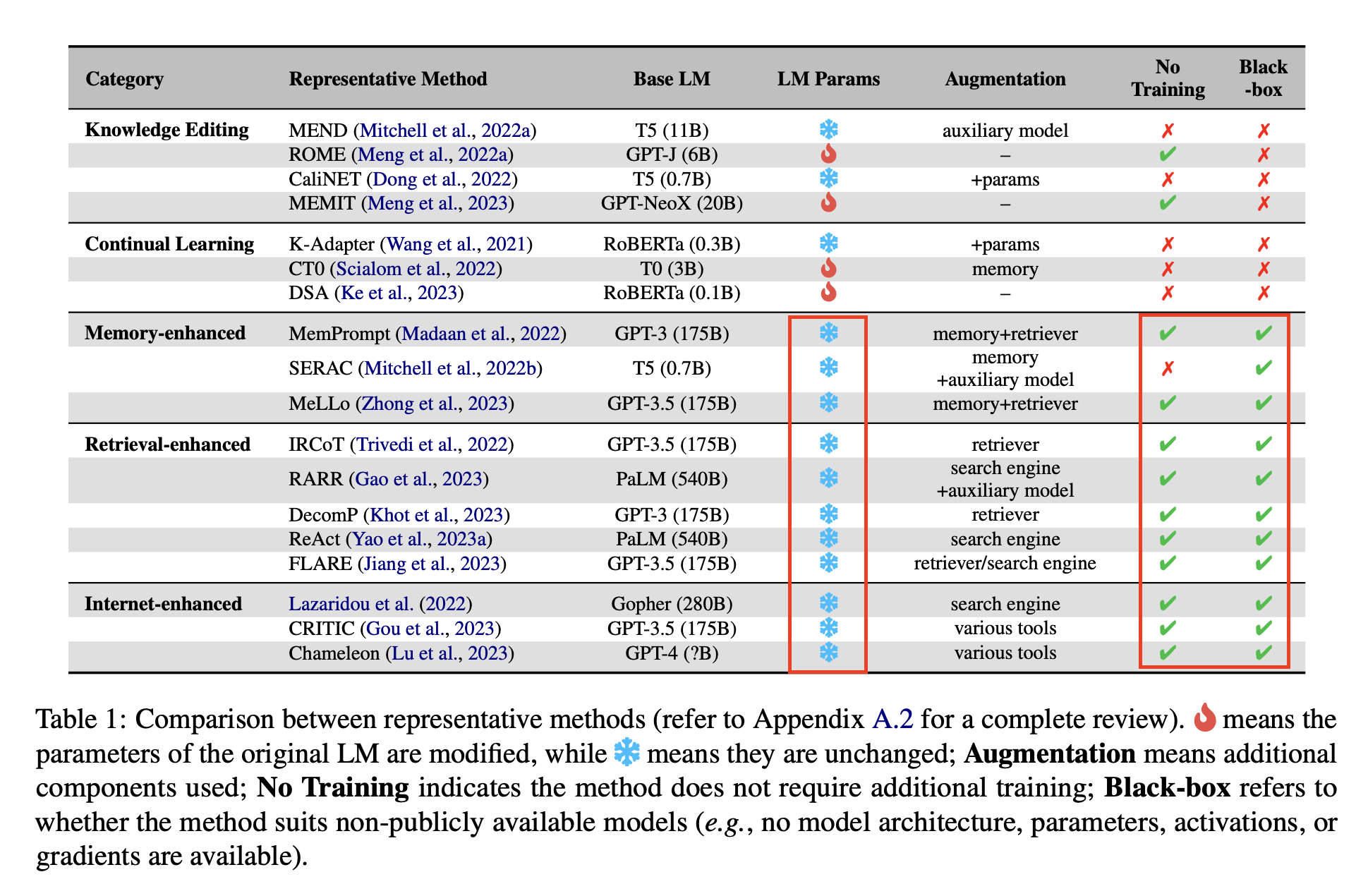
- LM params 고정: 변화하는 지식에 대한 대처를 외부 지식에 의존하기 때문에 Original LM 혹은 Base LM 학습을 하지 않음
- 추가 학습 안함: (SERAC를 제외하고는) 추가 학습을 하지 않음
- Black-box: 공개되지 않은 모델에 적합한지 여부(예: 모델 아키텍처, 매개변수, 활성화 또는 그라데이션을 사용할 수 없는 경우)
- 공통적으로 가능하다는 점 -> 모두 함께 활용 가능
기존 RAG 모델은 retrieval 모델을 LM과 함께 학습하였지만 이는 공개된 LLM(e.g. ChatGPT)에 적용하기 어렵게 만들었습니다.
