
Authors : Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, Taku Komura
Institution : The University of Hong Kong, The Hong Kong University of Science and Technology, Adobe Research, Texas A&M University
Publication Date : Mar 17, 2022
github : https://github.com/EvelynFan/FaceFormer
paper : https://arxiv.org/pdf/2112.05329.pdf
Abstract
- speech-driven 3D facical animation 은 사람 얼굴의 복잡한 기하학적 측면과 3D audio-visual data의 제한된 이용 때문에 도적적인 과제에 속한다.
- 이전 연구들은 전형적으로 제한된 맥락의 짧은 오디오 데이터의 음소 수준 feature 학습에 초점을 두었고 결과적으로 정확하지 않은 입술 움직임을 만들었다.
- 이런 한계를 해결하기 위해 Transformer 기반 autoregressive model, FaceFormer를 제한하였다
- 긴 기간 오디오 맥락을 인코딩하고 autoregressive하게 움직이는 3D face mesh 시퀀스를 예측한다
- 데이터 부족 문제에는 self-supervised pre-trained speech recognition 데이터를 합쳐서 사용했다
- 특정 과제에 잘 맞는 두 가지 biased attention mechanism 을 제안하였다
- the biased cross-modal multi-head(MH) attention
- 효과적으로 audio-motion modalities 를 맞춘다
- the biased causal MH self-attention with a periodic positional encoding strategy
- 더 긴 audio sequences 를 일반화하는 능력을 제공
- the biased cross-modal multi-head(MH) attention
- 실험과 사용자 지각 연구 결과 본 연구의 접근법이 기존 SOTA 보다 뛰어남을 알 수 있었다.
1. Introduction
Speech-driven 3D facial animation 은 다양한 영역에서 활용될 수 있어서 학문적으로도 산업적으로도 매력적인 분야다. 실용적인 Speech-driven 3D facial animation 의 목표는 임의의 음성 신호로부터 자동으로 3D 아바타의 생생한 얼굴 표현을 만들어내는 것이다.
본 연구에서는 2D pixel 보다는 3D 기하학적 모형을 움직이도록 하는 것에 초점을 맞춘다. 기존 연구의 대부분은 거대한 2D 비디오 데이터셋을 가지고 말하는 얼굴의 2D 비디오를 제작하는데 목표를 두었다. 이런 작업물의 결과는 3D 게임이나 VR에 바로 적용하기 어렵다
몇몇 앞선 연구에서 2D 비디오를 이용하여 3D 얼굴의 패러미터를 얻으려고 시도했는데 신뢰할 수 없는 결과를 내보낼 여지 있었다.
speech-driven 3D facial animation 연구에서 대부분 3D mesh 기반 작업을 했지만 짧은 오디오를 입력으로 사용했고 이는 표정의 애매모호함을 낳았다.
MeshTalk 은 더 긴 오디오 맥락을 사용했지만 데이터가 부족한 상황에서 Mel spectral audio features를 가지고 학습하여 정확한 입술 움직임을 합성해내는 데 실패하였다.
3D motion capture data 를 모으는 것은 상당히 비싸고 시간 소요도 크다.
long-tern context 와 3D audio-visual data의 부족 문제를 해결하기 위해 Fig.1 에서 나오는 transformer 기반 autoregressive model을 제안하였다.
- 얼굴 전체(얼굴 위, 아래 모두)의 꽤 현실적인 움직임을 가능하게 하기 위해 long-term audio context 를 잡아낸다
- 데이터 부족 문제에 대처하기 위해 self-supervised pre-trained speech representations 을 효과적으로 활용한다.
- 시간적으로 안정적인 얼굴 영상을 제작하기 위해 얼굴 움직임의 히스토리를 고려한다.
Transformer 는 NLP 영역 뿐만 아니라 컴퓨터 비전 영역에서도 놀라울 만한 성과를 내고 있다. transformer 의 성공에는 self-attention mechanism 이 있다. self-attention 은 표현의 모든 부분에 명시적으로 attention을 계산하여 장, 단거리 관계를 모델링하는 데 효과적이다.
