
Intro
이 글은 Vertex Matching Engine(VME)의 공식 가이드 문서를 보고 정리한 글입니다. 이전 글 에서 VME 에 대한 소개를 했습니다.
이번 글에서는 공식 문서를 보면서 VME의 구체적인 특징과 사용법에 대해 다루도록 하겠습니다.
Two-Tower built-in algorithm
matching engine 은 임베딩이 필요한데 이 임베딩은 사용자가 외부에서 자신의 알고리즘으로 만든 임베딩을 matching engine에 올려서 사용할 수도 있고 VME에서 제공하는 기능도 내장되어 있습니다.
Two-Tower model 은 VME에서 제공하는 임베딩 학습을 위한 내장 솔루션입니다.
- 레이블이 달린 데이터로 임베딩 학습 진행
- 사용자 프로필, 검색 쿼리, 웹문서, 이미지 등 비슷한 유형의 객체를 동일한 벡터 공간에서 짝을 지어서 관련 항목이 가깝게 배치되도록 한다
- two-tower 인 이유는 2개의 인코더 타워를 사용해서다: query tower, candidate tower
- bi-encoder 구조
- 학습을 위한 데이터도 쿼리 문서, 후보 문서 쌍으로 구성
- Two-Tower 모델을 학습시키면 각 query encoder, candidate encoder를 위한 두 개의 TensorFlow SavedModel 반환
- 각 모델은 쿼리 혹은 후보 문서를 임베딩으로 변환시킬 수 있는 모델
- 검색 과정
- 쿼리 주어짐
- matching engine 은 query encoder 사용해서 query embedding 생성하고, 유사한 candidate embeddings 를 찾기 위해 인덱스를 사용한다
- matching engine 은 candidate encoder 를 사용하여 모든 항목을 색인화하고 가장 가깝게 근사한 지점을 제공한다.
입력 데이터
two-tower 는 두 개 입력을 받습니다.
- 학습 데이터: 학습에 사용될 문서 쌍. 두 가지 포맷
- Json lines
- TFRecord
- 입력 스키마: 입력 데이터에 대한 스키마(json file), feature configuration 포함
학습 데이터
- 학습 데이터는 쿼리 문서, 후보 문서 쌍으로 구성됩니다.
- query 문서, candidate 문서는 정답 혹은 일치로 간주되는 positive pair 만 제공하면 됩니다.
- 오답 쌍으로 학습은 지원하지 않는다.
- 문서는 사용자 정의 feature 들로 구성되어 있는데 지원하는 feature type은 다음과 같습니다.
- Text: 문자열
- Id: scalar string, unique ID
- Categorical: 문자열, 입력 스키마에서 지정할 수 있는 내용
- Numeric: a list of floats
- Vector: a fixed-length float vector, 입력
JSON Lines format
{
"query":
{
"movie_genre": ["action"],
},
"candidate":
{
"ratings": [7.3, 6.0, 8.1],
"movie_name": ["mission impossible"]
}
}
query 와 candidate 두 개의 키를 포함하는 사전 형태
TFRecord format
features {
feature {
key: "query_movie_genre"
value {
bytes_list {
value: "action"
}
}
}
feature {
key: "candidate_ratings"
value {
float_list {
value: [7.3, 6.0, 8.1]
}
}
}
feature {
key: "candidate_movie_name"
value {
bytes_list {
value: "mission impossible"
}
}
}
}
query_ 와 candidate_ 두 개의 접두사를 사용하여 문서를 구분합니다.
입력 스키마
- Json file
"query":
{
"movie_genre": {
"feature_type": "Categorical",
"config": {
"vocab": ["action", "comedy", "drama"]
}
}
},
"candidate":
{
"ratings": {
"feature_type": "Numeric"
},
"movie_name": {
"feature_type": "Text",
"config": {
"embedding_module":"gs://my_bucket/my_saved_model"
}
}
}
제가 사용한다면 two-tower model 말고 소속 집단의 모델을 쓸 것이라 예상되어 two-tower model에 대한 설명은 이 정도로 마무리하겠습니다.
추가적으로 colab에서 two-tower model 에 대한 실행 예시를 보실 수 있습니다.
다음에서 본격적으로 matching engine 에 대해 소개하겠습니다.
사전 준비
기본 준비
matching engine 을 사용하기 앞서 사전 준비가 필요합니다.