(이것은 무슨 의미일까요??) 잠깐 찾아봤을 땐 retrieval 모델과 LM이 학습 데이터가 달라서? 학습 목표가 달라서? 두 개를 합치해서 사용하는 것이 어렵다 라는 의견을 봤는데 그럼 외재적 방식이 다 해당되는게 아닌가 싶네요.
외재적 방식의 3가지 방법은 LLM은 고정하고
- 외부 메모리를 사용하거나(Memory-enhanced)
- 기존에 존재하는 retriever을 사용하거나(Retrieval-enhanced)
- 인터넷을 사용하는 방식으로(Internet-enhanced)
변화하는 지식에 대처합니다.
Memory-enhanced 방식
- Memory-enhanced 방식: 정적인 LLM + 증가하는 비모수 메모리
- -> 추론 중에 메모리에 있는 지식 이상의 정보 잡아낼 수 있음
- 외부 메모리에는 새로운 정보가 포함된 최근 말뭉치 또는 피드백을 저장할 수 있음
kNN-LM: 코퍼스/문서 저장
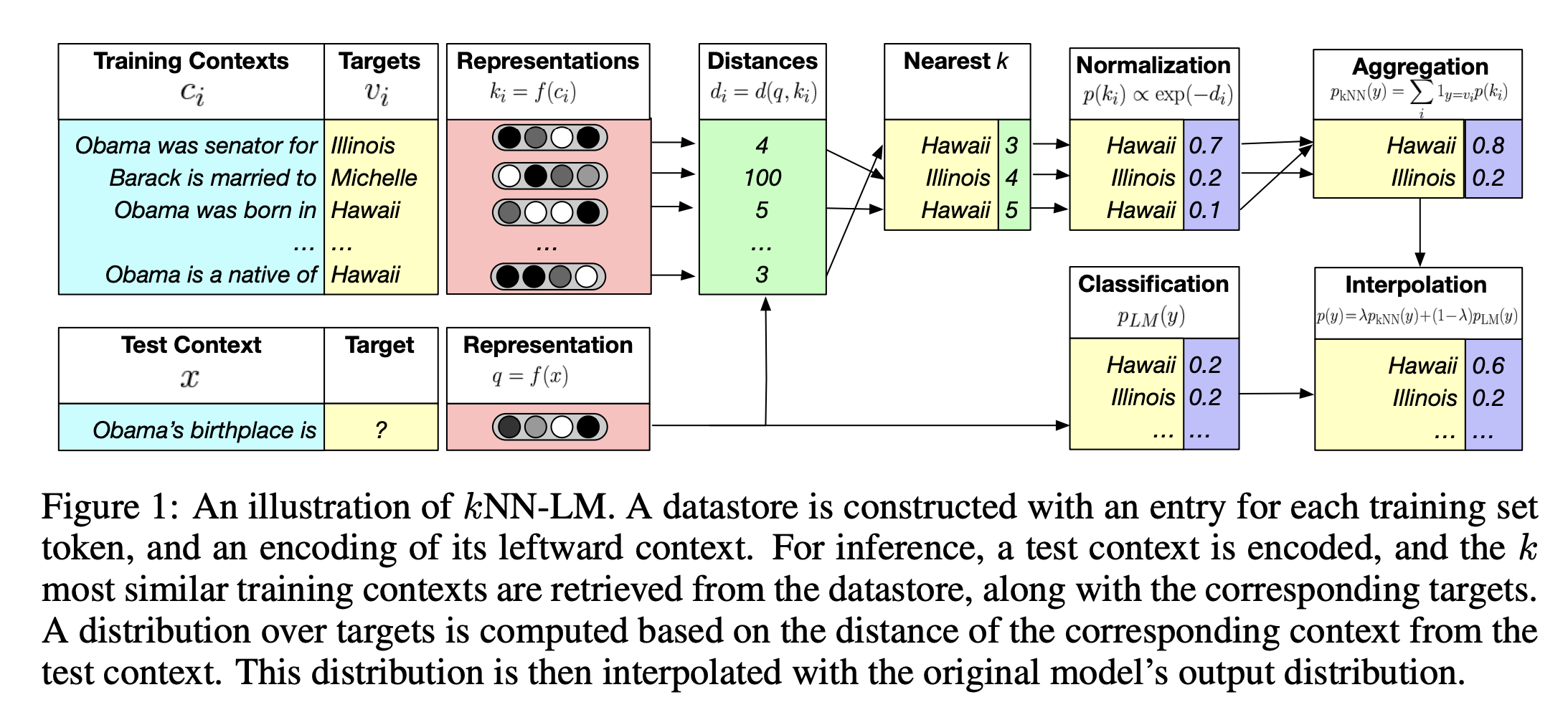
- 메모리에 key-value 형태로 모든 <context, token> 을 저장
