
Authors : Gautier Izacard, Edouard Grave
Institution : Facebook AI Research, ENS, PSL University, Inria
Publication Date : Feb 3, 2021
Paper link : https://arxiv.org/pdf/2007.01282.pdf
Github : https://github.com/facebookresearch/FiD
Abstract & Introduction
BlenderBot 2.0 을 이해하기 위해서 꼭 알아야 하는 아키텍쳐 중 하나인 FiD가 처음 소개된 논문입니다.
open domain 대화 시스템에서 외부 지식을 활용하는 부분은 일부 지식을 학습시킨다는 점에서 유한한 학습 데이터의 한계를 해결할 수 있어서 중요합니다.
FiD의 목적은 open domain QA를 위한 생성 모델이 “외부 지식”을 입력으로 받았을 때 이를 효과적으로 활용하는 것입니다.
FiD는 검색 기반 생성 모델입니다. 검색을 통해 나온 구절과 질문을 입력으로 받아 최종 응답을 생성해내는 방식입니다. 개념적으로 굉장히 간단하지만 TriviaQA와 NaturalQuestions(NQ)에서 기존 방법들을 제치고 SOTA를 찍었습니다.
검색한 구절의 개수가 늘어날 때, 성능 개선도 크게 있었다는 점을 고려하면 생성 모델은 추출 모델에 비해 여러 구절로부터 나오는 힌트를 결합하는 것을 더 잘하는 것으로 보입니다.
Related work
Open domain question answering
이 과제는 특정 도메인이 아닌 범용 목적의 QA 과제입니다.
- open domain QA는 오랜 기간 어려운 문제였지만 Chan et al. (2017) 연구에서 처음 이렇다 할 성과가 나왔습니다. 위키피디아에서 관련 문서를 검색하고, 해당 문서로부터 대답을 추출하는 방식입니다.
- 그 후에 대답에 대응하는 범위 전체에 대해 global normalization 하는 것도 나왔습니다.
- Wang et al. (2018)에서는 신뢰도와 커버리지 점수를 사용하여 여러 단락의 답변을 종합하는 기법을 제시하였습니다.
Passage retrieval
open domain QA에서 중요한 단계로, QA 시스템을 개선하는데 핵심적인 영역입니다.
- (2017) Reading Wikipedia to answer open-domain questions.
- 처음에는 TF/IDF 기반의 sparse representation 을 기반으로 관련 문서를 검색
- (2018) Ranking paragraphs for improving answer recall in open-domain question answering.
- 지도학습 방법 도입. BiLSTM 기반으로 단락을 rerank하는 방식
- (2018) Reinforced ranker-reader for open-domain question answering.
- ranking system에 강화학습 사용
- (2019) Knowledge guided text retrieval and reading for open domain question answering.
- 추가적인 정보로 위키피디아 사용
- (2020) Dense passage retrieval for open-domain question answering.
- dense representation 기반으로 가장 가까운 것을 찾음. 질문-대답 쌍 형태로 weak supervision으로 학습
- (2020) Realm: Retrieval-augmented language model pre-training.
- cloze(빈칸 채우기) task로 사전학습하고 end-to-end로 finetuning
Generative question answering
질문에 대해 응답을 생성해서 답변해야 하는 과제입니다. 응답이 관련 문서 내에 일치하는 것이 없어야 합니다.
- (2019) Exploring the limits of transfer learning with a unified text-to-text transformer.
- SQuAD와 같은 독해 과제에서 생성모델이 경쟁력 있음을 보임
- (2020) How much knowledge can you pack into the parameters of a language model?
- 추가적이 지식을 사용하지 않는 거대한 사전학습 생성 모델
- (2020) Retrieval-augmented generation for knowledge-intensive nlp tasks.
- Retrieval Augmented Generative model 제안. 현 연구와 유사점 있음
- 검색된 구절을 어떻게 처리하는지가 RAG와 다른 점.
