
- 교재 : Deep Reinforcement Learning Hands-On 2/E
- github : https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Second-Edition
Intro
5장에서는 벨만 방정식과 그 응용 방법인 value iteration에 대해 다뤘습니다. 이런 접근 방법은 FrozenLake 환경에서 수렴 속도가 굉장히 빨랐습니다. 이번 챕터에서는 더 복잡한 환경(아타리 게임)에서 value iteration을 적용해볼 예정입니다.
이번 챕터에서는 다음과 같은 내용을 다룰 예정입니다.
- value iteration의 문제에 대해 다루고 Q-learning 일 때는 어떤지 확인해본다.
- grid world 환경에서 Q-learning을 적용(tabular Q-learning)한다.
- Q-learning과 뉴럴넷의 결합인 deep Q-networks(DQN)에 대해 알아본다.
마지막으로 Playing Atari with Deep Reinforcement Learning 논문에서 나온 DQN 알고리즘을 구현해보도록 하겠습니다.
Real-life value iteration
FrozenLake와 같은 심플한 환경에서 value iteration은 cross-entropy보다 훨씬 좋은 성능을 보여주었습니다. 이번엔 더 복잡한 환경에 적용해보려 합니다.
value iteration에 대해 빠르게 복기해보면, value iteration은 매 스텝마다 모든 상태에 대해 벨만 근사를 통해 가치를 업데이트 합니다. Q value(행동 가치)를 위한 버전도 거의 동일합니다. 차이점은 모든 (상태, 행동) 쌍(pair)에 대해 가치를 추정하고 저장한다는 점입니다.
Value Iteration에는 명백한 문제점이 있습니다.
현실적인 문제들에서 첫번째 전제부터 실현 불가능한 경우가 많고 또 알더라도 그 모든 상태에 대해 반복 작업을 하는 것은 비효율적입니다.
예를들어 Atari 2600 게임이 있습니다. 아타리 게임은 1980년대 유행했고, 아케이드 스타일의 게임입니다. 이 게임은 RL 연구에서 가장 인기 있는 벤치마크 플랫폼입니다.
[아타리 게임의 상태 공간]
- 화면 해상도 : 210 X 160 pixels, 126개의 색깔(channels)
- 화면당 프레임 : 210 X 160 = 33,600 pixels, 색이 126개이므로 총 가능한 화면 수는 \(128^{33600}\)
아타리 게임의 가능한 상태를 한번 돌리는 것만 해도 수퍼컴퓨터로도 수십억년 소요되고 99% 이상의 반복 작업은 낭비에 가까운 작업입니다.
실제로 Q(s,a)와 V(s) 근사는 행동이 서로 배제적이며 이산적인 셋일 때 가능합니다. 휠 조종 각도나 히터기의 온도 조절 같이 연속적인 컨트롤 문제에는 적용할 수 없습니다.
연속 행동 공간을 다루는 것은 꽤나 도전적인 과제이기 때문에 책의 뒷 부분에서 다룰 예정입니다.
일단 아래 내용에서는 행동 공간이 이산적이고 행동 개수도 그렇게 크지 않다고 가정했을 때, 이를 Q-learning으로 해결해보는 과정에 대해 다루겠습니다.
Tabular Q-learning
상태 공간의 모든 상태에 대해 반복을 해야 할까요? 만약 상태 공간의 일부 상태가 보이지 않는다면, 그 가치를 우리가 왜 신경써야 하나요? 우리가 환경으로부터 얻은 상태만 이용해서 업데이트할 수 있다면 효율성이 올라가지 않을까요?
이런 생각에서 나온 value iteration의 변형이 Q-learnig이라 불리는 방법입니다. 명시적으로 상태-가치 매핑이 있는 경우에 다음과 같은 단계를 따릅니다.
- 초기화(empty table, mapping states to values of actions)
- 환경과 상호작용함으로써, s, a, r, s’ (state, action, reward, and the new state) 를 튜플로 얻는다.
- 이 단계에서 어떤 행동을 취할지 정해야 하고 항상 옳은 정책이 있다기 보다는 상황에 따라 다를 수 있다.
- 다음과 같은 “blending” 기술을 이용한 근사를 사용해서 Q(s,a) 를 업데이트
-
$$ Q(s,a) \leftarrow (1-\alpha)Q(s,a) + \alpha(r + \gamma \max_{a'\in A} Q(s', a')) $$ - 이는 학습률(\(\alpha\))을 사용해서 Q의 이전 가치와 새로운 가치의 weighted sum한 것
- 환경에 노이즈가 많더라도 Q value를 부드럽게 수렴하게 해줌
-
- 수렴할 때까지 반복
- 업데이트 정도나 테스트 성능이 특정 역치에 다다르면 멈추는게 일반적인 종료 조건
Q-learning 보충
현 교재가 코드 중심이어서 Q-learning에 대한 설명이 부족한 듯 하여 Sutton 교수님의 책에서 나온 내용으로 일부 보강하였습니다.
- Q-learning은 Off-policy TD learning(Watkins, ‘89)이다.
- 이 수식은 위에서 나온 식과 동일하고 배치를 바꾼 것이다.