- 추론할 때, 메모리에 있는 k개의 가까운 토큰에서 추출한 분포로 고정된 LLM을 보간(interpolate)하여 다음 토큰의 확률을 계산
- 보간하다는 말은 두 개의 값을 이용하여 사이에 존재할 법한 값을 추정하는 것을 의미
- 거리는 사전학습 LM의 임베딩 공간에서의 거리를 계산한 값
- 불필요한 추출을 생략 -> kNN-LM의 효율성 향상
- 추출된 맥락에 정보를 통합하기 위해 gnn(graph neural network) 활용 -> 생성 퀄리티 향상
- continual learning 에 kNN-LM 을 적용한 사례도 있음
- downstream task에 대한 zero-shot 추론에 적용한 사례도 있음
피드백/수정사항 저장
- 사용자 피드백 저장 -> 모델의 문제 있는 예측 고치고, 미래의 동일한 에러를 방지
- 모델 출력값을 수정하기 위해 피드백을 적용하는 보조 보정기를 학습
- 사용자가 시스템과 상호 작용을 해보고 잘못된 경우 수정할 수 있도록 설계
- 일부러 오답 질문을 하고 수정 피드백을 주는 설계
- (공통사항) 업데이트된 지식을 메모리에 명시적으로 보관
- (Mitchell) 입력 -> 분류기(관련 수정 사항이 메모리에 존재하는지 판단) -> counterfactual 모델을 통해 지식 업데이트 수행
- (Zhong) 복잡한 질문을 분해하여 베이스 모델에 임시 답변을 생성하도록 요청 -> 생성된 답변이 기억에서 검색된 사실과 모순될 경우 모델 출력을 수정
Retrieval-enhanced 방식
- 기존 retrieval 모델 + multi learner로서의 LLM + 프롬프트 조합 방식
- 단일 단계 방식과 다단계 방식으로 분류
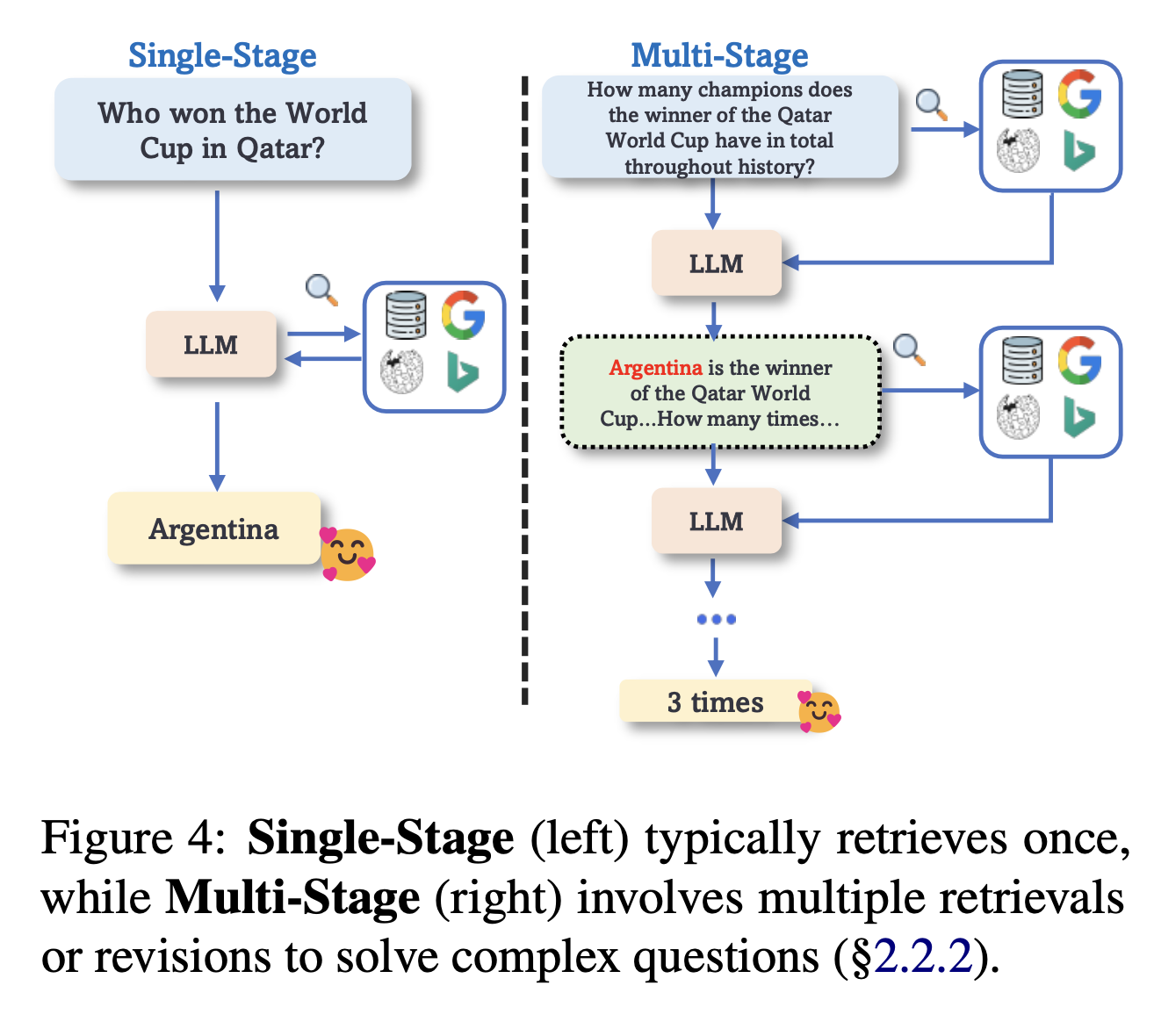
Single-stage
- 사용자 입력에 대해 검색을 한 번 사용 + LLM 활용
- 각 입력에 대해 유사한 설명을 검색하여 문맥 내에서 편집 수행
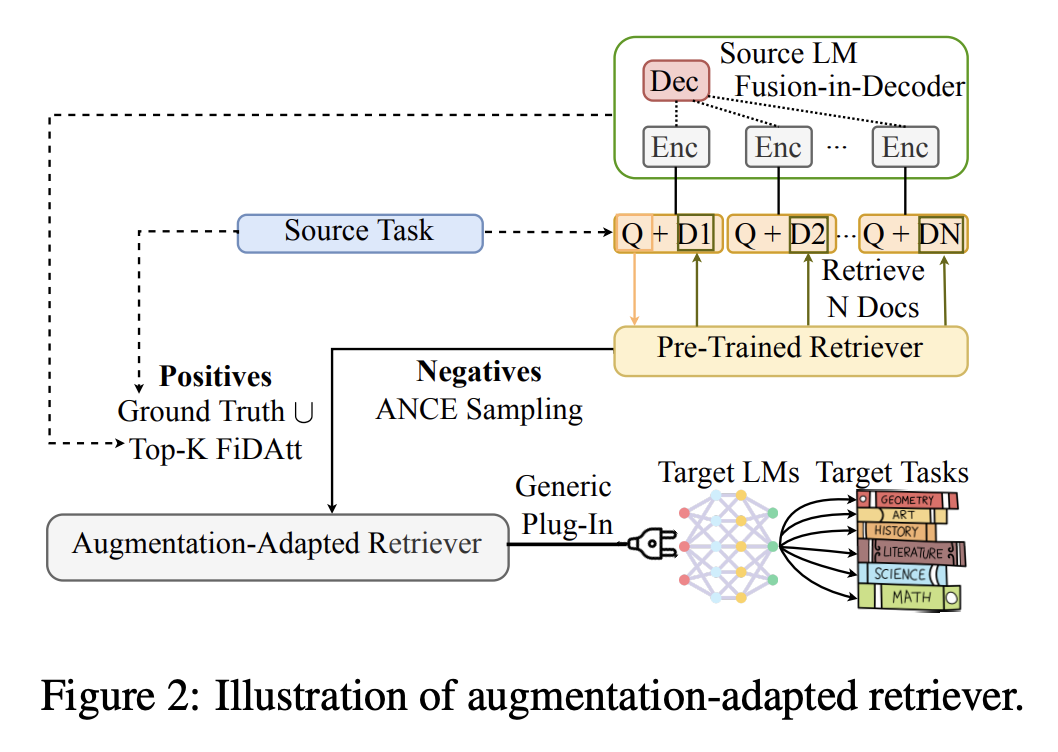
- 범용 retriever 이 최선이 아닐 수 있음 - Augmentation-Adapted Retriever (AAR)
- AAR은 블랙박스인 LM의 다운스트림 태스크를 돕기 위해 범용 플러그인으로 활용하기 위해 제안됨.