Method
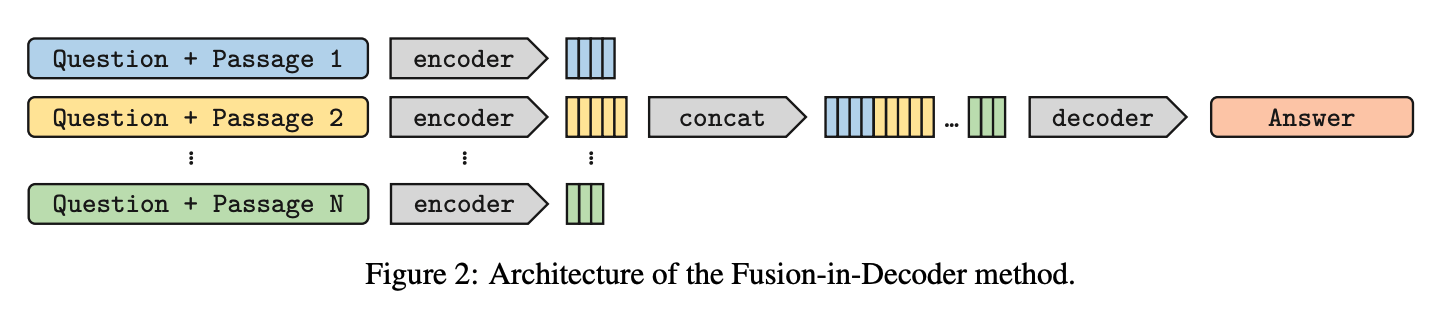
open-domain qa를 처리하기 위해 두 가지의 단계를 거칩니다.
- support passages를 검색한다.
- passages 를 seq2seq model로 처리하여 응답을 생성한다.
Retrieval
관련 구절 검색에 두 가지 방법을 비교하였습니다.
- BM25
- 구절을 bag of words로 표현
- ranking function은 TF/IDF에 기반
- Apache Lucene 사용
- SpaCy Tokenizer 사용
- DPR(Dense Passages Retrieval)
- 구절과 질문을 dense representation로 나타내면서 각각의 BERT network 사용(Bi-encoder)
- ranking function은 질문과 구절 간 내적(dot-product) 값을 기준으로 함
- FAISS 라이브러리로 최적 근사값 계산
Reading
생성 모델은 비지도 학습 데이터로 사전학습한 seq2seq network에 기반합니다. 모델은 입력으로 질문과 관련 구절을 받아서 대답을 생성합니다. 정확하게는, 각 검색된 구절, 그 구절의 제목, 질문을 이어서(concat) 인코더로 처리합니다. concat 하고 있기 때문에 구분하기 위해 special token을 추가합니다. 각각 context:, title:, question: 입니다. 예시를 들어보면 다음과 같습니다. N은 하이퍼패러미터입니다.
[question: "question" [SEP] title: "passage i 의 title" [SEP] context: "passage i 의 text"]
[question: "question" [SEP] title: "passage i+1 의 title" [SEP] context: "passage i+1 의 text"]
[question: "question" [SEP] title: "passage i+2 의 title" [SEP] context: "passage i+2 의 text"]
...
[question: "question" [SEP] title: "passage N 의 title" [SEP] context: "passage N 의 text"]
마지막으로 디코더는 모든 구절에 대해 attention을 계산합니다. 이 아키텍처의 이름이 “Fusion-in-Decoder” 인 이유는 디코더에서만 fusion(concat)을 하기 때문입니다.
RAG와 다른 점이 각 구절을 독립적으로 인코더에서 처리한 다음 디코더에서 결합한다는 점입니다. 인코더에서 각 구절을 독립적으로 처리하는 것은 한 번에 하나의 context에서만 self-attention 계산을 하기 때문에 context 개수를 크게 늘릴 수 있게 해줍니다. 이 개수를 늘리면 선형적으로 계산 시간도 늘어나긴 하지만 2차식(quadratically) 시간 만큼으로 늘어나는 것이 아니고 그만큼 집계 능력도 향상하기 때문에 이점이 있습니다.
Experiments
Datasets
- NaturalQuestions : 위키피디아에서 질문에 대한 짧은 답변과 긴 답변 모두 갖춘 데이터셋
- TriviaQA : “질문-대답-증거”로 구성된 데이터
- SQuAD v1.1 : 전형적인 독해 데이터셋으로, 위키피디아의 단락이 주어졌을 때, 질문과 함께 대답의 범위가 있는 데이터셋
각 데이터의 10%를 검증 데이터로 사용했습니다.
