
개괄
이전 챕터까지 우리가 따라해보려는 데이터셋 하나를 가지고 새로운 샘플을 만들어낼 수 있는 모델을 훈련하는 여러 방법들을 알아보았다.(VAE, GAN 등) 이번 챕터에서는 여러 데이터셋에 적용해보고, VAEs와 GANs가 내재된 잠재공간과 original pixel space 사이의 매핑을 어떻게 학습하는지 알아볼 것이다.
Generative model의 또 다른 응용분야에는 style transfer 분야가 있다. 여기서 우리의 목적은 입력 기반 이미지를 변형시킬 수 있는 모델을 만들어서 주어진 스타일 이미지 셋 같이 동일한 컬렌션으로부터 온 인상을 주는 것이다.

style transfer의 목적은 스타일 이미지의 내재된 분포를 모델링하려는 것이 아니라 이 이미지들로부터 stylistic component를 추출하고 이 컴포넌트를 베이스 이미지에 내장하는 것이다. 베이스 이미지에 스타일 이미지를 덧붙이면 스타일 이미지의 컨텐트가 속이 들여다보이고 색깔이 탁하고 희미해져서 이 방식으로는 완전히 합칠 수 없다. 그리고 한 종류의 스타일 이미지로는 화가의 스타일을 캡쳐할 수 없다. 그래서 그 화가의 전체 이미지에 걸쳐서 스타일(화풍)을 학습할 모델을 만드는 방법을 찾아야 한다. 그 화가가 베이스 이미지를 작품의 원작을 만들고 그 콜렉션 내의 다른 작품에서 동일한 화풍이 반영되도록 안내하는데 사용한다는 인상을 주고 싶다.
이번 챕터에서는 두 가지 종류의 style transfer model(CycleGAN, Neural Style Transfer)을 어떻게 빌드하는지 배우고, 이 기술들을 사진과 작품에 적용해 볼 것이다. 청과물 가게 예시로 시작을 하도록 한다.
Apples and Oranges
할머니 Smith와 Florida는 청과물점을 함께 소유하고 있다. 둘은 효율적으로 가게를 운영하기 위해 각각 다른 영역을 맡고 있다. 할머니는 사과를, Florida는 오렌지를 담당한다. 두 사람 모두 자신이 더 나은 과일 진열품을 가지고 있다고 확신하고 있기 때문에 그들은 다음과 같은 거래에 동의한다:
사과 판매로 얻는 이익은 전적으로 할머니 Smith에게 돌아갈 것이고 오렌지의 판매로 얻는 이익은 전적으로 Florida에게로 가게 될 것이다.
불행하게도 두 명 모두 공정한 경쟁을 계획하지 않는다. Florida가 보지 않을 때, 할머니는 오렌지 구역으로 슬쩍 넘어가서 오렌지를 빨간색으로 칠해서 사과처럼 보이게 만든다. Florida도 동일한 게획을 하고 있고 할머니의 사과들을 오렌지처럼 보이게 하려고 스트레이를 몰래 뿌리려 한다.
손님들이 과일을 셀프계산대로 가져오면 기계에서 잘못된 옵션을 선택하는 경우가 있다. 하루의 끝에는 과일별 이익을 합하고 그들의 정책에 따라 분할한다. 할머니는 그녀의 사과 중 하나가 오렌지로 팔릴 때 매번 돈을 잃고, Florida는 그녀의 오렌지가 사과로 팔릴 때 돈을 잃는다. 마감 후에 두 주인들은 기분 상하면서도 상대방의 짖궂은 행동을 막는 게 아니라 그들의 과일이 바뀌기 전에 더 원래의 것처럼 보이게 하려고 만든다. 만약 과일이 제대로 보이지 않는다면, 그들은 다음날 그것을 팔 수 없을 것이고 다시 이윤을 잃을 것이기 때문에, 그들이 이것을 바로 잡는 것이 중요하다. 또한 일관성을 유지하기 위해, 그들은 위장하는 기술을 자신의 과일로 시험해본다. Florida는 오렌지에 스프레이를 뿌렸을 때 원래 하던 것과 똑같이 보이는지 체크한다. 할머니도 같은 이유로 사과에 사과 그림 그리는 기술을 시험한다. 그들의 기술이 헛되었다는 것을 알게 된다면, 그들은 애써 번 수익을 더 나은 기술을 배우는 데 써야 할 것이다.
이 전체적인 프로세스는 Figure 5-2와 같다.

처음엔 손님들이 속겠지만 갈수록 손님들도 그 속이는 기술에 적응하여 속인 것이 어떤 것인지 점점 구별 능력을 기를 것이다. 이는 할머니와 Florida의 위장 기술을 더 고도화하게 하는 촉매제가 된다.
이 우스꽝스러운 게임을 몇 주간 해보니, 엄청난 일이 일어났다. 고객들은 진짜와 가짜를 구분할 수 있다고 못했으며 엄청 헷갈려했다.
CycleGAN
앞선 이야기는 생성 모델과 특히 style transfer(the cycle-consistent adversarial network, or CycleGAN) 개발에 대한 우화이다. CycleGAN의 원논문에서는 style transfer의 성장에 큰 기여를 했는데 이는 짝을 이룬 예제가 있는 training set 없이, reference 이미지 셋에서 다른 이미지로 스타일을 복사할 수 있는 모델을 훈련하는 것이 어떻게 가능한지를 보여주었다는 것이다.
pix2pix 같은 이전의 style transfer 모델들은 training set의 각 이미지가 source와 target domain 모두에 있어야 했다. 몇몇 스타일 문제 상황(e.g. 흑백 사진에서 컬러 사진으로, 위성 이미지에 대한 지도)에서는 이러한 데이터셋을 만드는 것이 가능하지만 다른 경우에는 불가능하다. 예를 들어, 우리는 모네가 수련 시리즈를 그린 연못의 원본 사진도 없고, 엠파이어 스테이트 빌딩의 피카소 그림도 없다. 동일한 위치에 말과 얼룩말을 위치시킨 사진을 배열하는 데에도 엄청난 노력이 요구된다.
CycleGAN 논문은 pix2pix 논문이 나오고 몇달 안되서 발표가 되었고 source와 target domain에 pair image가 없는 문제를 해결하는 모델을 어떻게 훈련시키는지 보여주었다. Figure 5-4가 두 모델의 차이점을 보여준다.
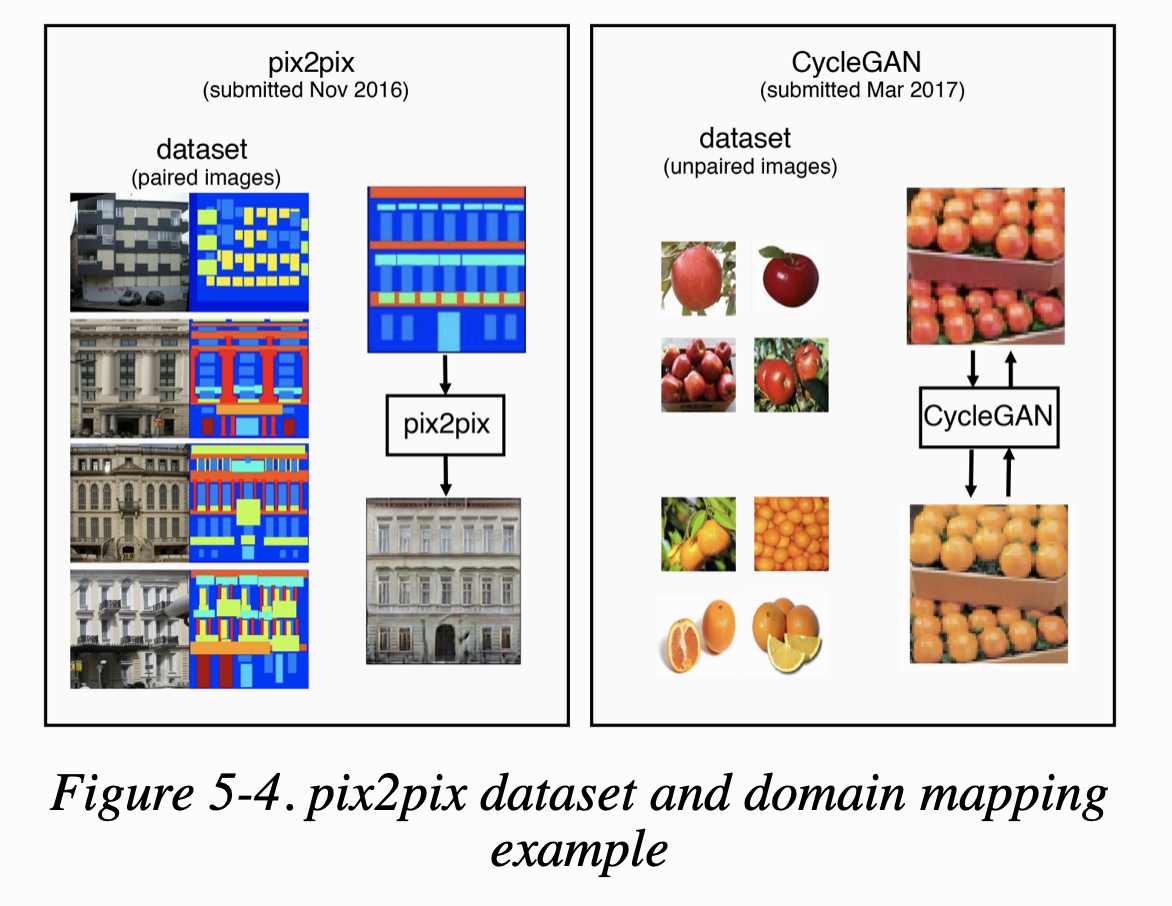
pix2pix model은 source에서 target으로 한 방향으로만 작동하지만, CycleGAN은 동시에 양방향으로 모델을 훈련시킨다. 그래서 CycleGAN의 모델은 source에서 target으로 하는 것만큼 target에서 source로도 이미지를 바꾸는 것을 배운다.