- backup diagram
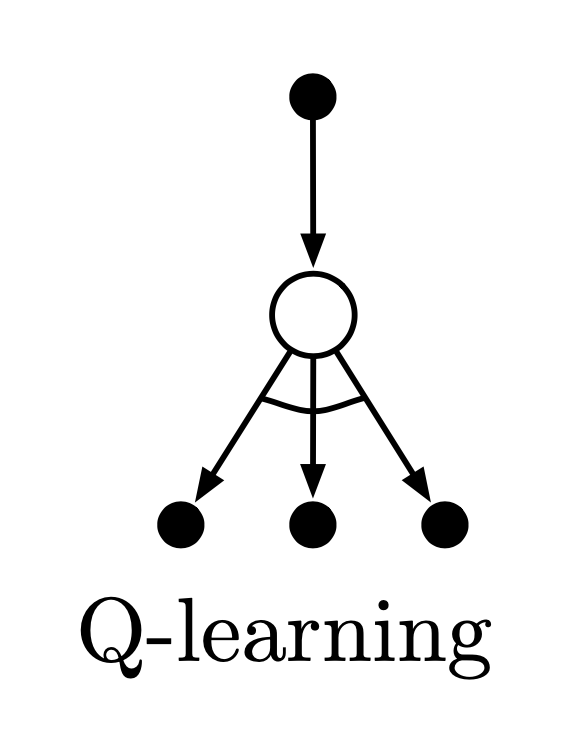
- Q-learning은 기존의 off-policy와 다르다.
- 기존 off-policy는 behavior policy와 target policy가 다르기 때문에 behavior policy에서 학습한 내용을 target policy에서도 보장하기 위해 sampling data의 분포가 같다는 것을 증명해야 한다. 여기서 사용되는 것이 importance sampling이다. importance sampling은 다른 분포에서 sampling한 데이터를 알아야할 분포에 맞게끔 보정해서 estimate하는 기법을 말한다.
- 위 수식에서도 확인할 수 있듯이, Q-learning은 importance sampling ratio가 없다.
- 1 step 진행하고 바로 업데이트하기 때문에 target, behavior policy가 달라질 수 없어서 importance sampling ratio를 제거
이제 다시 원래 교재로 돌아와서 코드를 살펴보도록 하겠습니다. 첫 번째 코드는 Chapter06/01_frozenlake_q_learning.py 파일입니다. 파일 제목에서도 알 수 있듯이 frozenlake 환경에서 q learning을 돌린 것입니다.
#!/usr/bin/env python3
import gym
import collections
from tensorboardX import SummaryWriter
ENV_NAME = "FrozenLake-v0"
GAMMA = 0.9 # discounting factor
ALPHA = 0.2 # learning rate in the value update
TEST_EPISODES = 20
class Agent:
def __init__(self):
'''
간단한 환경이라 보상 이력이나 전이에 대한 기록을 하지 않고 value table만 유지.
복잡한 환경에서는 모두 필요
'''
self.env = gym.make(ENV_NAME)
self.state = self.env.reset()
self.values = collections.defaultdict(float)
def sample_env(self):
'''
(old state, action, reward, new state) 튜플을 환경으로부터 얻기 위한 전처리 함수
'''
action = self.env.action_space.sample()
old_state = self.state
new_state, reward, is_done, _ = self.env.step(action)
self.state = self.env.reset() if is_done else new_state
return old_state, action, reward, new_state
def best_value_and_action(self, state):
'''
value table 참조하여 입력값 state에 따른 최고 action과 value 반환
두군데에서 사용
1. test method에서 정책의 퀄리티를 평가하기 위해 현재 value table을 이용하여 하나의 에피소드를 돌릴 때
2. 다음 state의 가치를 얻기 위해 value update를 수행할 때
'''
best_value, best_action = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_value, best_action
def value_update(self, s, a, r, next_s):
'''
Q-learning의 value update
value table에 Q value 유지
'''
best_v, _ = self.best_value_and_action(next_s)
new_v = r + GAMMA * best_v
old_v = self.values[(s, a)]
self.values[(s, a)] = old_v * (1-ALPHA) + new_v * ALPHA
def play_episode(self, env):