Evaluation
- EM(Exact Match) : 생성된 대답은 normalization 후에 수용가능한 대답 목록 중에 있으면 맞는 것으로 간주
- normalization : 소문자화, 관사, 점, 중복 공백 제거,
Technical details
- 모델을 사전학습된 T5 모델로 초기화함 (HuggingFace 라이브러리 사용)
- 두 개의 모델 사이즈 선택
- base : 220M parameters
- large : 770M parameters
- 두 개의 모델 사이즈 선택
- finetune
- Adam optimizer
- learning rate : \(10^{-4}\) (계속 유지)
- batch size : 64
- evaluation interval : 500 steps
- gpu : 64 Tesla V100 32Gb
- 학습 및 테스트시에 100개의 구절을 뽑고 250개 단어까지만 잘라서 사용
- DPR 논문 의 결과를 따라
- NQ와 TriviaQA는 DPR로 구절 검색
- SQuAD는 BM25로 검색
- 응답 생성은 greedy decoding을 사용
- greedy decoding : 확률값이 가장 높은 값을 선택하는 방식
Comparison to state-of-the-art.
Table 1
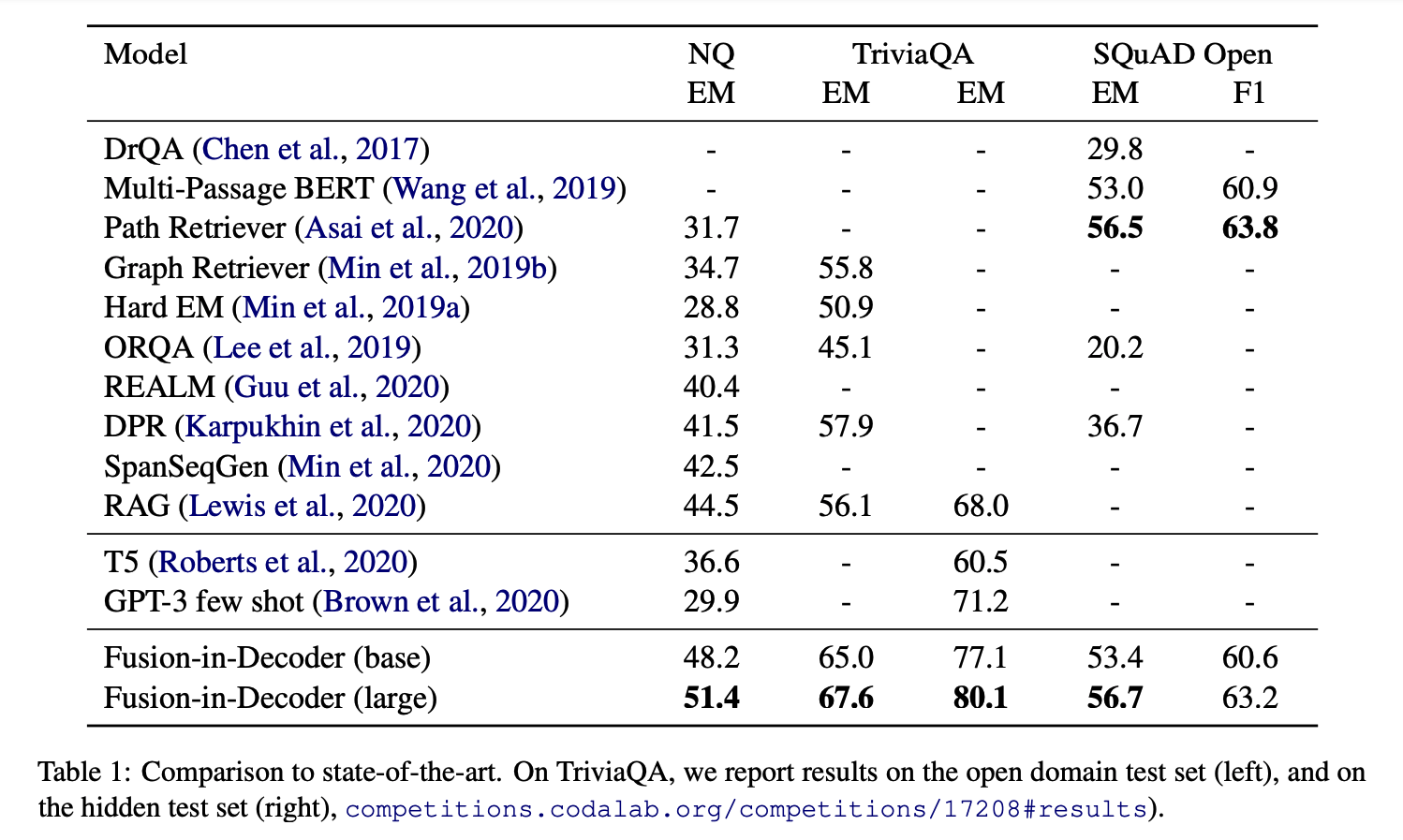
- FiD가 개념적으로 간단하지만 NQ와 TriviaQA에서는 모든 비교군보다 좋은 성능을 냈습니다.