이제 Keras를 이용해 CycleGAN 모델을 빌드해보겠다.
Your First CycleGAN
data
- 앞선 이야기에 나오는 사과와 오렌지 예제를 사용한다.
- download script
```shell script $bash ./scripts/download_cyclegan_data.sh apple2orange
<br>
데이터는 4개 폴더로 구분된다.
* trainA : 사과
* testA : 사과
* trainB : 오렌지
* testB : 오렌지
목표는 train dataset을 사용하여 이미지를 domain A(사과)에서 B(오렌지)로 그리고 그 반대로 변환하면서 모델을 훈련시키는 것이다.
<br>
## Overview
<br>
CycleGAN은 사실 4개의 모델로 구성되어 있다. 두 개의 generator와 두 개의 discriminator이다.
* 첫 번째 generator(G_AB) : 이미지를 A --> B 로 변환
* 두 번째 generator(G_BA) : 이미지를 B --> A 로 변환
generator를 훈련시킬 paired images가 없기 때문에 이미지가 generator에 의해 만들어진 것인지 판단하는 두 개의 discriminator도 필요하다.
* 첫 번째 discriminator(D_A) : domain A의 실제 이미지인지 G_BA가 만들어낸 가짜 이미지의 차이를 식별하도록 학습
* 두 번째 discriminator(D_B) : domain B의 실제 이미지인지 G_AB가 만들어낸 가짜 이미지의 차이를 식별하도록 학습
위의 관계는 Figure 5-5에서 볼 수 있다.
<center><img src="https://liger82.github.io/assets/img/post/20200112-GAN_chapter5/GAN-figure5-5.png" width="60%"></center><br>
* code file
* 05_01_cycle-gan_train.ipynb(main)
* models/cycleGAN.py
<br>
*Example 5-1. Defining the CycleGAN*
```python
gan = CycleGAN(
input_dim = (128,128,3)
, learning_rate = 0.0002
, lambda_validation = 1
, lambda_reconstr = 10
, lambda_id = 2
, generator_type = 'u-net'
, gen_n_filters = 32
, disc_n_filters = 32
)
generator의 아키텍쳐부터 살펴보면, 보통 CycleGAN generator는 두 가지 중 하나를 사용한다; U-Net or ResNet(residual network) pix2pix 논문에서는 U-Net 아키텍쳐를 사용했지만 CycleGAN에서는 ResNet을 사용한다. 이 챕터에서는 두 가지 모두를 사용해볼 것이다. 먼저, U-Net부터.
The Generator (U-Net)
Figure 5-6은 U-Net의 아키텍쳐를 보여준다. 왜 U-Net이라고 명명되었는지 바로 알 수 있다.
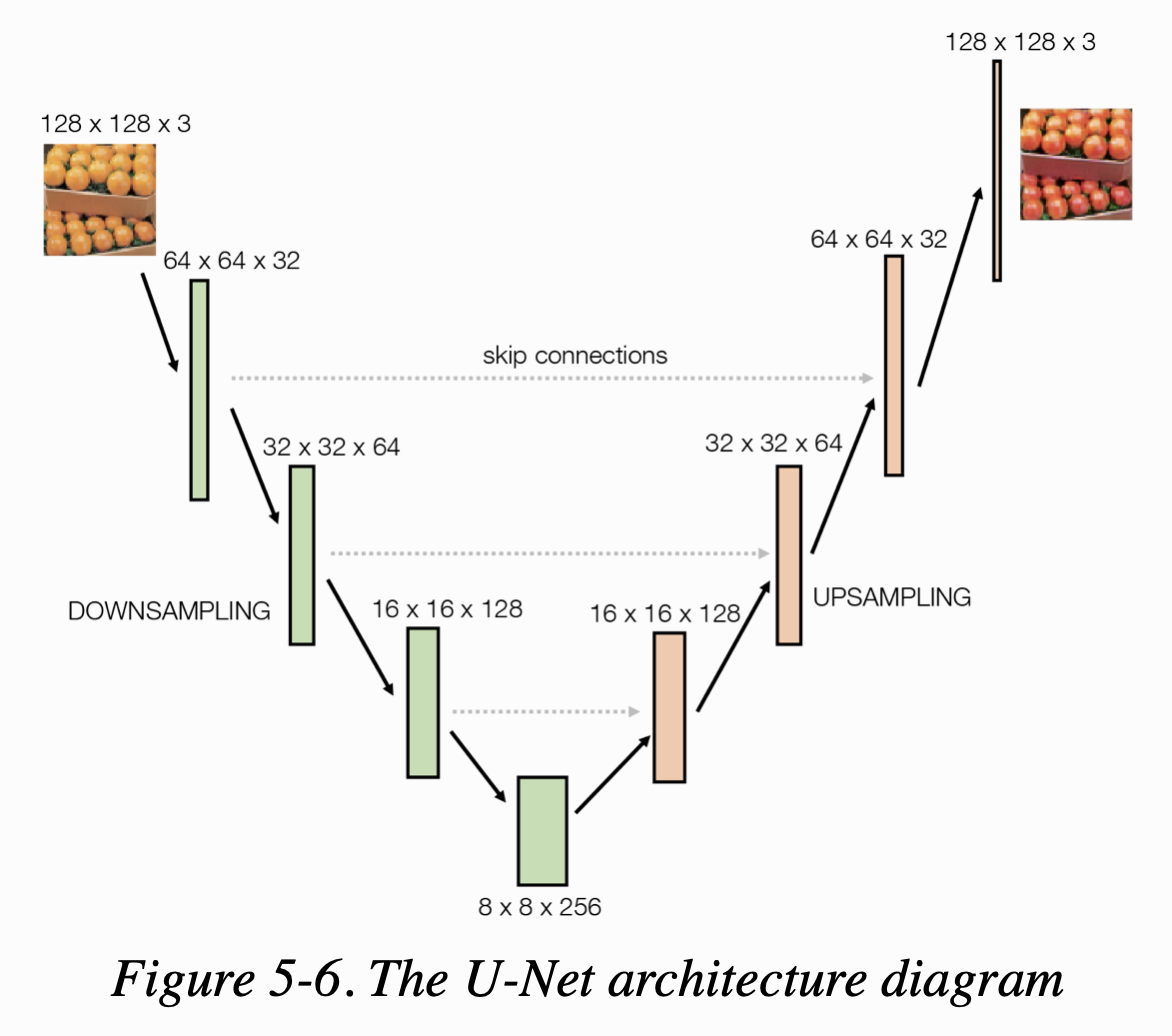
VAE와 동일한 방식으로 U-Net은 반 쪽짜리 두 개로 이루어져 있다
- downsampling 반 : input images를 공간적으로 압축하지만 채널은 넓게 늘린다.
- upsampling 반 : representation값을 공간적으로 팽창시키고 채널 개수는 줄인다.
VAE와 달리, U-Net의 양 쪽에는 skip connection이 동일하게 존재한다.
- VAE는 선형적이다; 데이터가 네트워크를 통해 input에서 output으로, 하나의 레이어에서 다음 레이어로 흐른다.