'''
하나의 에피소드 전체를 진행
'''
total_reward = 0.0
state = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, _ = env.step(action)
total_reward += reward
if is_done:
break
state = new_state
return total_reward
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-q-learning")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
s, a, r, next_s = agent.sample_env()
agent.value_update(s, a, r, next_s)
reward = 0.0
for _ in range(TEST_EPISODES):
reward += agent.play_episode(test_env)
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (
best_reward, reward))
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
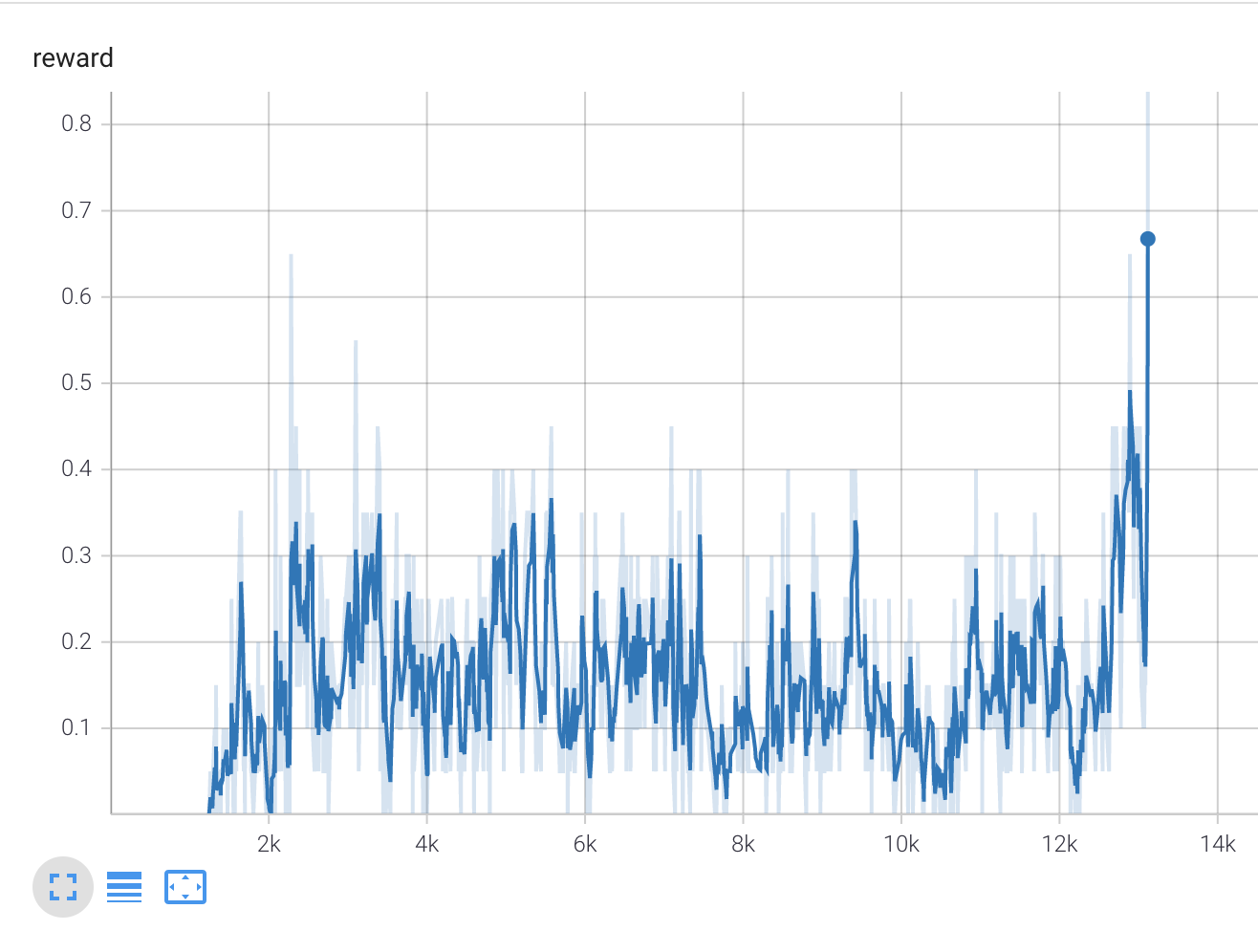
실제 코드를 돌리면 다음과 같은 결과가 나왔습니다.
.../Chapter06$ CUDA_VISIBLE_DEVICES=1 python 01_frozenlake_q_learning.py
[Best reward updated 0.000 -> 0.350
Best reward updated 0.350 -> 0.450
Best reward updated 0.450 -> 0.550
Best reward updated 0.550 -> 0.600
Best reward updated 0.600 -> 0.650
Best reward updated 0.650 -> 0.800
Best reward updated 0.800 -> 0.850
Solved in 13117 iterations!
이전 챕터에서 20~30 iteration만에 역치를 넘긴 것에 비하면 엄청나게 차이가 나는 수치입니다. 이런 차이가 나는 것은 위 코드에서는 test 시에 value update를 하지 않았고 이전 챕터의 코드에서는 했기 때문입니다. 전반적으로 환경에 필요한 총 샘플 수도 거의 같고 TensorBoard의 reward 차트도 value iteration 방법과 유사하게 우수한 학습 결과를 보여줍니다.
Deep Q-learning
방금 다룬 Q-learning 방법은 전체 상태 집합에서 반복되는 문제를 해결하긴 하지만 관찰 가능한 상태 집합의 수가 매우 많은 상황에서는 여전히 어려움을 겪을 수 있습니다.
atari 게임 중 pong은 \(10^{70802}\) 개의 가능한 상황이 있습니다. 이렇게 많은 상황에서 에이전트는 다르게 행동해야 합니다.
이 문제에 대한 해결책으로 state와 action을 모두 value에 매핑하는 nonlinear representation을 사용할 수 있습니다. 머신러닝에서는 이를 “회귀 문제”라고 합니다. 이를 구현하는 방법은 다양하지만 이미지로 표현되는 관찰을 처리할 때 deep neural net을 사용하는 것이 가장 인기가 많습니다. 이 점을 염두에 두고 Q-learning 알고리즘을 수정하면 다음과 같습니다.
- Q(s,a) 초기 근사값으로 초기화
- 환경과 상호작용하면서 (s, a, r, s’) 튜플을 얻는다.
- Loss 계산
- if 에피소드 종료: \(L = (Q(s,a) - r)^2\)
- else : \(L=(Q(s,a) - (r+\gamma \max_{a' \in A} Q_{s', a'}))^2\)
- 각 모델 패러미터에 대해 loss 값을 줄이면서, stochastic gradient descent(SGD) 알고리즘으로 Q(s,a) 업데이트
- 수렴할 때까지 스텝2부터 반복
이 알고리즘은 간단해보이지만 작동도 잘 안되다고 하네요…. 왜 그러는지 살펴보겠습니다.