- 프로젝트 생성 및 결제 계정 등록
- compute engine api, vertex ai api, service networking api 사용 설정
- 네트워크 관리자 역할 필요(프로젝트 소유자나 편집자가 아닌 경우)
- VPC의 비공개 서비스 액세스 설정하려면 서비스 제작자를 위한 IP 범위를 예약한 다음 Vertex AI와 피어링 연결
- 공유 vpc를 사용할 경우 vpc 호스트 프로젝트와 별도의 프로젝트에서 vertex ai를 사용한다
- 두 프로젝트 모두에서 compute engine, service networking api 사용 설정
- On-premise 네트워크와 비공개 연결을 원하면 커스텀 경로 내보내기
VPC(Virtual Private Cloud)
회사에서 가상사설망(VPN)을 많이 쓰는데 VPC는 클라우드 내에서의 가상의 클라우드라고 보면 됩니다.

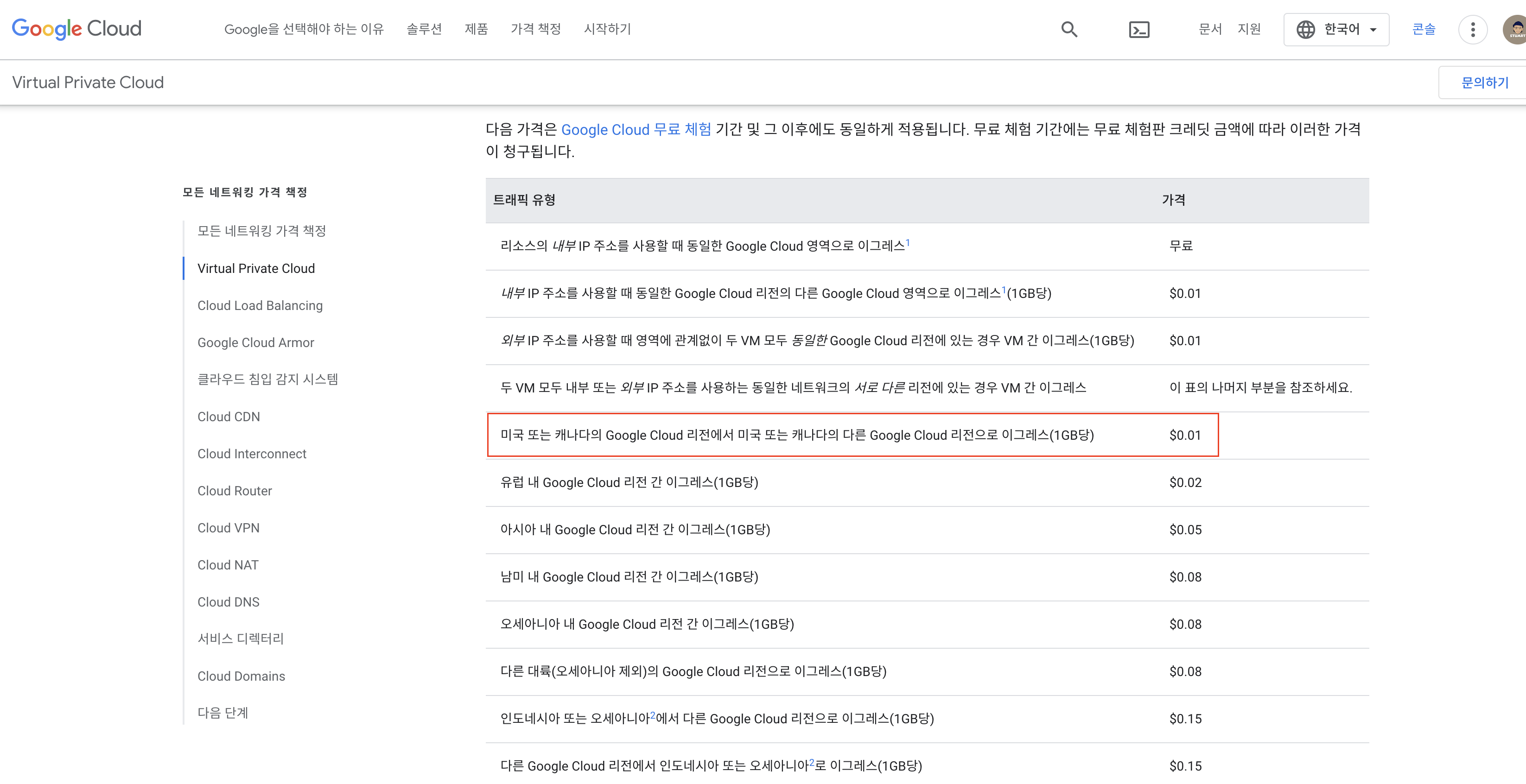
구글 클라우드에서도 VPC를 제공하는데 리전별로 또 가격이 다르네요.