- U-Net은 비선형적이다; 정보를 지름길을 통해 (바로 다음이 아니라) 그 이후의 레이어로 흐르게 하는 skip connection을 지녔다.
여기서 얻을 수 있는 직관은 네트워크의 다운샘플링 부분에서 뒤에 있는 레이어를 지닌 모델일수록 점점 더 이미지가 무엇인지를 포착하고 어디에 있는 것인지는 잃게 된다는 것이다.
U의 정점에서, feature map은 그것이 어디에 있는지 거의 이해하지 못한 채, 이미지에 무엇이 있는지를 문맥적으로 이해하게 될 것이다.
예측 분류 모델의 경우, 우리가 요구하는 것은 이것뿐이므로, 우리는 이것을 최종 Dense layer에 연결하여 이미지에 특정 클래스가 존재할 확률을 출력할 수 있다.
하지만 원래 U-Net application(image segmentation)과 style transfer에서는 원래 이미지 사이즈로 되돌아가는 upsampling을 할 때,
downsampling 동안 잃어버린 공간 정보를 각 레이어에 다시 제공한다. 이것이 skip connection이 필요한 이유이다.
skip connection은 네트워크가 다운샘플링 프로세스 간에 포착된 고도의 추상적 정보(즉, 이미지 스타일)를 네트워크의 이전 계층에서 다시 공급되고 있는 특정한 공간 정보(즉, 이미지 콘텐츠)와
혼합할 수 있도록 한다.
skip connection을 구축하려면 새로운 층인 ‘Concatenate’를 도입해야 한다.
Concatenate Layer
Concatenate layer는 특정 축(기본은 마지막 축)을 기준으로 이어붙이는 것을 말한다. 예를 들어, Keras에서는 2개의 이전 레이어, x와 y를 다음과 같이 이어붙일 수 있다.
Concatenate()([x,y])
U-Net에서는 Concatenate layer를 사용해서 upsampling layer를 동일한 사이즈의 downsampling layer에 연결한다. layer들이 채널의 차원에 따라 이어지기 때문에 채널의 개수는 k에서 2k로 두 배가 된다. 공간의 차원 수는 동일하게 유지된다. 여기서 concatenate layer는 단지 이전 레이어들을 붙이는 역할을 하니 그렇게 신경쓸 필요는 없다.
Instance Normalization Layer
generator는 또다른 새로운 유형의 레이어를 가지는데 그것이 InstanceNormalization 이다. 이 CycleGAN의 generator는 BatchNormalization layer가 아닌 InstanceNormalization layer를 사용하는데, 이는 style transfer 문제에서 더 만족스러운 결과를 만들 수 있다.
InstanceNormalization layer는 배치 단위가 아니라 개별 샘플을 각각 정규화한다. 특히 mu와 sigma를 패러미터로 필요하지 않는데 이는 테스트할 때도 훈련과 동일한 방식으로 샘플마다 정규화를 할 수 있기 때문이다. 단 각 레이어를 정규화하기 위해 사용되는 평균과 표준 편차는 채널별로 나누어 샘플별로 계산된다. (반면 BatchNormalization 레이어는 이동 평균을 위해 훈련과정에서 mu와 sigma가 필요하다)
또한 InstanceNormalization layer에는 스케일(gamma)이나 이동(beta) 패러미터를 사용하지 않기 때문에 학습되는 가중치가 없다.
다음 figure 5-7은 4개의 다른 정규화를 보여준다.
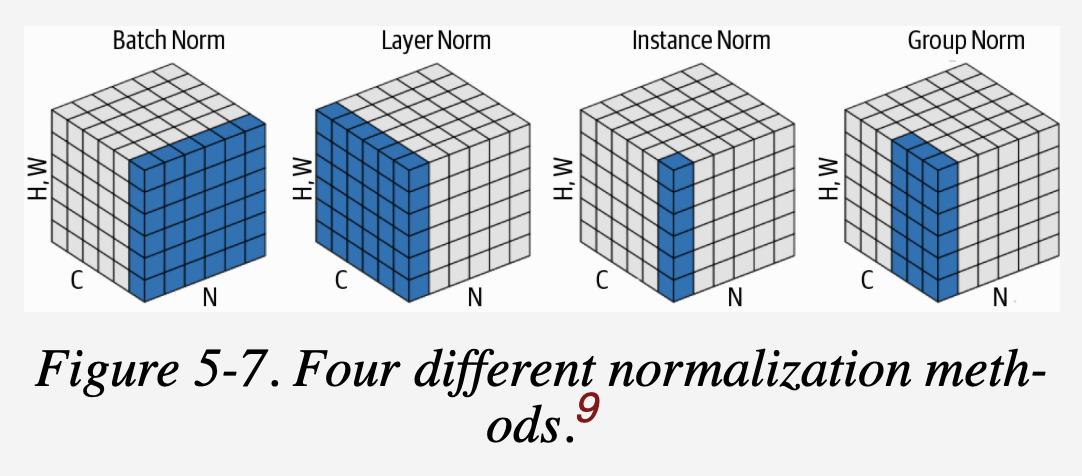
- 여기에서 N은 배치 축이고, C는 채널 축이다. (H,W)는 공간 축을 나타낸다.
- 이 정육면체는 정규화 레이어의 입력 tensor를 나타낸다.
- 파란색의 픽셀은 (이 픽셀에서 계산된) 동일한 평균과 분산으로 정규화된다.
U-Net generator를 만들어 볼 차례이다.
Example 5-2. Building the U-Net Generator
def build_generator_unet(self):
def downsample(layer_input, filters, f_size=4):
d = Conv2D(filters, kernel_size=f_size,
strides=2, padding='same')(layer_input)
d = InstanceNormalization(axis=-1, center=False, scale=False)(d)
d = Activation('relu')(d)
return d
def upsample(layer_input, skip_input, filters, f_size=4, drop_rate=0):
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same')(u)
u = InstanceNormalization(axis=-1, center=False, scale=False)(u)
u = Activation('relu')(u)
if dropout_rate:
u = Dropout(dropout_rate)(u)
u = Concatenate()([u, skip_input])
return u
# image input
img = Input(shape=self.img_shape)
# downsampling
# generator는 두 부분으로 나뉜다.
# 먼저 strides가 2인 Conv2D 레이어로 이미지를 downsampling한다
d1 = downsample(img, self.gen_n_filters)
d2 = downsample(d1, self.gen_n_filters*2)
d3 = downsample(d2, self.gen_n_filters*4)
d4 = downsample(d3, self.gen_n_filters*8)
# Upsampling
# 그 다음 tensor를 upsampling하여 원본 이미지와 같은 크기로 복원
# upsample 함수에는 U-Net 구조를 구성하기 위해 Concatenate layer를 포함한다.
u1 = upsample(d4, d3, self.gen_n_filters*4)
u2 = upsample(u1, d2, self.gen_n_filters*2)
u3 = upsample(u2, d1, self.gen_n_filters)
u4 = UpSampling2D(size=2)(u3)
output = Conv2D(self.channels, kernel_size=4, strides=1,padding='same', activation='tanh')(u4)
return Model(img, output)
The Discriminators
기존의 discriminator는 입력 이미지가 진짜인지 아닌지를 판별하는 하나의 숫자를 출력했었다. 반면 CycleGAN의 discriminator 는 숫자가 아니라 16 * 16 크기의 채널 하나를 가진 텐서를 출력한다.
이는 CycleGAN이 PatchGAN의 discriminator 구조를 이었기 때문이다. PatchGAN의 discriminator 는 이미지 전체에 대해 예측하는 것이 아니라 중첩된 patch로 나누어 각 패치가 진짜인지 아닌지를 추측한다. 따라서 그 output이 하나의 숫자가 아니라 각 패치에 대한 예측 확률을 담은 텐서가 되는 것이다.
네크워크에 이미지를 전달하면 패치들을 한꺼번에 예측한다. 이미지를 수동으로 나누어 전달할 필요없다. discriminator가 합성곱(convolution) 구조를 가지고 있어서 자동으로 이미지가 패치로 나뉜다.
PatchGAN의 장점은 스타일을 기반(내용이 아니라)으로 한 discriminator의 판별 능력을 손실함수가 측정할 수 있다는 점이다. discriminator 예측의 개별 원소는 이미지의 부분에 기반하기에 내용이 아니라 스타일을 사용하여 결정하는 것이다.