Interaction with the environment
랜덤하게 행동하면 효율적이지 못하고 현재 경험 바탕으로 근사만 하면 local minima에 머무를 수 있습니다. exploration과 exploitation은 tradeoff 관계면서도 이를 적절히 해결하기 위한 방법이 epsilon-greedy(\(\epsilon - greedy\)) 알고리즘입니다. 엡실론은 랜덤 행동의 비율입니다. 처음에 100%의 엡실론으로 시작하여 점차 그 값을 줄여나가서 2~5% 정도까지 줄이면 적절하게 랜덤 행동하면서 최적 행동을 찾고 기존 경험에서 최적 행동을 하면서 학습하는 정책입니다.
SGD optimization
Deep Q-learning 절차의 핵심은 지도학습에서 빌려온 것이고 optimizer를 SGD로 쓰고 있습니다. SGD 최적화의 가장 기본적인 조건 중 하나는 학습 데이터가 독립 동일 분포(independent and identically distributed, 줄여서 i.i.d) 를 따라야 한다는 점입니다.
그런데 현재 이 책에서 SGD 업데이트를 위해 사용하려는 데이터는 이 조건을 충족하지 못 합니다.
- 우리의 표본은 독립적이지 않다. 많은 배치를 모았더라도 그것들은 서로 매우 가깝다. 왜냐하면 동일한 에피소드에서 나왔기 때문이다.
- 학습 데이터의 분포가 학습하고자 하는 최적 정책이 제공하는 표본의 분포와 다를 것이다.
이 문제를 해결하기 위해 최신 경험만 사용하는 것이 아니라 과거 경험들과 학습 데이터 샘플들을 모아둔 큰 buffer를 사용합니다. 이를 replay buffer라고 합니다. 가장 간단한 replay buffer 구현은 고정된 크기의 버퍼를 만들고 새로운 데이터가 들어오면 버퍼의 마지막에 추가하여 가장 오래된 데이터는 밖으로 빠져나가게 하는 것입니다.
replay buffer 는 다소 독립적인 데이터를 학습하도록 해주면서 최근 정책에 의해 생성된 샘플에서 학습할 수 있을만큼 충분히 새로운 데이터를 제공해줍니다.
(다음 챕터에서는 보다 정교한 샘플링 방식을 제공하는 replay buffer, prioritized 를 확인할 것입니다.)
Correlation between steps
기본 학습 절차의 또 다른 현실적인 문제는 조금 다르긴 하지만 역시 i.i.d 데이터의 부족과 관련이 있습니다. 벨만 방정식은 Q(s’, a’) 를 통해 Q(s, a) 값을 제공합니다.(bootstrapping) 하지만 두 상태 s, s’ 는 겨우 한 스텝 차이입니다. 즉, 이 두 상태는 매우 유사해서 뉴럴넷에게는 구분하기 어려운 부분입니다.
Q(s,a)를 바람직한 결과에 가깝도록 만들기 위해 뉴럴넷 패러미터들을 업데이트할 때, 간접적으로 Q(s’, a’) 값과 근처 다른 상태들을 변경할 수 있고 이는 학습을 매우 불안정하게 만들 수 있습니다.
The Markov property
강화학습 방법은 Markov decision process(MDP)를 기초로 합니다. MDP 는 환경이 Markov property를 지녔다고 가정합니다.
아타리 게임과 같이 이미지를 입력으로 사용하는 환경의 경우, 단일 캡쳐 이미지 하나는 중요한 정보를 담기에 충분치 않아서 여러 개의 캡쳐를 하나의 입력으로 사용합니다. 그런데 이는 명백하게 Markov Propery 위반이면서 단일 프레임의 환경을 partially observable MDPs(POMDPs) 로 바꿉니다.
POMDP는 markov property를 지니지 않은 MDP 이고, 현실에서 매우 중요한 역할을 합니다. 예를 들어 상대의 카드가 보이지 않는 대부분의 카드 게임에서 게임 관찰값은 POMDP 입니다. 현재 관찰값(당신의 카드와 테이블에 있는 카드)이 상대의 손에 있는 다른 카드에 해당될 수 있기 때문입니다.
이 책에서 POMDP에 대해 자세히 다루지는 않을 예정이지만, 앞선 환경을 MDP 도메인으로 돌려보낼 작은 테크닉을 보여줄 것입니다. 그 해결책은 과거의 일부 관찰값들을 유지하고, 상태값으로 사용하는 것입니다. 아타리 게임의 경우 k개의 프레임을 쌓아 매 상태의 관찰값으로 사용합니다. 이는 에이전트가 (예를 들어) 공의 속력과 방향을 알아내기 위해 현재 state의 dynamics를 추론하도록 해줍니다. 아타리 게임에서 k는 보통 4입니다. 이는 트릭이지만 대부분 게임에서 꽤 잘 작동합니다.
The final form of DQN training
epsilon-greedy, replay buffer, target network는 딥마인드가 49개의 아타리 게임에서 DQN을 성공적으로 학습하고 복잡한 환경에 적용할 때 이 접근법의 효율성을 입증할 수 있는 기반이 되었습니다.
(DQN 학습을 보다 안정적이고 효율적으로 수행하기 위해 연구자들이 발견한 여러 가지 팁과 요령에 대해 다음 장에서 더 다룰 것입니다.)