- 생성 모델에서 추가적인 지식을 사용한 모델이 중요한 성능 증대를 보였습니다.
- NQ에서 T5(closed book) 11B의 패러미터를 가지고 36.6% 정확도, FiD는 추가 지식(위키피디아)과 770M의 패러미러로 44.1% 정확도
Figure 3
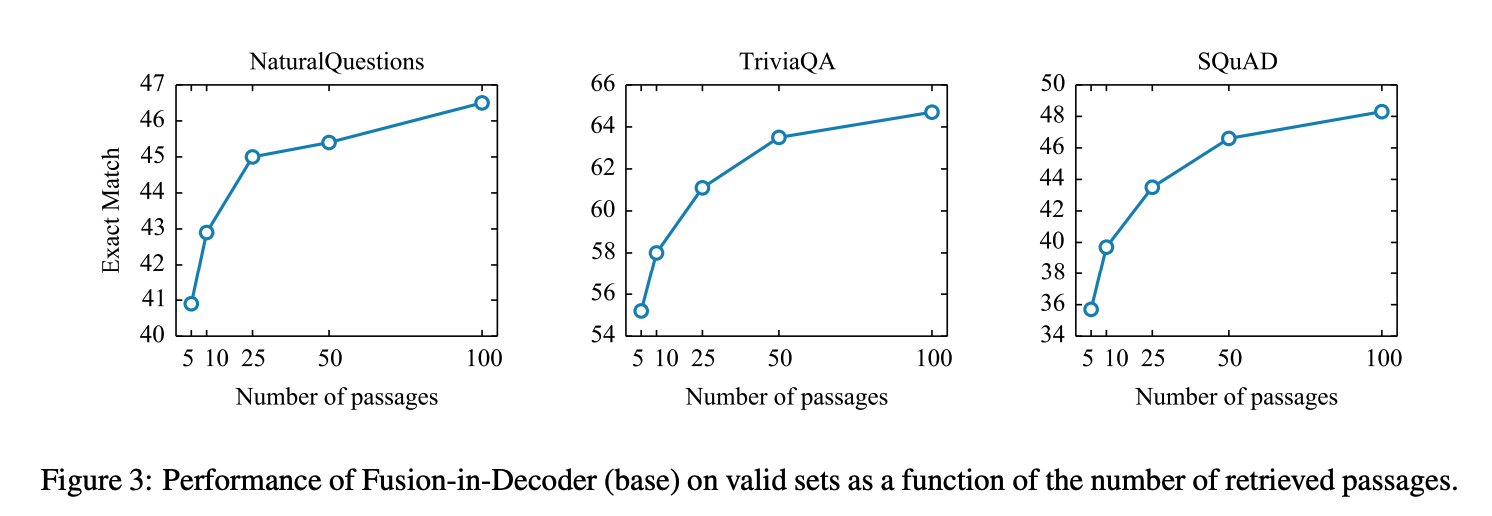
- 검색된 구절 개수를 늘렸을 때 FiD의 성능이 올라가는 것을 관찰할 수 있음.