Example 5-3. Building the discriminators
def build_discriminator(self):
def conv4(layer_input, filters, stride=2, norm=True):
y = Conv2D(filters, kernel_size=4, strides=stride,
padding='same')(layer_input)
if norm:
y = InstanceNormalization(axis=-1, center=False, scale=False)(y)
y = LeakyReLU(0.2)(y)
return y
img = Input(shape=self.img_shape)
# CycleGAN의 discriminator는 연속된 convolution neural net이다.
# 처음 레이어를 제외하고 모두 샘플 정규화를 사용한다.
y = conv4(img, self.disc_n_filters, strid=2, norm=False) # 128 * 128
y = conv4(y, self.disc_n_filters*2, strid=2) # 64 * 64
y = conv4(y, self.disc_n_filters*4, strid=2) # 32 * 32
y = conv4(y, self.disc_n_filters*8, strid=1) # 16 * 16
# 마지막 conv layer에는 하나의 필터만 사용하고, 활성화 함수는 적용하지 않는다.
# strides가 1이고 padding을 same으로 줬기 때문에 이미지 크기는 변경없다.
# 채널이 1개
output = Conv2D(1, kernel_size=4, strids=1, padding='same')(y) # 16 * 16 * 1
return Model(img, output)
Compiling the CycleGAN
목적은 도메인 A의 이미지를 도메인 B의 이미지로 혹은 그 반대로 바꾸는 모델들을 학습시키는 것이다. 다음이 그 4개의 모델이다.
- g_AB : 도메인 A의 이미지를 도메인 B의 이미지로 바꾸는 것을 학습
- g_BA : 도메인 B의 이미지를 도메인 A의 이미지로 바꾸는 것을 학습
- d_A : 도메인 A의 진짜 이미지와 g_BA가 생성한 가짜 이미지의 차이를 학습
- d_B : 도메인 B의 진짜 이미지와 g_AB가 생성한 가짜 이미지의 차이를 학습
입력(각 도메인의 이미지)와 출력(binary, 진짜면 1, 가짜면 0)이 있으므로 바로 두 discriminators를 컴파일할 수 있다.
Example 5-4 Compiling the discriminator
self.d_A = self.build_discriminator()
self.d_B = self.build_discriminator()
# loss function : Mean Squared Estimation
# optimizer : Adam Optimizer
# metrics : accuracy
self.d_A.compile(loss='mse',
optimizer=Adam(self.learning_rate, 0.5),
metrics=['accuracy'])
self.d_B.compile(loss='mse',
optimizer=Adam(self.learning_rate, 0.5),
metrics=['accuracy'])
반면에 생성자는 쌍을 이루는 이미지 데이터셋이 없기 때문에 바로 컴파일할 수 없다. 대신 다음 세가지 조건으로 생성자를 평가한다.
- 유효성(Validity) - 각 생성자에에서 만든 이미지가 대응되는 판별자를 속일 수 있는가
(예를들어, g_AB의 출력이 d_A를 속이고 g_BA의 출력이 d_B를 속이는가 ) - 재구성(Reconstruction) - 두 생성자를 교대로 사용하면 (양방향 모두에서) 원본 이미지를 얻을 수 있는가?
(CycleGAN은 cyclic reconstruction 조건으로부터 이름을 따왔다.) - 동일성(Identity) - 각 생성자를 자신의 타겟 도메인에 있는 이미지에 적용했을 때 이미지가 바뀌지 않고 그대로 남아있는가?
Example 5-5 Building the combined model to train the generators
self.g_AB = self.build_generator_unet()
self.g_BA = self.build_generator_unet()
# For the combined model we will only train the generators
self.d_A.trainable = False
self.d_B.trainable = False
# Input images from both domains
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
# 각 이미지를 다른 도메인 이미지로 변환한 가짜이미지를 만든다.
fake_B = self.g_AB(img_A)
fake_A = self.g_BA(img_B)
# (1. 유효성)Discriminators determines validity of translated images
valid_A = self.d_A(fake_A)
valid_B = self.d_B(fake_B)
# (2. 재구성)가짜이미지를 원래 도메인의 이미지로 변환한다.
reconstr_A = self.g_BA(fake_B)
reconstr_B = self.g_AB(fake_A)
# (3. 동일성)Identity mapping of images
img_A_id = self.g_BA(img_A)
img_B_id = self.g_AB(img_B)
# Combined model trains generators to fool discriminators
self.combined = Model(inputs=[img_A, img_B],
outputs=[valid_A, valid_B,
reconstr_A, reconstr_B,
img_A_id, img_B_id])
self.combined.compile(loss=['mse', 'mse',
'mae', 'mae',
'mae', 'mae'],
loss_weights=[self.lambda_validation, self.lambda_validation,
self.lambda_reconstr, self.lambda_reconstr,
self.lambda_id, self.lambda_id],
optimizer=Adam(0.0002, 0.5))
결합 모델은 각 도메인의 이미지를 배치로 배치로 받고, 각 도메인에 대해 3개 조건에 맞추어 3개의 출력을 반환한다. 즉, 총 6개의 출력값이 나온다. GAN의 일반적인 형태처럼 생성자 학습 시에는 판별자의 가중치는 고정한다.
전체 손실은 각 조건에 대한 손실의 가중치 합이다. mse(평균 제곱 오차)는 유효성 조건에 사용된다. 진짜와 가짜 타겟에 대해 판별자의 출력을 확인한다. mae(평균 절댓값 오차)는 이미지 대 이미지 조건에 사용된다(재구성과 동일성 조)
Training the CycleGAN
discriminator와 generator(여기선 combined model)를 교대로 훈련하는 GAN의 학습 방식을 따른다.
Example 5-6 Training the CycleGAN
batch_size = 1
patch = int(self.img_rows / 2**4 )
self.disc_patch = (patch, patch, 1)
# 진짜 이미지에 대해서는 1, 생성된 이미지에 대해서는 0
# PatchGAN의 discriminator를 사용하기 때문에 패치마다 하나의 타켓을 설정한다.
valid = np.ones((batch_size,) + self.disc_patch)
fake = np.ones((batch_size,) + self.disc_patch)
for epoch in range(self.epoch, epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(data_loader.load_batch(batch_size)):
# discriminator 학습을 위해서 생성자로 일단 가짜 이미지 배치를 만든다.
# 일반적으로 CycleGAN의 배치 크기는 1(하나의 이미지)이다.
fake_B = self.g_AB.predict(imgs_A)
fake_A = self.g_BA.predict(imgs_B)
dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
d_loss = 0.5 * np.add(dA_loss, dB_loss)
# generator는 앞서 컴파일한 결합 모델을 통해 동시에 학습한다.
# 6개의 출력은 컴파일 단계에서 정의한 6개의 손실 함수에 대응된다.
g_loss = self.combined.train_on_batch([imgs_A, imgs_B],
[valid, valid,
imgs_A, imgs_B,
imgs_A, imgs_B)
Analysis of the CycleGAN
loss function의 가중치 패러미터를 조정하면서 CycleGAN의 결과가 어떻게 바뀌는지 살펴보는 것도 좋다.
figure 5-8은 figure 5-3에서 보여준 CycleGAN의 결과를 위의 3가지 조건으로 표현한 것이다.
생성자가 입력 이미지를 다른 도메인의 이미지로 잘 변환했기 때문에 성공적으로 학습했다. 생성자가 교대로 적용될 때 입력 이미지와 재구성 이미지의 차이가 작아보인다. 마지막으로 각 생성자는 자신의 타겟 도메인의 이미지를 적용했을 때 이 이미지를 크게 바꾸지 않는다.

신기한 것은 이 CycleGAN의 원논문에는 3번째 조건(동일성)은 옵션이고, 1,2번째 조건은 필수라고 했는데 아래 figure 5-9를 보면 3번째 조건도 하는게 좋다는 생각이 든다.

오렌지를 사과로 바꿀 수 있지만 선반의 색이 바뀌었다. 배경색의 변환을 막아주는 동일성 손실 항이 없어서이다. 동일성 항은 이미지에서 변환에 필요한 부분 이외에는 바꾸지 않도록 생성자에게 제한을 가한다.
이 예제는 3개의 loss function 가중치의 균형을 잘 잡는 것이 중요함을 보여준다. 동일성 손실이 너무 작으면 색깔이 바뀌는 문제가 생긴다. 반대로 동일성 손실이 너무 크면 CycleGAN이 입력을 다른 도메인의 이미지처럼 보이도록 바꾸지 못할 것이다.
Creating a CycleGAN to Paint Like Monet
지금까지 CycleGAN의 기본 구조를 살펴보았다. 본 섹션에서는 CycleGAN을 이용한 재미난 적용 예제를 소개한다.