공부용이라면 싼 지역으로 해보는 것을 추천드리면서 아래 미국/캐나다 지역이 가장 싼 것을 볼 수 있습니다.
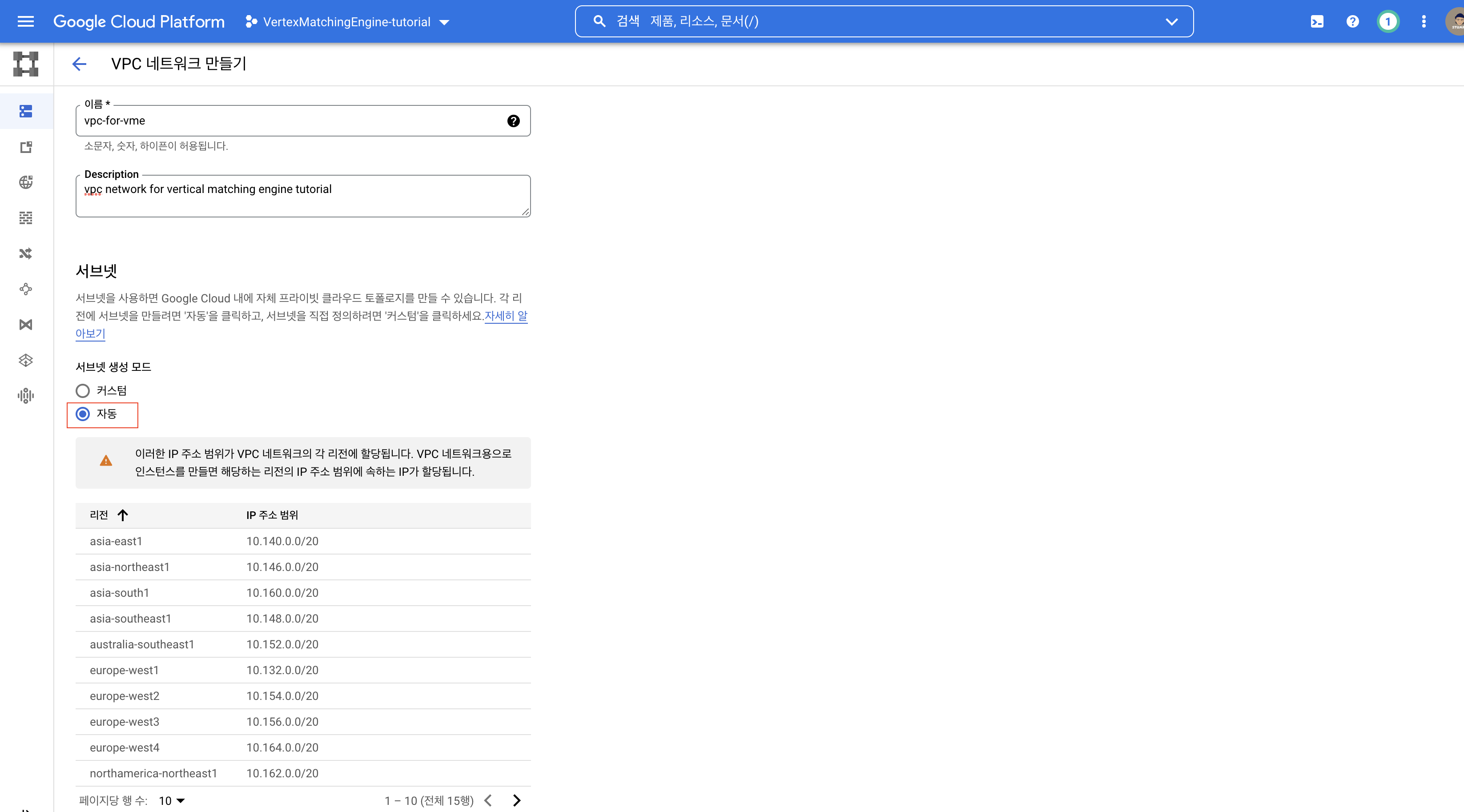
서브넷 생성 모드는 자동으로 선택해놓는 게 편합니다. 리전 선택하면 그에 따른 서브넷이 활성화됩니다.