이렇게 좋은 transformer를 Speech-driven 3D facial animation 연구에 사용된 적이 적다. 다만 vanilla transformer 를 바로 적용하는 것은 잘 되지 않는다.
- transformer 는 학습에 많은 데이터를 필요로 한다 -> self-supervised pre-trained speech model(wav2vec 2.0) 사용
- wav2vec 2.0 은 대용량 unlabeled speech 데이터로 학습하여 풍부한 음소 정보를 가지고 있다.
- 거대한 사전학습 모델이 기반이 되기 때문에 적은 3D audio-visual 데이터로도 커버 가능
- 기본 transformer 는 modality alignment를 통제하기 어렵다 -> audio-motion alignment를 위해 alignment bias 를 추가
- speech 와 face motion 간의 상관관계를 모델링하는 것은 long-term audio context dependency를 고려해야 한다 -> 인코더 self-attention 의 attention 범위를 제한하지 않아서 긴 범위의 audio context dependency 를 잡도록 하였다.
- 사인파 포지션 인코딩을 하는 transformer 는 학습 때 보이는 것보다 긴 길이의 시퀀스를 일반화하는 능력이 떨어진다 -> Attention with Linear Biases(ALiBi) 에 영감을 받아, 더 긴 오디오 시퀀스를 일반화하는 능력을 향상시키기 위해, 시간적 bias 를 query-key attention score 에 추가하고, 주기적인 positional encoding 전략을 설계했다
본 연구의 주요 기여는 다음과 같다.
- An autoregressive transformer-based architecture for speech-driven 3D facial animation
- faceformer 는 long-term audio context 와 face motion의 역사를 인코딩하여 autoregressive하게 움직이는 3D face mesh 시퀀스를 예측한다
- 매우 현실적이고 얼굴의 위아래 모두에서 안정적인 모습을 보여준다
- The biased attention modules and a periodic position encoding strategy
- the biased cross-modal MH attention : 다른 modality 를 align 하기 위해 설계
- the biased causal MH self-attention with a periodic position encoding strategy : 더 긴 오디오 시퀀스를 일반화하는 능력을 향상시키기 위해 설계
- Effective utilization of the self-supvervised pre-trained speech model
- 사전학습 모델을 사용하여 데이터 제한 문제에 대처할 뿐만 아니라 입 움직임의 정확도도 향상시킴
- Extensive experiments and the user study to assess the quality of synthesized face motions
- 2개의 3D 데이터셋에서 현실적인 얼굴 움직임과 립싱크 관점으로 봤을 때, FaceFormer 가 현재 SOTA 보다 성능이 우수하다
2. Related Work
2.1 Speech-Driven 3D Facial Animation
- the history of facial animation
- 2D 기반 접근법
- 절차적 방법: 명확한 룰로 구성된 셋 사용
- 통제 가능성이 높아 입 움직임의 정확도를 보장
- 수작업이 엄청나게 많이 필요
- Data-driven 3D facial animation
- Expressive speech-driven facial animation(Cao et al, 2005)
- Anime Graph 구조와 검색 기반 기술 사용
- sliding window 접근법
- end-to-end conv net
- three-stage network - 음소 그룹, 랜드마크, 오디오 피쳐를 결합하여 얼굴 움직임 커브를 예측
- speaker-independent 3D facial animation method - 다양한 말하는 스타일을 잡아내지만 얼굴 아래쪽에만 거의 집중
- (MeshTalk) 범주 잠재 공간 학습
- 오디오 관련과 관련 없은 얼굴 모션을 성공적으로 풀어냄
- 꽤 성공적인 얼굴의 움직임을 보여주지만 많은 양의 정확한 3D 얼굴 데이터를 필요로 한다.