CycleGAN의 원논문의 성과 중 하나는 모델이 주어진 사진을 특정 아티스트 스타일의 그림으로 변환하는 방법을 학습하는 것이다.
여기서는 미술 작품을 실제 사진으로 바꾸는 것을 해볼 것이고 모네의 작품을 이용할 것이다. 아래는 모네-사진 데이터셋 다운로드 스크립트이다.
(기존에 파일이 있어야 한다.)
bash ./script/download_cyclegan_data.sh monet2photo
그리고 다음 예제와 같은 패러미터를 쓰는 모델을 만든다.
Example 5-7. define the Monet CycleGAN
gan = CycleGAN(
input_dim = (256, 256, 3),
learning_rate = 0.0002,
lambda_validation = 1,
lambda_reconstr = 10,
lambda_id = 5,
generator_type = 'resnet',
gen_n_filters = 32,
disc_n_filters = 64
)
The Generator (ResNet)
이 섹션에서는 잔차 네트워크(Residual Network) 혹은 ResNet이라 불리는 새로운 생성자 구조를 소개한다. ResNet은 이전 레이어의 정보를 네트워크 앞쪽에 있는 한 개 이상의 레이어로 skip한다는 점에서 U-Net과 유사하다. 하지만 네트워크를 downsampling layer과 그에 상응하는 upsampling layer로 만든 U자 모양으로 구성하는 대신에 ResNet은 잔차 블록(residual block)을 차례대로 쌓아 구성한다. 각 블록은 다음 층으로 출력을 전달하기 전에 입력과 출력을 합하는 skip connection을 가지고 있다. figure 5-10에 하나의 잔차 블록이 있다.
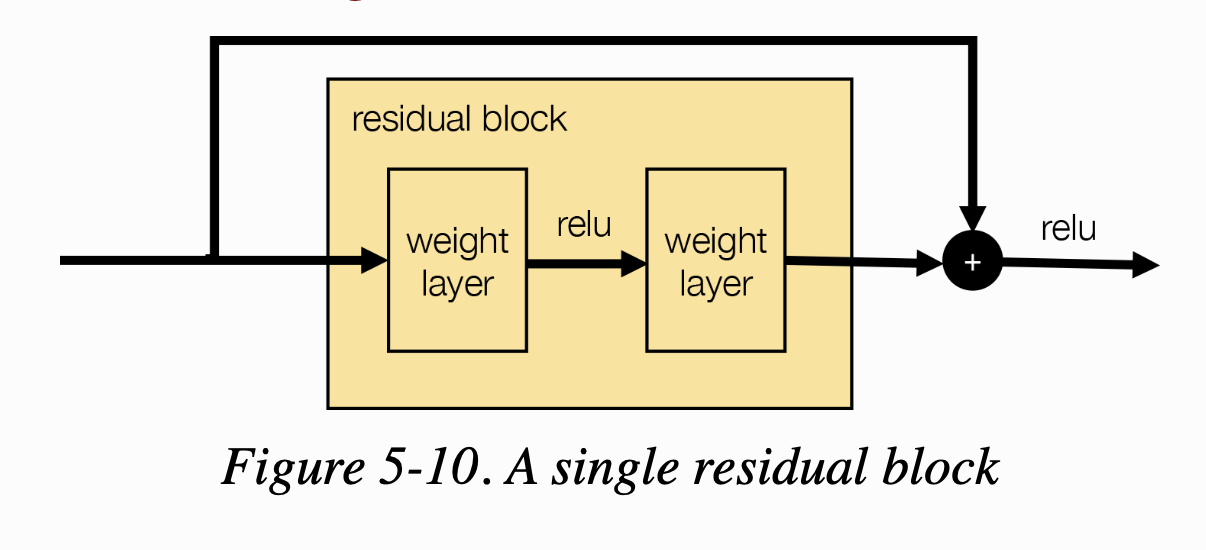
- weight layer는 CycleGAN의 샘플 정규화를 사용한 합성곱 층이다.
아래 예제 코드는 잔차블록을 만드는 코드이다.
Example 5-8. A residual block in Keras
from keras.layers.merge import add
def residual(layer_input, filters):
shortcut = layer_input
y = Conv2D(filters, kernel_size=(3,3), strides=1, padding='same')(layer_input)
y = InstanceNormalization(axis=-1, center=False, scale=False)(y)
y = Activation('relu')(y)
y = Conv2D(filters, kernel_size=(3,3), strides=1, padding='same')(y)
y = InstanceNormalization(axis=-1, center=False, scale=False)(y)
return add([shortcut, y])
ResNet 생성자는 잔차 블록의 양쪽에 다운샘플링과 업샘플링 층이 있다. 전체 ResNet 구조는 figure 5-11과 같다.
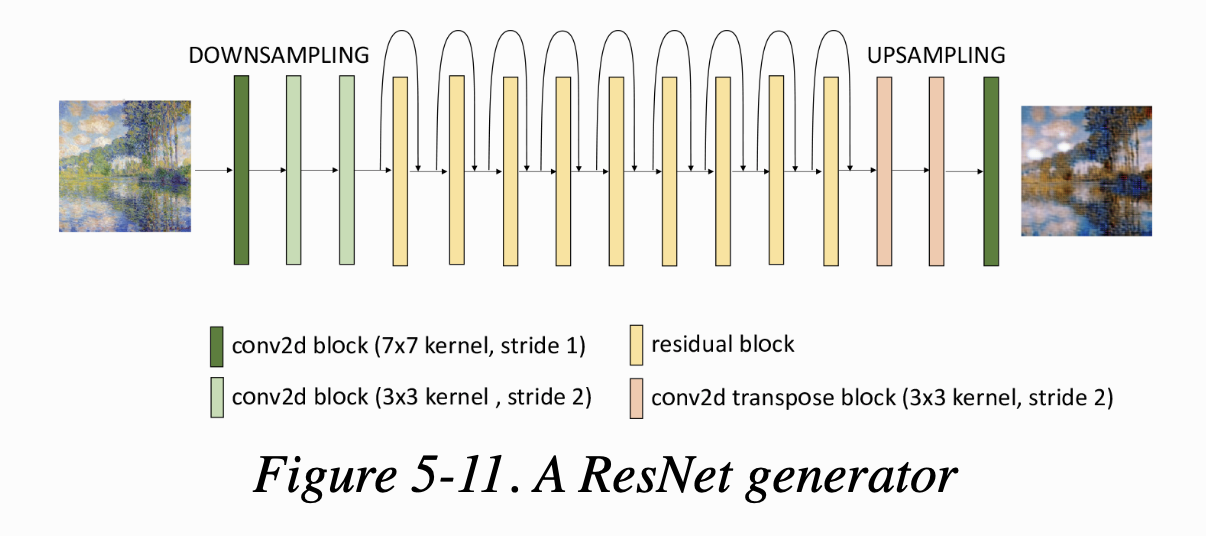
ResNet 구조는 수백 또는 수천 개의 층도 훈련할 수 있다고 알려져 있다. 앞쪽으로 갈수록 gradient가 줄어드는 vanishing gradient 문제가 없기 때문이다. error gradient가 잔차 블록의 skip connection을 통해 네트워크에 그대로 역전파(backpropagation)되기 때문이다. 또한 층을 추가해도 모델의 정확도를 떨어뜨리지 않는다. 추가적인 특성이 추출되지 않는다며 skip connection으로 인해 언제든지 이전 층의 특성이 identity mapping을 통과하기 때문이다.
- identity mapping
- 기본 ResNet 구조는 skip connection 과 더해진 후 ReLU 함수를 통과시킨다. 이 CycleGAN의 잔차블록은 skip connection 을 합친 후에 적용하는 활성화 함수가 없어서 이전 층의 feature map이 그대로 다음 층으로 전달된다. 이를 identity mapping 이라고 한다.
Analysis of the CycleGAN
CycleGAN 원논문에서는 그림-사진 style transfer를 최고의 상태로 올리기 위해 학습 기간으로 200 epoch을 제안했다. figure 5-12는 학습 과정 초기 단계에서 생성자의 출력이다. 모델이 모네 그림을 사진으로 변환하는 것과 그 반대로 변환하는 것을 배우는 과정이다.

첫 번째 줄에서는 사진에 모네가 사용한 특유의 색깔과 붓질이 점차 드러나는 모습이 보인다. 색은 자연스럽고 경계선은 부드럽게 변하고 있다. 두 번째 줄에서는 반대로 그림이 사진으로 변환하는 방법을 생성자가 배운다.
figure 5-13은 200번 epoch을 돌린 모델이 만든 결과이다.