DQN이 등장한 논문(target network는 없음)은 2013년 말에 나왔고(Playing Atari with Deep Reinforcement Learning, 1312.5602v1, Mnih and others) 테스트에 7개 게임을 사용했습니다. 15년 초에 새 버전을 49개 게임으로 테스트하여 Nature지에 기고하였습니다.(Human-Level Control Through Deep Reinforcement Learning, doi:10.1038/nature14236, Mnih and others)
DQN 알고리즘은 다음과 같이 진행됩니다.
- \(Q(s,a)\) 와 \(\widehat{Q}(s,a)\) 의 패러미터를 임의의 가중치값들로 초기화한다. epsilon=1.0, replay buffer는 빈값.
- 엡실론의 확률로, 임의의 행동 a를 선택하거나 Q(s,a) 최대가 되는 행동 a를 선택한다(\(a=argmax_{a}Q(s,a)\)).
- emulator에서 행동 a를 실행하고, 보상 r과 다음 상태 s’를 얻는다.
- transition (s, a, r, s’)를 replay buffer에 저장한다.
- replay buffer 로부터 transition 의 미니배치를 랜덤하게 표집한다.
- 모든 transition마다, 다음을 계산한다.
- \(y=r\) (이번 스텝이 에피소드 마지막일 때)
- \(y=r + \gamma \max_{a' \in A} \widehat{Q}(s',a')\) (마지막 에피소드가 아닐 때)
- loss 계산 : \(L=(Q(s,a) - y)^2\)
- 각 모델 패러미터에 대해 loss 를 최소화하면서 SGD 알고리즘으로 Q(s,a)를 업데이트한다.
- N step마다 Q에서 \(\widehat{Q}\)로 가중치를 복사한다.
- 수렴될 때까지 2단계부터 반복 실행한다.
다음 세션에서는 위 내용을 코드로 구현하고 아타리 게임을 더 잘 수행하도록 조정해보겠습니다.
DQN on Pong
이번 코드는 길이, 논리적 구조, 재사용성 때문에 3개의 모듈로 나뉘어져 있습니다.
- Chapter06/lib/wrappers.py: 아타리 게임 환경에 대한 wrapper class
- Chapter06/lib/dqn_model.py: Nature 지에 나온 딥마인드 DQN과 동일한 아키텍쳐를 지닌 DQN 뉴럴넷 레이어
- Chapter06/02_dqn_pong.py: 메인 모듈로 학습 과정 포함.
Wrappers
강화학습으로 아타리 게임을 다루는 것은 자원적인 측면에서 상당히 어려운 일입니다. 학습 속도를 더 빨리 진행하기 위해 DeepMind의 논문에 설명된 아타리 게임 환경에 몇 가지 변형을 한 것이 wrapper 입니다. 이러한 변형들에는 성능에만 영향을 끼치는 것도 있으나 일부는 학습을 더 길게, 더 불안정하게 만드는 것도 있습니다. 구현 코드는 다양하게 있는데 이 책에서는 OpenAI Baselines 레포지토리를 다룰 예정입니다. 이 레포지토리가 텐서플로우로 구현되어 있고 유명한 벤치마크로 비교해놨기 때문입니다.
다음은 강화학습 연구자들에게 가장 인기 있는 아타리 게임 변형들 목록입니다.
- Converting individual lives in the game into separate episodes :
- 일반적으로 에피소드는 시작부터 게임이 끝날 때까지의 모든 스텝을 포함하고 있다. 이 변형은 전체 에피소드를 플레이어가 살아있는 작은 에피소드로 분리한 것이다. 모든 게임에서 지원하는 것은 아니지만 수렴 속도를 빠르게 해주는 효과가 있다.
- At the beginning of the game, performing a random amount (up to 30) of no-op actions :
- 게임 플레이와 무관한 시작 장면을 생략한다. (일부 게임에서만)
- Making an action decision every K steps, where K is usually 4 or 3 :
- 매 K 스텝마다 행동을 선택해서 반복한다. 뉴럴넷을 사용하여 모든 프레임을 처리하는 작업은 상당히 까다롭지만 결과 프레임 간의 차이는 보통 미미하기 때문에 학습 속도를 크게 높일 수 있습니다.
- Taking the maximum of every pixel in the last two frames and using it as an observation :
- 일부 아타리 게임 중에는 플랫폼의 한계로 인해 깜빡임이 있는 것들이 있다. 인간은 이를 인식하지 못하지만 뉴럴넷은 혼동할 수 있다. 그래서 마지막 두 프레임에서 최대값을 관찰값으로 사용한다.
- Pressing FIRE at the beginning of the game :
- 게임 시작 때 FIRE 버튼을 누른다. 일부 게임(Pong과 Breakout)은 게임 시작을 위해서는 사용자가 FIRE 버튼을 눌러야 한다. 버튼 누르는 것 없으면 환경은 POMDP가 된다. 관찰값으로부터 에이전트가 버튼이 이미 눌렸는지 구분할 수 없기 때문이다.
- Scaling every frame down from 210×160, with three color frames, to a single-color 84×84 image :
- 210x160 픽셀의 3개 색상을 가진 프레임을 단일 색상 84x84 이미지로 스케일링한다. 이 방식만 있는 것은 아니고 다양하게 활용 가능합니다. 그레이스케일을 하는 것도 가능합니다.