- 구절 개수를 10개에서 100개로 늘릴 때, TriviaQA는 6%의 성능 향상을, NQ에서는 3.5%의 향상을 보임
- 반면 추출 모델은 10~20개 사이일 때 성능이 최고조
seq2seq model이 여러 구절로부터 정보 결합을 더 잘한다는 것을 보여준 결과라고 해석할 수 있습니다.
Impact of the number of training passages.
이전 실험들에서는 모두 학습과 테스트에서 동일한 구절 개수를 사용했습니다. 학습 계산 예산을 줄이기 위해 간단한 솔루션으로 학습 과정에서 더 적은 수의 구절을 사용해보았습니다. 그 결과가 Table 2 입니다.
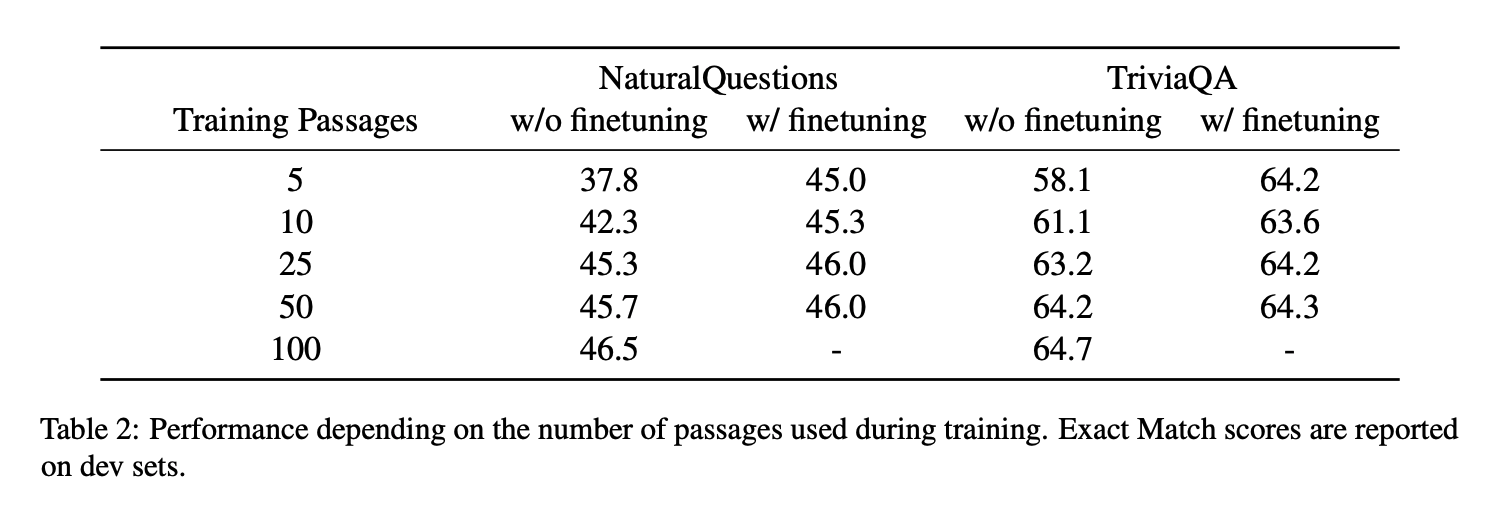
학습에서 사용한 구절 개수는 5~100개 까지 5개 조건을 만들었고, 테스트는 100개의 구절로 동일하게 사용하였습니다.
- 학습 구절 개수를 줄이면 정확도가 떨어짐.
- finetuning 여부에 따라 어떤 결과가 나오는지
- finetuning 하면 학습 구절 개수에 따른 정확도 차이를 줄일 수 있음.
- 100개의 학습 구절 사용했을 때, NQ에서 46 EM까지 도달한 시간
- w/ finetuning : 147 GPU hours
- w/o finetuning : 425 GPU hours
Conclusion
이 논문은 간단한 구조 변경을 통해 open-domain QA에 성능 개선을 가져왔습니다. 특히 추가적인 지식을 활용하는데 중점을 두고 있습니다. FiD를 쓸 경우 성능 개선 뿐만 아니라 구절의 확장성, finetuning 시 효율성도 얻을 수 있습니다.