Neural Style Transfer
Neural Style Transfer는 다른 종류의 style transfer이다. 훈련 셋을 사용하지 않고 이미지의 스타일을 다른 이미지로 전달한다. figure 5-14가 그 예이다.

Neural Style Transfer는 3가지 손실 함수의 가중치 합을 기반으로 작동한다.
- Content loss
- 합성된 이미지는 베이스 이미지의 콘텐츠를 동일하게 포함해야 한다.
- Style loss
- 합성된 이미지는 스타일 이미지와 동일한 일반적인 스타일을 가져야 한다.
- Total variance loss
- 합성된 이미지는 픽셀처럼 격자 무늬가 나타나지 않고 부드러워야 한다.
gradient descent 로 이 손실을 최소화한다. 즉 많은 반복을 통해 손실 함수의 nagative gradient 양에 비례하여 픽셀값을 업데이트한다. 반복할수록 손실은 점차 줄어들어 베이스 이미지의 콘텐츠와 스타일 이미지를 합친 합성 이미지를 얻게 될 것이다.
gradient descent 로 출력을 최적화하는 것은 지금까지 다루었던 생성 모델링 문제와는 다르다.
이전에는 VAE나 GAN 같은 뉴럴넷을 훈련하기 위해 오차를 전체 네트워크에 역전파시켰었다.
이를 통해 훈련 셋에서 학습한 정보를 일반화하여 새로운 이미지를 생성했다.
여기에서는 베이스 이미지와 스타일 이미지 두 개만 가지고 있기에 이 방식을 사용할 수 없다. 앞으로 다루겠지만 사전 학습된 뉴럴넷을 사용해
손실 함수에 필요한 이미지에 관한 중요한 정보를 얻을 것이다.
먼저 각각의 손실 함수에 대해 알아보도록 하겠다. 이 함수들이 neural style transfer 엔진의 핵심이다.
Content Loss
content loss는 콘텐츠의 내용과 전반적인 사물의 배치 측면에서 두 이미지가 얼마나 다른지를 측정한다. 비슷한 장면(예를 들면, 건물의 한 사진과 다른 각도, 다른 빛으로 찍은 같은 건물의 다른 사진)을 담은 두 이미지는 완전히 다른 장면을 포함하는 두 이미지보다 손실이 작아야 한다. 두 이미지의 픽셀값을 비교하는 것만으로는 부족하다. 두 이미지의 장면이 같더라도 개별 픽셀값이 비슷하다고 보장하지 않기 때문이다. content loss는 개별 픽셀값과 무관해야 한다. 건물, 하늘, 강 같은 고차원 특성의 존재와 대략적인 위치를 기반으로 이미지를 점수화해야 한다.
이런 개념은 딥러닝에 있어 친숙하다. 왜냐면 이미지의 내용을 인식하도록 훈련된 신경망은 이전 층의 단순한 특성을 결합해서 더 깊은 층으로 갈수록 더 높은 수준의 특성을 학습하기 때문이다. 딥러닝의 전제라고도 볼 수 있다. 따라서 이미지의 내용을 식별하도록 성공적으로 훈련된 심층신경망이 필요하다. 네트워크의 깊은 층을 활용하여 주어진 입력 이미지의 고차원 특성을 추출할 수 있다. 베이스 이미지와 현재 합성된 이미지에 대해 이 출력을 계산하여 그 출력 사이의 평균제곱오차를 측정하면 content loss function이 된다.
여기서 사용한 사전학습된 네트워크는 VGG19이다. ImageNet dataset에 있는 백만 개 이상의 이미지를 천 개 이상의 범주로 분류하도록 훈련된 19개 층을 가진 CNN이다. figure 5-15가 VGG19 네트워크 구조이다.
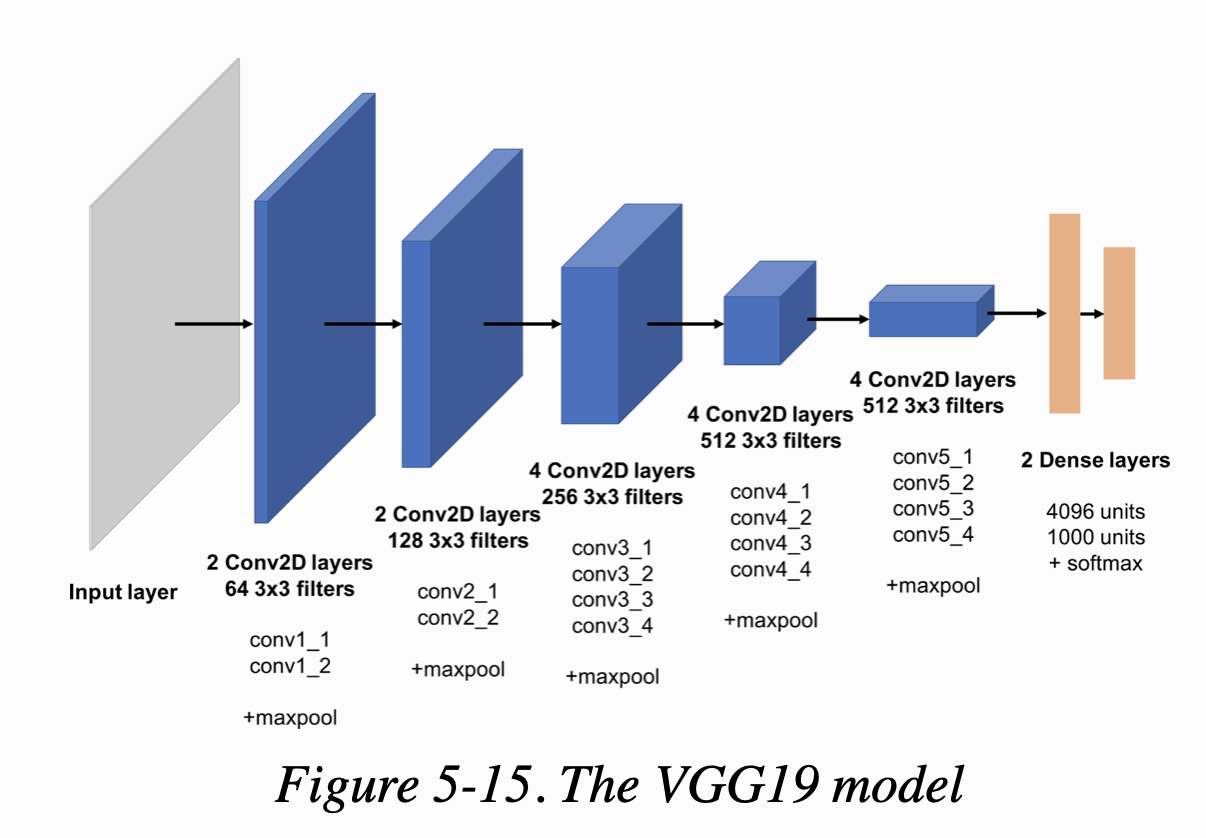
예제 5-9는 두 이미지 사이의 content loss를 계산하는 코드이다. 이는 공식 케라스 저장소(https://github.com/keras-team/keras/blob/master/examples/neural_style_transfer.py)의 neural style transfer 예제를 참조한 것이다.