- Expressive speech-driven facial animation(Cao et al, 2005)
3. Our Approach: FaceFormer
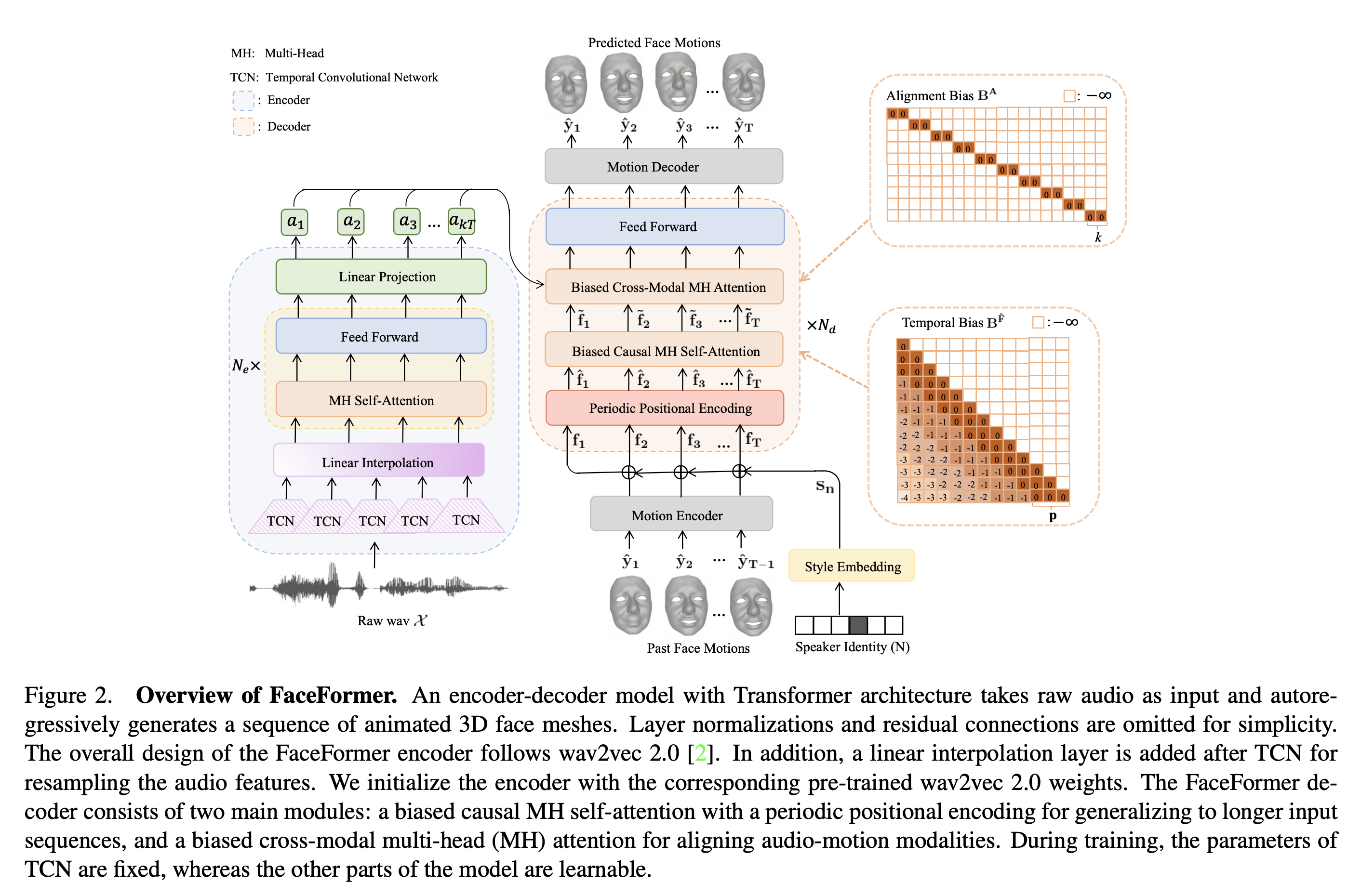
- speech-driven 3D facial animation 과제를 seq2seq 학습 문제로 만들었다.