- Stacking several (usually four) subsequent frames together to give the network information about the dynamics of the game’s objects :
- 보통 4개 이어진 프레임을 엮어서 입력으로 사용하는 것.
- Clipping the reward to –1, 0, and 1 values :
- 보상의 범위를 -1 ~ 1로 제한. normalization 효과
- Converting observations from unsigned bytes to float32 value :
- 관찰값을 unsigned bytes에서 float32 로 형변환. emulator 출력값으로 0~255의 범위를 갖는 bytes tensor를 받는데 이는 뉴럴넷에 최적화된 값의 형태가 아니어서 float으로 바꾸고 0~1로 범위도 스케일링합니다.
아타리 게임에서 위에 나온 모든 wrapper를 쓰는 것이 아니더라도 wrapper를 알고 있으면 적절한 상황에서 적용 가능할 수 있어 유용합니다. 가끔 DQN이 수렴하지 않는 원인이 코드가 아니라 잘못된 환경설정 때문일 수 있습니다. 즉, wrapper를 잘 쓰는 것도 중요합니다.
이제 몇 개의 wrapper class 코드를 보며 어떻게 구현되었는지 살펴보겠습니다.
import cv2
import gym
import gym.spaces
import numpy as np
import collections
class FireResetEnv(gym.Wrapper):
def __init__(self, env=None):
"""For environments where the user need to press FIRE for the game to start."""
super(FireResetEnv, self).__init__(env)
assert env.unwrapped.get_action_meanings()[1] == 'FIRE'
assert len(env.unwrapped.get_action_meanings()) >= 3
def step(self, action):
return self.env.step(action)
def reset(self):
self.env.reset()
obs, _, done, _ = self.env.step(1)
if done:
self.env.reset()
obs, _, done, _ = self.env.step(2)
if done:
self.env.reset()
return obs
FireResetEnv wrapper class는 게임 시작을 위해 FIRE 버튼을 눌러야만 하는 조건을 init 함수에 명시하였습니다.
class MaxAndSkipEnv(gym.Wrapper):
def __init__(self, env=None, skip=4):
"""Return only every `skip`-th frame"""
super(MaxAndSkipEnv, self).__init__(env)
# most recent raw observations (for max pooling across time steps)
self._obs_buffer = collections.deque(maxlen=2)
self._skip = skip
def step(self, action):
total_reward = 0.0
done = None
for _ in range(self._skip):
obs, reward, done, info = self.env.step(action)
self._obs_buffer.append(obs)
total_reward += reward
if done:
break
max_frame = np.max(np.stack(self._obs_buffer), axis=0)
return max_frame, total_reward, done, info
def reset(self):
"""Clear past frame buffer and init. to first obs. from inner env."""
self._obs_buffer.clear()
obs = self.env.reset()
self._obs_buffer.append(obs)
return obs
MaxAndSkipEnv wrapper class는 K(=skip)개 만큼 관찰값을 쌓아서 max pooling한 값을 반환해줍니다.
class ProcessFrame84(gym.ObservationWrapper):
def __init__(self, env=None):
super(ProcessFrame84, self).__init__(env)
self.observation_space = gym.spaces.Box(
low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
def observation(self, obs):
return ProcessFrame84.process(obs)
@staticmethod
def process(frame):
if frame.size == 210 * 160 * 3:
img = np.reshape(frame, [210, 160, 3]).astype(
np.float32)
elif frame.size == 250 * 160 * 3:
img = np.reshape(frame, [250, 160, 3]).astype(
np.float32)
else:
assert False, "Unknown resolution."
img = img[:, :, 0] * 0.299 + img[:, :, 1] * 0.587 + \
img[:, :, 2] * 0.114
resized_screen = cv2.resize(
img, (84, 110), interpolation=cv2.INTER_AREA)
x_t = resized_screen[18:102, :]
x_t = np.reshape(x_t, [84, 84, 1])
return x_t.astype(np.uint8)
ProcessFrame84 wrapper class는 RGB 색상의 210x160 해상도를 갖는 픽셀 이미지를 grayscale 84x84 이미지로 변환해줍니다.
class BufferWrapper(gym.ObservationWrapper):
def __init__(self, env, n_steps, dtype=np.float32):
super(BufferWrapper, self).__init__(env)
self.dtype = dtype
old_space = env.observation_space
self.observation_space = gym.spaces.Box(
old_space.low.repeat(n_steps, axis=0),
old_space.high.repeat(n_steps, axis=0), dtype=dtype)
def reset(self):
self.buffer = np.zeros_like(
self.observation_space.low, dtype=self.dtype)
return self.observation(self.env.reset())
def observation(self, observation):
self.buffer[:-1] = self.buffer[1:]
self.buffer[-1] = observation
return self.buffer
BufferWrapper class는 0번째 차원에 연속된 프레임을 스택으로 쌓아 관찰값으로 반환합니다. 이렇게 하는 이유는 네트워크에게 그 물체의 동적인 움직임(예-Pong에서 볼의 속도와 방향 등)에 대한 정보를 주기 위함입니다. 이건 매우 중요한 정보이면서 단일 이미지로는 표현하기 어려운 정보입니다.