- 사전 학습된 retriever 을 활용하여 사용자 쿼리에 대한 N개의 문서를 검색
- 작은 인코더-디코더 모델을 사용했고 그 모델의 FiD attention score를 활용하여 LM 선호 문서에 대한 라벨링을 수행했음 + 인간 선호 문서와 함께 positive sample로 활용
- 사전 학습된 retriever로는 ANCE 샘플링 기법으로 negative sample을 가져옴
- AAR은 이 두 종류의 표본을 활용하여 파인튜닝
-
추론 시에 AAR은 제로샷 생성 태스크를 위한 unseen LM을 보조함
- source LM(인코더-디코더 모델; Flan T5)은 LM 선호 신호를 제공(작은 LM 활용)
- FiD(디코더 모델; InstructGPT)로는 쿼리에 검색된 내용을 FiD 기법으로 답변 생성
- FiD cross-attention(FiDAtt) score를 활용하여 생성 답변의 Top-k 의 positive sample 을 선택
- 사전 학습된 retriever로는 ANCE 샘플링 기법으로 negative sample을 가져옴
- target tasks를 위한 target LMs에 AAR 결과 활용
- target은 source와 겹치는 내용 없음(unseen)
- 엔티티의 popularity에 기반한 휴리스틱 활용하여 효율성 높이는 방식도 있음
- 입력 질문 내의 엔티티 popularity가 낮은 경우에만 관련 문맥을 검색하여 성능 개선
- 추론 비용 효율화
- 제한된 컨텍스트 길이 이슈 해결을 위한 방법
- 검색된 각 문서를 LLM에 개별적으로 추가한 다음 여러 패스의 출력 확률을 앙상블
Multi-stage
- Chain of thoughts
- multi-step reasoning
- 복잡한 문제는 서브 문제로 나눠서 각기 검색을 통해 생성
- 지식 그래프를 활용하기도 함.
Internet-enhanced 방식
- 이전 방식은 정적이거나 offline 지식에서 정보를 가져옴 -> 가장 최신의 정보라고 볼 수 없음
- real-time으로 웹 서치하여 지식을 가져오는 방식도 최근에는 사용
- LangChain, ChatGPT Plugins 등 툴에서 쉽게 웹서치를 연결할 수 있음
- LLM을 중앙의 플래너로 보고 다양한 plug-and-play 툴을 연결하여 복잡한 문제를 해결하려는 시도도 있음
장단
- memory-enhanced, retrieval-enhanced 방식이 효율적이긴 하나 주기적인 지식 업데이트가 필요함
- Internet-enhanced 방식은 real-time web search를 통해 최신 정보에 대한 이슈는 없지만 정제되지 않은 품질이 떨어지는 데이터에 대한 문제는 남아있음.
- single-stage retrieval 방식에 비해 multi-stage retrieval은 복잡한 문제를 더 잘 풀지만 상당한 추론 오버헤드가 있음.
- 추출된 지식의 필터링이 필요 -> 관련 없는 내용 줄여서 LLM에 부담 줄임, 입력 길이 제한
- 추출 자체를 제한적으로 수행 -> 추론 오버헤드 줄임
활용 및 논의점
- 프롬프트에 지식을 추가하는 것 이외에 지식을 LLM의 결과에 보간하는 과정을 추가해보는 건 어떨지
- 추후에는 피드백을 반영하는 시스템을 구축
- 과거와 현재 들어온 지식 간의 충돌이 벌어졌을 때 옳은 것이 어떤 것인지 판단을 할 수 있을까?
- 현재 사용하는 필터링을 AAR로 대체할 수 있나?
- 필요한 시점의 검색을 어떻게 정하는가
- 인터넷 지식을 가져올 때 신뢰도와 노이즈 제거는 어떤 방식이 좋을까?
- 프롬프트의 내용과 LLM 내의 지식이 충돌을 일으켰을 때 어떻게 처리해야 하는지, 어떻게 우선순위를 잡을 수 있을지
References