- 새로운 seq2seq 아키텍쳐(Fig. 2)를 제안
- audio context와 과거 얼굴 움직임 시퀀스가 모두 있는 얼굴 움직임을 autoregressive하게 예측한다.
- 간단 설명
- ground-truth 3D face movements \(Y_T = (y_1, ... , y_T)\) 있다고 하자. T는 이미지 프레임 번호
- 목표는 얼굴 움직임 \(\hat{Y}\) 를 합성해낼 수 있는 모델을 만드는 것
- \(\hat{Y}\) 는 raw audio \(\chi\) 가 주어졌을 때 \(\hat{Y}\) 와 유사한 값
- 인코더는 \(\chi\) 를 speech representations \(A_{T'} = (a_1, ..., a_{T'})\) 로 변환
- \(T'\) 는 speech representation 의 frame 길이
- style embedding layer 는 speaker identities \(S = (s_1, ..., s_N)\) 를 표현하는 학습가능한 임베딩 셋을 포함한다
- 디코더는 autoregressive하게 \(A_{T'}\), style embedding \(s_n\) (n번째 speaker), 과거 얼굴 움직임 조건 하에 T번째 얼굴 움직임 \(\hat{Y}_T = (\hat{y}_1, ... , \hat{y}_T)\) 예측한다
-
\[\hat{y}_t = FaceFormer_{\theta}(\hat{y}_{<t}, s_n, \chi )\]
- \(\theta\) 는 model parameters
- t 는 현재 시간 스텝
- \(\hat{y}_t \in \hat{Y}_T\) .
3.1 FaceFormer Encoder
3.1.1 Self-Supervised Pre-Trained Speech Model
- faceformer 의 인코더는 SOTA 이자 self-supervised pre-trained speech model 인 wav2vec 2.0 을 따른다
- 인코더는 audio feature extractor 와 multi-layer transformer encoder 로 구성된다
- audio feature extractor
- 여러 개의 temporal convolutions layers(TCN) 로 구성
- raw waveform input 을 frequency \(f_a\) 가 있는 feature vectors 로 변환
- transformer encoder
- 적층된 multi-head self-attention, feed-forward layers 로 구성
- audio feature vectors 를 contextualized speech representations 로 변환
- audio feature extractor
- TCN 의 출력물은 양자화 모듈을 거쳐 유한한 speech unit 으로 쪼개진다.
- MLM과 비슷하게 wav2vec 2.0 은 진짜 speech unit 을 확인하는 작업을 수행하기 위해 마스킹된 타임스텝 주변의 맥락 정보를 사용한다.
- 인코더를 wav2vec 2.0 의 가중치로 초기화
- 인코더 젤 위에 임의로 초기화한 linear projection layer 추가
- linear interpolation layer
- TCN 거치면서 frequency 가 \(f_a\) 인 audio feature vectors 가 들어오는데 face motion 의 frequency \(f_m\) 가 다르기 때문에 audio features 를 resampling 하기 위해 추가
- 길이가 \(kT\)인 출력물을 만들어냄
- where \(k = \left \lceil \frac{f_a}{f_m}\right \rceil\)
- 결과적으로 linear projection layer 의 아웃풋은 \(A_{kT} = (a_1, ..., a_{kT})\)로 표현될 수 있다.
- –> 이런 식으로 audio, motion의 modalities 를 align 시켰다.