class ImageToPyTorch(gym.ObservationWrapper):
def __init__(self, env):
super(ImageToPyTorch, self).__init__(env)
old_shape = self.observation_space.shape
new_shape = (old_shape[-1], old_shape[0], old_shape[1])
self.observation_space = gym.spaces.Box(
low=0.0, high=1.0, shape=new_shape, dtype=np.float32)
def observation(self, observation):
return np.moveaxis(observation, 2, 0)
이 wrapper class는 관찰값 포맷을 (Height, Width, Channel) 에서 (Channel, Height, Width)로 바꿔줍니다. CHW는 PyTorch에서 요구하는 포맷입니다.
def make_env(env_name):
env = gym.make(env_name)
env = MaxAndSkipEnv(env)
env = FireResetEnv(env)
env = ProcessFrame84(env)
env = ImageToPyTorch(env)
env = BufferWrapper(env, 4)
return ScaledFloatFrame(env)
이 함수는 간단하게 모든 wrapper 를 환경에 적용하는 방법입니다. 이제는 DQN 모델에 대해 알아보겠습니다.
The DQN model
네이쳐지에 게재한 모델은 3개의 convolution layer에 2개의 fully connected layer를 이은 모델입니다. 모든 레이어는 ReLU를 활성화 함수로 쓰고 있습니다. (단, 모델의 출력값에는 비선형 활성화함수 적용 안 됨.) 네트워크의 하나의 패스로 모든 Q value를 계산하는 것은 Q(s,a)를 말그대로 관찰값과 행동을 입력으로 넣어 행동의 가치를 얻어내는 방식보다 속도가 훨씬 빠르다는 이점을 지닙니다.
모델 코드는 Chapter06/lib/dqn_model.py에 있습니다.
import torch
import torch.nn as nn
import numpy as np
class DQN(nn.Module):
def __init__(self, input_shape, n_actions):
super(DQN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(input_shape[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU()
)
conv_out_size = self._get_conv_out(input_shape)
self.fc = nn.Sequential(
nn.Linear(conv_out_size, 512),
nn.ReLU(),
nn.Linear(512, n_actions)
)
def _get_conv_out(self, shape):
o = self.conv(torch.zeros(1, *shape))
return int(np.prod(o.size()))
def forward(self, x):
conv_out = self.conv(x).view(x.size()[0], -1)
return self.fc(conv_out)
모델은 크게 convolution과 sequential 파트로 나뉘어져 있습니다. 두 파트간 요구하는 차원이 다르기 때문에 변환 과정이 필요하지만 PyTorch는 “flatter”(다차원 텐서를 1차원 벡터로 펴주는) layer가 없어서 forward()에서 view()를 이용해 reshape해줍니다. 4D 입력 텐서를 (배치 사이즈, 모든 패러미터 개수) 2D 텐서로 바꿔준 것입니다.
또한 convolution layer에서 나온 출력값이 linear layer의 입력값에 들어갈 때 사이즈를 모르기 때문에 계산하는 함수를 추가했습니다. _get_conv_out() 은 0으로 채워진 텐서를 집어넣어 직접 계산합니다. 이 부분은 tensorflow가 편해보이네요.
Training