Example 5-9. The content loss function
from keras.applications import vgg19
from keras import backend as K
base_image_path = '/path_to_images/base_image.jpg'
style_reference_image_path = '/path_to_images/styled_image.jpg'
content_weight = 0.01
# base image와 스타일 이미지를 위한 두 개의 케라스 변수와 생성된 합성 이미지를 담을 placeholder를 정의한다.
base_image = K.variable(preprocess_image(base_image_path))
style_reference_image = K.variable(preprocess_image(style_reference_image_path))
combination_image = K.placeholder((1, img_nrows, img_ncols, 3))
# 세 이미지를 연결하여 VGG10 모델의 입력 텐서를 만든다.
input_tensor = K.concatenate([base_image,
style_reference_image,
combination_image], axis=0)
# 입력 텐서와 사용할 가중치를 지정하여 VGG19 모델의 객체를 만든다.
# include_top 매개변수는 이미지 분류를 위한 네트워크의 마지막 fully connected layer의 가중치를 사용하는지 정하는 것이고
# 여기서는 사용하지 않는다. 여기서 관심있는 것은 입력 이미지에 대한 고 차원 특성을 감지하는 합성곱 층이기 때문이다.
# 훈련된 원본 모델이 만드는 실제 확률에는 관심이 없다.
model = vgg19.VGG19(input_tensor=input_tensor,
weights='imagenet', include_top=False)
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
# content loss를 계산하기 위해 사용한 층은 다섯번째 블록의 두 번째 합성곱 층이다.
# 네트워크에서 더 낮은 층이나 더 깊은 층을 선택하면 손실함수가 정의하는 콘텐츠에 영향을 미친다.
# 그러므로 생성된 합성 이미지의 성질이 바뀐다.
layer_features = outputs_dict['block5_conv2']
# VGG19 네트워크에 주입된 입력 텐서에서 베이스 이미지 특성과 합성 이미지의 특성을 추출한다.
# 각각 첫번째, 세번째이다.
base_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
def content_loss(content, gen):
return K.sum(K.square(gen - content))
# 두 이미지에 대한 레이어의 출력 간에 거리 제곱 합을 계산하고 가중치 패러미터를 곱하여
# content loss 를 얻는다.
content_loss = content_weight * content_loss(base_image_features,
combination_features)
Style Loss
어떻게 두 이미지 사이의 스타일 유사도를 측정할 수 있을까?
Neural style transfer 원논문에서 제시한 해결책은 다음과 같은 가정을 기반으로 한다.
스타일이 비슷한 이미지는 특정 레이어의 특성 맵 사이에 동일한 상관관계(correlation) 패턴을 가진다.
예를 들어 설명해보면, VGG19 네트워크의 어떤 레이어에서 한 채널은 녹색 부분을 감지하고 다른 채널은 뾰족함을 감지하고 또 다른 채널은 갈색 부분을 감지한다고 가정해보자.
figure 5-16이 3개의 입력에 대한 채널의 출력(feature map)을 나타낸다
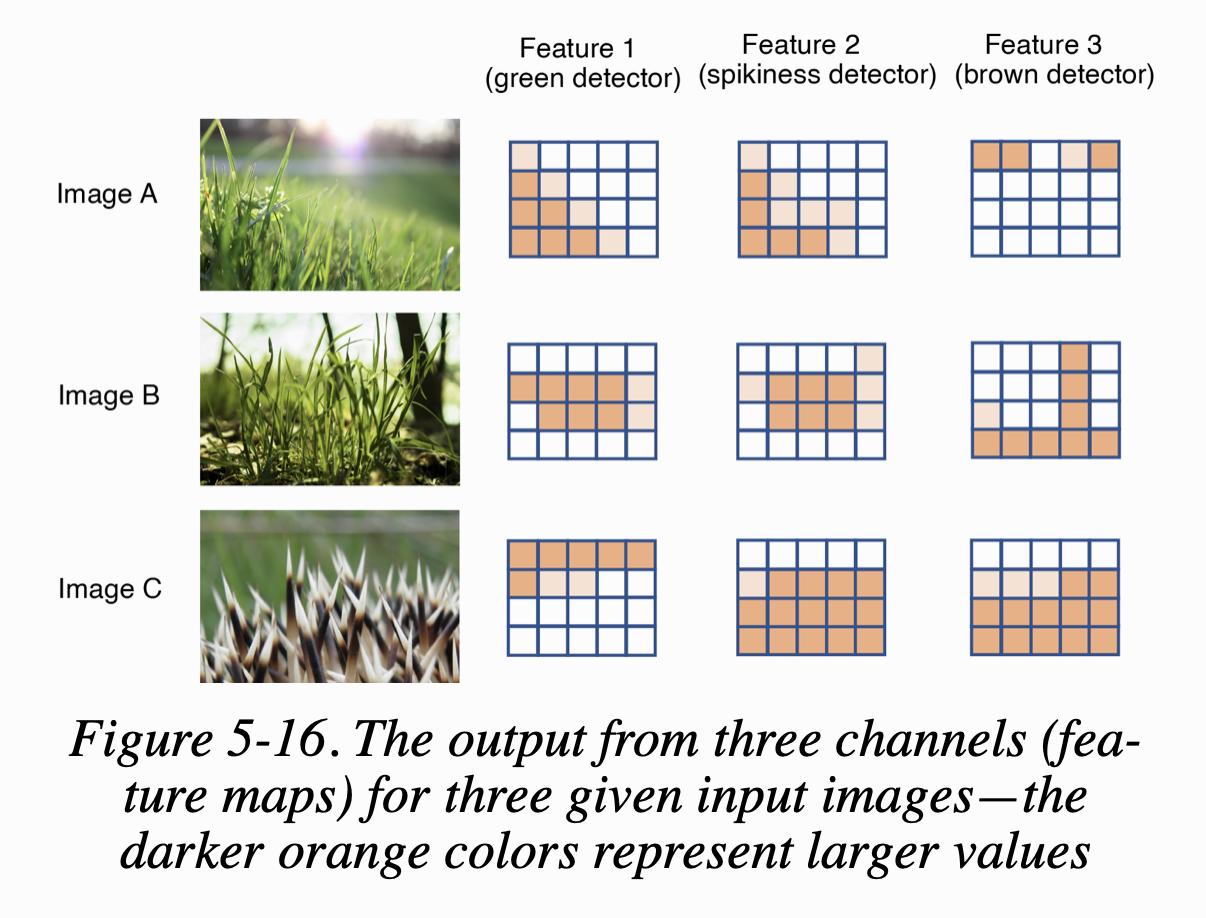
이미지 A와 B의 스타일이 비슷하게 보인다. 둘 다 풀이 전경을 채운다. 또한 feature map에서 녹색 채널과 뾰족함 채널이 유사한 위치에서 강하게 활성화되고 있다. 반면, C는 그렇지 않다. C는 갈색과 뾰족함 채널이 동일한 영역에서 활성화되고 있다. 두 개의 feature map이 얼마나 동시에 활성화되는지를 수치적으로 측정하려면 feature map을 펼치고 내적(scalar product, dot product)을 계산하면 된다. (내적은 두 벡터 간 동일 위치의 값을 곱한 후 모두 더하면 된다) 그 값이 크면 feature map 사이의 상관관계가 큰 것이고 작으면 상관관계가 작은 것이다.
레이어에 있는 모든 feature 사이의 내적을 담은 행렬을 정의할 수 있다. 이를 gram matrix라고 한다. figure 5-17은 각 이미지에 대한 3개의 feature 사이의 내적을 gram matrix로 보여준다.