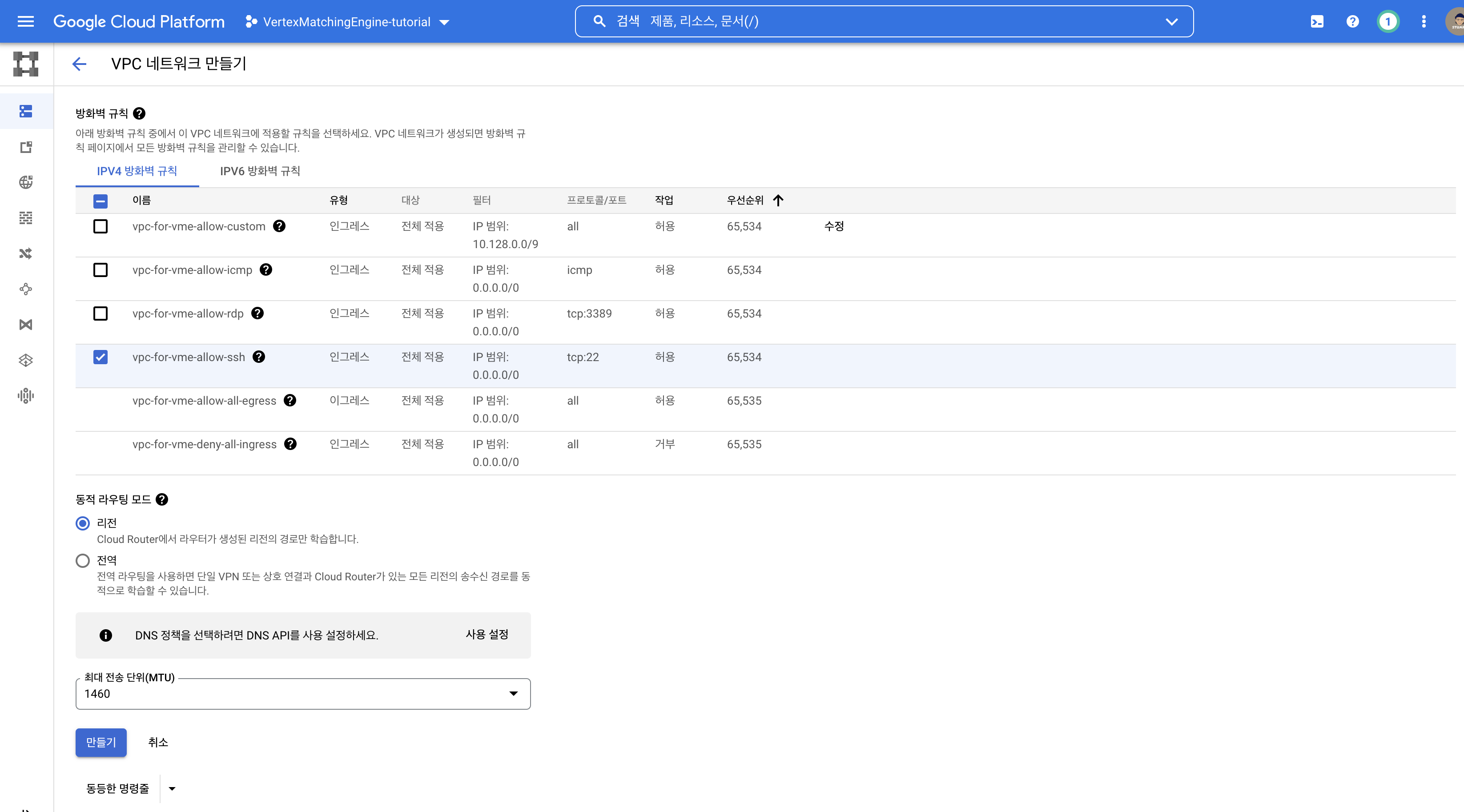
방화벽은 맘대로~ 어차피 나중에 인스턴스 연결시 따로 지정 가능하니까요.
동적 라우팅 모드 > 리전
vertex_matching_engine_example
References
- https://cloud.google.com/vertex-ai/docs/matching-engine/overview
- https://cloud.google.com/vertex-ai/docs/matching-engine/train-embeddings-two-tower
- google cloud vpc 리전별 요금
- vertex matching engine 사용하기 전에 할 것
- two-tower built-in algorithm
- vpc 개념 설명 블로그