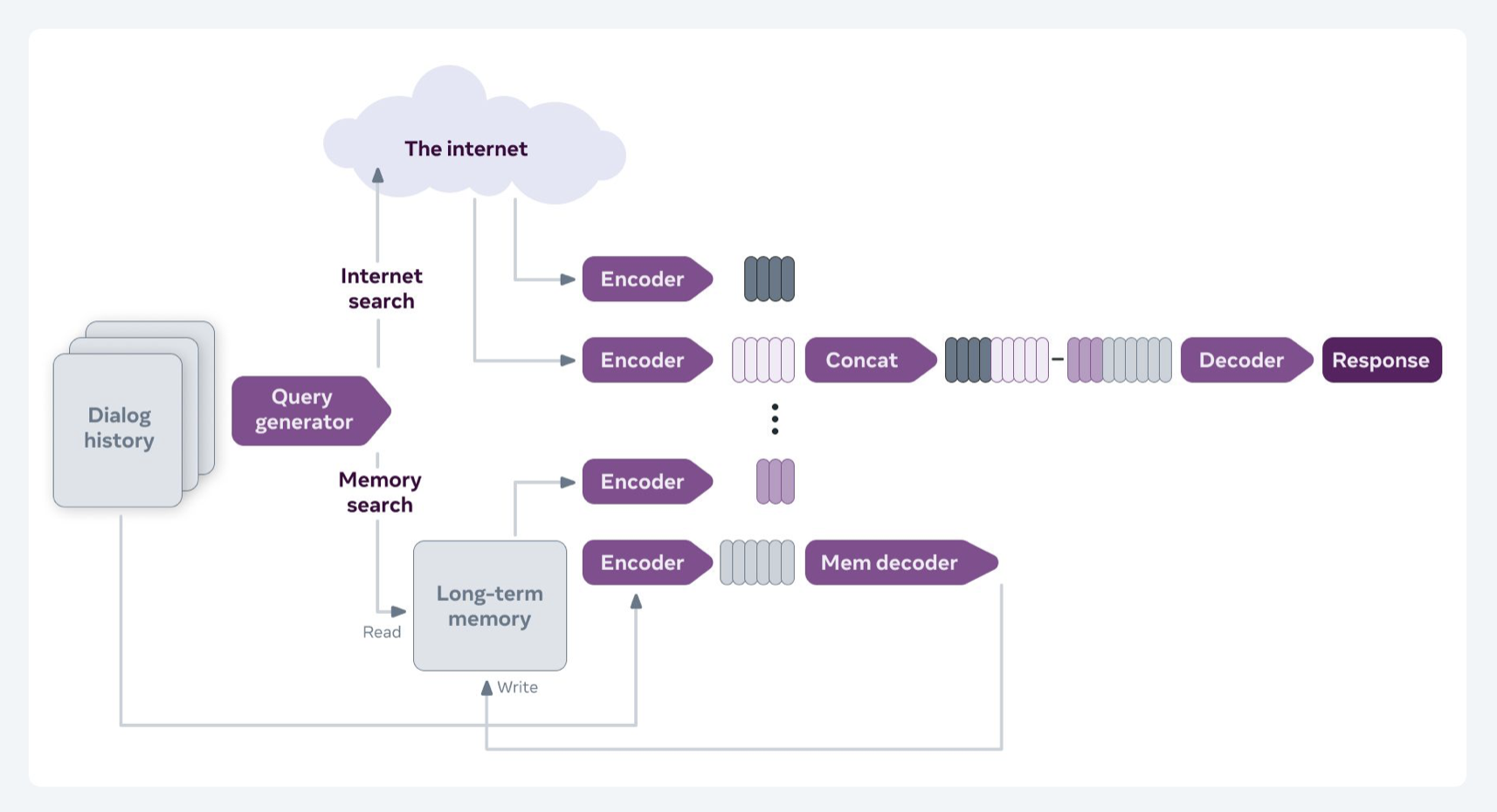
FiD는 BlenderBot 2.0에서 인터넷에서 가져온 구절들과 기존 long-term memory에서 가져온 구절들을 합쳐서 디코더에 넣는 장면에서 확인할 수 있습니다.
연구자들은 추후에는 완전히 end-to-end로 전체시스템을 학습시킬 수 있게 만드는 것이 목표라고 합니다.
References