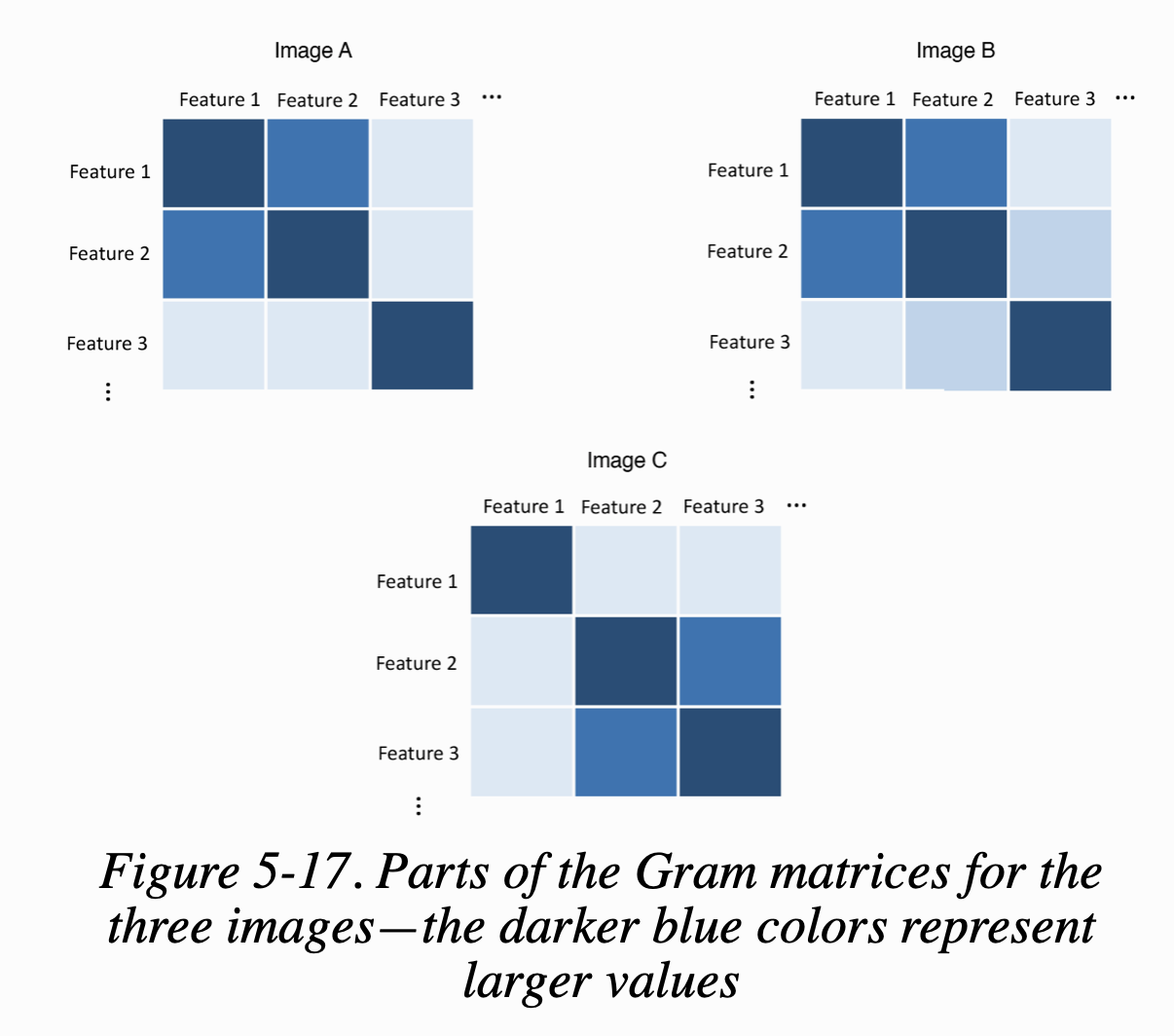
스타일이 비슷한 이미지 A와 B가 비슷한 gram matrix를 가진다. 콘텐츠는 다르더라도 gram matrix는 비슷할 수 있다. 따라서 style loss를 계산하려면 베이스 이미지와 합성된 이미지에 대한 네트워크의 여러 층에서 gram matrix를 계산해야 한다. 그 다음 두 gram matrix의 제곱 오차 합(sum of squared errors)을 사용하여 유사도를 비교한다. 베이스 이미지(S)와 생성된 이미지(G) 사이의 style loss는 크기가 \(M_l\) (높이 * 너비)이고 \(N_l\) 개의 채널을 가진 레이어(l)을 이용해 다음과 같은 수식으로 쓸 수 있다.
\[L_{GM}(S, G, l) = \frac{1}{4N_l^2M_l^2} \displaystyle\sum_{ij} (GM[l](S)_{ij} - GM[l](G)_{ij})^2\]이 두 이미지의 전체 style loss는 크기가 다른 여러 층에서 계산한 style의 가중치 합이다. 채널의 수(\(N_l\))와 층의 크기(\(M_l\))로 스케일을 조정해 다음과 같이 계산한다.
\[L_{style}(S,G) = \displaystyle\sum_{l=0}^{L} w_lL_{GM}(S,G,l)\]example 5-10은 style loss를 계산하는 케라스 코드이다.
Example 5-10. Style loss function
style_loss = 0.0
def gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram = K.dot(features, K.transpose(features))
return gram
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_nrows * img_ncols
return K.sum(K.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# 5개의 층에서 style loss를 계산한다. VGG19 모델의 5개 블록에 있는 첫번째 합성곱 층
feature_layers = ['block1_conv1', 'block2_conv1',
'block3_conv1', 'block4_conv1',
'block5_conv1']
for layer_name in feature_layers:
layer_features = outputs_dict[layer_name]
# VGG19 네트워크로 주입된 입력 텐서에서 style image의 feature map과 합성된 이미지의 feature map을 추출한다.
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features)
# 가중치 패러미터와 계산에 참여한 층의 개수로 style loss의 스케일을 조정한다.
style_loss += (style_weight / len(feature_layers)) * sl
Total Variance Loss
Total variance loss는 합성된 이미지의 노이즈를 측정한 것이다. 이미지의 노이즈를 측정하기 위해 오른쪽으로 한 픽셀을 이동하고 원본 이미지와 이동한 이미지 간의 차이를 제곱하여 더한다. 균형을 맞추기 위해 동일한 작업을 한 픽셀 아래로 이동하여 수행한다. 이 두 항의 합이 Total Variance Loss 이다.
example 5-11은 Total Variance Loss를 계산하는 케라스 코드이다.
Example 5-11. The variance loss function
def total_variation_loss(x):
# 한 픽셀 아래로 이동한 후 차이를 계산하여 제곱
a = K.square(
x[:, :img_nrows - 1, :img_ncols - 1, :] - x[:, 1:, :img_ncols -1, :]
)
# 한 픽셀 오른쪽으로 이동한 후 차이를 계산하여 제곱
b = K.square(
x[:, :img_nrows - 1, :img_ncols - 1, :] - x[:, :img_nrows - 1, 1:, :]
)
return K.sum(K.pow(a+b, 1.25))
# 가중치를 곱해서 total variation loss를 계산한다.
tv_loss = total_variation_weight * total_variation_loss(combination_image)
# 전체 loss는 content loss, style loss, total variation loss를 합하여 계산한다.
loss = content_loss + style_loss + tv_loss
Running the Neural Style Transfer
학습 과정은 손실함수를 최소화하기 위해, 합성된 이미지의 각 픽셀에 대해 경사하강법을 실행하는 것이다. 전체 코드(neural_style_transfer.py) 중 example 5-12는 훈련 반복 부분을 보여준다.
Example 5-12. The training loop for the neural style transfer model
from scipy.optimize import fmin_l_bfgs_b
iterations = 1000
# 베이스 이미지로 합성된 이미지를 초기화한다.
x = preprocess_image(base_image_path)
for i in range(iterations):
# 매 반복마다 현재 합성된 이미지를 (일렬로 펼쳐서) scipy.optimize 패키지의 fmin_l_bfgs_b 최적화 함수로 전달한다.
# 이 함수는 L-BFGS-B 알고리즘을 사용하여 경사하강법의 한 스텝을 수행한다.
x, min_val, info = fmin_l_bfgs_b(
# 여기에서 evaluator는 앞서 언급한 전체 손실과 입력 이미지에 대한
# 손실의 gradient(기울기)를 계산하기 위한 메서들 가진 객체이다.
evaluator.loss,
x.flatten(),
fprime=evaluator.grads,
maxfun=20
)
Analysis of the Neural Style Transfer Model
Figure 5-18은 다음과 같은 패러미터로 neural style transfer를 학습하는 과정에서 만든 3개의 출력이다.
- content_weight : 1
- style_weight : 100
- total_variance_weight : 20

반복 스텝이 많아질수록 베이스 이미지를 점점 스타일 이미지의 스타일을 따라 만들고 있다. 그러면서도 베이스 이미지의 전체적인 컨텐츠 구조는 유지하고 세세한 것들을 바꾸고 있다.
이 구조로 다양한 실험을 할 수 있다. 손실 함수의 가중치 패러미터나 콘텐츠 유사도를 결정하는데 사용할 레이어를 바꿀 수 있다. 이런 변화가 합성 이미지와 훈련 속도에 어떻게 영향을 미치는지 확인해볼 수 있다. 스타일 손실 함수에 있는 각 층에 부여된 가중치를 줄여서 더 미세한 스타일이나 좀 더 큰 스타일 특성을 따르도록 조정할 수도 있다.
Summary
- 이 장에서는 새로운 그림을 생성하는 방법인 CycleGAN과 Neural style transfer를 살펴보았다
- CycleGAN으로 모델을 훈련하여 미술가의 일반적인 스타일을 학습하고 사진에 이를 적용해보았다.
- 이는 미술가가 사진에 있는 장면을 그린 것과 같은 출력을 보여준다.
- 이 모델은 사진-> 그림도 가능하지만 그 반대도 가능하다.
- CycleGAN에서는 각 도메인의 이미지 쌍이 필요하지 않아서 매우 강력하고 유연하다는 장점을 지닌다.
- Neural style transfer를 사용하면 한 이미지의 스타일을 베이스 이미지로 적용할 수 있다.
- 3개의 손실 함수를 사용하여 베이스 이미지의 컨텐츠 구조는 바꾸지 않으면서 스타일을 바꿀 수 있다.
- 다음 챕터에서는 이미지 기반의 생성 모델링에서 벗어나 텍스트 기반 생성 모델링에 대해 다뤄보도록 한다.