- 더 자세한 내용은 biased cross-modal multi-head attention 에서 다룰 예정
3.2. FaceFormer Decoder
3.2.1 Periodic Positional Encoding
- 사인파 positional encoding -> ALiBi 로 교체
- 사인파 positional encoding(sinusoidal positional encoding)
- 긴 시퀀스에서 제한된 일반화 능력을 갖게 함
- Attention with Linear Biases(ALiBi)
- query-key attention score 에 constant bias 를 추가하여 일반화 능력을 향상시킴
- 문제는 이 교체로 인해 inference 하는 동안 얼굴 표현이 정적인 모습을 보여줌
- ALiBi 는 입력 임베딩에 어떤 위치 정보도 추가하지 않는다
- 위 문제를 경감시키기 위해 Periodic Positional Encoding(PPE) 를 ALiBi 와 함께 씀
- 시간 순서 정보를 삽입하는 역할
- 원래 sinusoidal positional encoding 방법을 변형함
- \[PPE_{(t, 2i)} = sin((\mathbf{t}\, mod \,\textbf{p})/10000^{2i/d})\]
-
\[PPE_{(t, 2i+1)} = cos((\mathbf{t}\, mod \,\textbf{p})/10000^{2i/d})\]
- t 는 토큰 위치 혹은 현재 타임 스텝
- d 는 model dimension
- i 는 dimension index
- p 는 period 를 가리키는 hyper-parameter
- 각 period p 안에서 재귀적으로 위치 정보를 삽입하는 방식
- 사인파 positional encoding(sinusoidal positional encoding)
- PPE 전에 motion encoder를 사용하여 face motion \(\hat{y}_t\) 를 d 차원 공간에 projection 한다
- 말하는 스타일을 모델링하기 위해서 style embedding도 추가
- 용어
- \(W^f\) : 가중치
- \(b^f\) : bias
- \(\hat{y}_{t-1}\) : 이전 스텝로부터의 예측값
- \(s_n\) : style embedding
- 시간 순서 정보를 주기적으로 부여하기 위해 PPE 와 \(f_t\) 더한다.
3.2.2 Biased Causal Multi-Head Self-Attention
- ALiBi 기반으로 biased causal multi-head(MH) self-attention 을 설계
- 시간 순으로 인코딩된 facial motion representation sequence \(\hat{F}_t = (\hat{f}_1 , ..., \hat{f}_t)\) 가 주어진 상황에서, biased causal MH self-attention 은 \(\hat{F}_t\) 를 queries \(Q^{\hat{F}}\), keys \(K^{\hat{F}}\), values \(V^{\hat{F}}\) 에 linear하게 projection 시킨다.
과거의 facial motion sequence 맥락에서 각 프레임 간 의존성을 학습하기 위해, scaled dot-product attention 을 수행하여 가중치 맥락 임베딩을 계산한다.
\[Att(Q^{\hat{F}}, K^{\hat{F}}, V^{\hat{F}}, B^{\hat{F}}) = softmax(\frac{Q^{\hat{F}}(K^{\hat{F}})^T}{\sqrt{d_k}} + B^{\hat{F}})V^{\hat{F}}\]-
\(B^{\hat{F}}\) : temporal bias, 인과성 보장과 더 긴 시퀀스를 일반화하는 능력 개선을 위해 추가
- \(B^{\hat{F}}\) 는 현재 예측을 위해 미래의 프레임을 보는 것을 피하기 위해 upper triangle에 음의 무한대를 가지는 행렬이다
- 일반화 능력을 위해, \(B^{\hat{F}}\) 의 lower triangle 에 정적이면서 학습 안되는 biases 를 추가
- period p 를 도입하고 각 period에 temporal bias 를 주입한다 ([1:p], [p+1:2p], …)
더 높은 attention weights 를 더 가까운 기간에 할당함으로써 causal attention 을 편향시킨다. 가장 가까운 facial frames period (\(\hat{y}_{t-p}, ..., \hat{y}_{t-1}\)) 가 \(\hat{y}_t\) 의 현재 예측에 가장 영향을 줄 가능성이 높다.
-> 본 연구에서 제안한 temporal bias 는 ALiBi 의 일반화 포맷으로 볼 수 있고 ALiBi 는 p=1 인 특수 케이스이다.
multi head attention 은 attention 결과인 head 값을 concat 한 후 가중치에 곱한 값이다.
\(MH(Q^{\hat{F}}, K^{\hat{F}}, V^{\hat{F}}, B^{\hat{F}}) = Concat(head_1, ..., head_H) W^{\hat{F}}\) \(where \, head_h = Att(Q^{\hat{F}}_h, K^{\hat{F}}_h, V^{\hat{F}}_h, B^{\hat{F}}_h)\)
References