세 번째 모듈은 experience replay buffer, agent, loss function, training loop를 포함한 학습 과정을 담고 있습니다. 코드를 보기 전에 학습 하이퍼패러미터에 대해 먼저 알아보겠습니다. 네이쳐지에 낸 논문에 모든 하이퍼패러미터 정보를 테이블로 정리되어 있습니다. 딥마인드에서는 이 모든 패러미터를 49종의 모든 아타리 게임에 동일하게 적용합니다. DQN이 각광받았던 이유 중 하나가 각기 다른 디테일을 지닌 게임에 대해 동일한 아키텍쳐와 하이퍼패러미터를 적용시켜 좋은 성능을 냈다는 점입니다. (학습은 모델별로 따로 진행.)
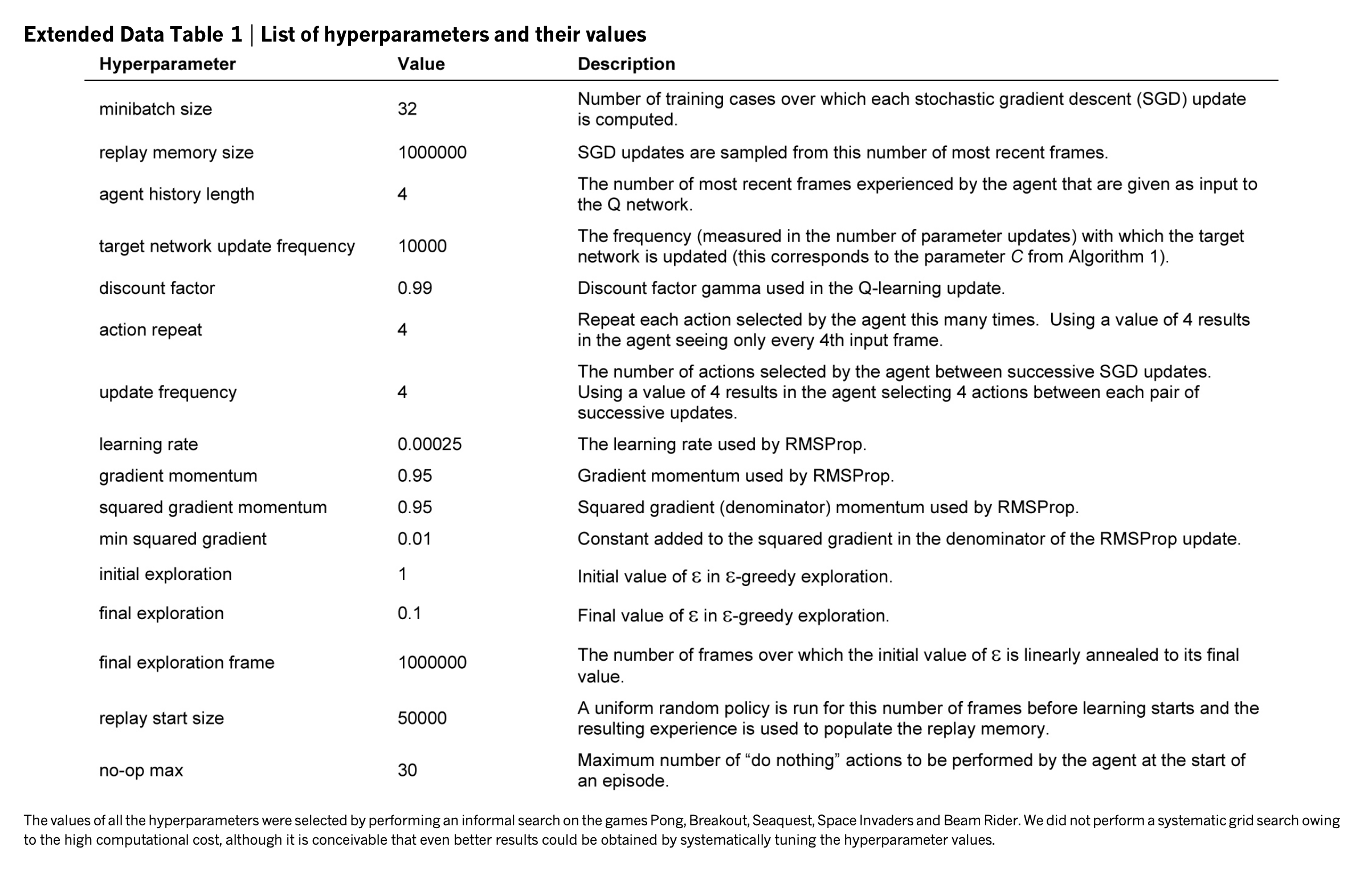
일단 이 챕터에서는 Pong game에 대해서만 다룰 예정입니다. Pong game이 다른 게임에 비해 심플하고 직선적이라서 위의 하이퍼패러미터 중 일부가 과다한 경향이 있습니다. 예를 들어, replay memory size를 백만으로 해놨는데 이는 20GB의 램이 필요합니다. Pong 게임과 같이 간단한 게임에는 과하게 메모리를 잡는 것이라 10K로 수정해서 사용했습니다.
원 논문에서는 처음 백만 프레임에서 epsilon을 1.0에서 0.1로 선형적으로 줄여나가는데 저자가 Pong game 실험해본 결과, 처음 150K 프레임까지는 엡실론을 줄여나가고 그 다음은 유지하는 것만으로도 충분하다는 결론을 지었습니다. 이렇게 했을 때, 원논문의 패러미터보다 10배 이상 수렴 속도가 빨랐다고 합니다. (GTX 1080i에서 수렴하는데 원 논문의 설정으로는 적어도 1일이 소요되었고, 새 설정으로는 1~2시간 정도 걸렸습니다. )
#!/usr/bin/env python3
from lib import wrappers
from lib import dqn_model
import argparse
import time
import numpy as np
import collections
import torch
import torch.nn as nn
import torch.optim as optim
from tensorboardX import SummaryWriter
# 환경 이름
DEFAULT_ENV_NAME = "PongNoFrameskip-v4"
# 학습 종료를 위한 마지막 100개 에피소드의 보상 평균 경계값
MEAN_REWARD_BOUND = 19
# 벨만 방정식 근사에서 사용하는 감마값
GAMMA = 0.99
# replay buffer로부터 표집한 batch size
BATCH_SIZE = 32
# replay buffer의 최대 용량
REPLAY_SIZE = 10000
# 학습을 시작하기 전에 replay buffer를 채우기 위해 기다리는 프레임 수
REPLAY_START_SIZE = 10000
# 학습률
LEARNING_RATE = 1e-4
# training model과 target model을 얼만큼의 주기로 동기화 시켜야 하는지
SYNC_TARGET_FRAMES = 1000
# epsilon 값은 1.0에서 시작하여 0.01로 줄여나간다.
# 150000 부터는 0.01로 유지
EPSILON_DECAY_LAST_FRAME = 150000
EPSILON_START = 1.0
EPSILON_FINAL = 0.01
다음은 replay buffer 에 대한 코드입니다. 주된 목적은 전이값들(현재 상태, 행동, 보상, done flag, 다음 상태)을 저장하는 것입니다. 학습할 때, 이 버퍼에서 램덤하게 배치사이즈만큼 표집합니다.
Experience = collections.namedtuple(
'Experience', field_names=['state', 'action', 'reward',
'done', 'new_state'])
class ExperienceBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def __len__(self):
return len(self.buffer)
def append(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
indices = np.random.choice(len(self.buffer), batch_size,
replace=False)
states, actions, rewards, dones, next_states = \
zip(*[self.buffer[idx] for idx in indices])
# loss function에 편리하기 위해 NumPy array로 변환
return np.array(states), np.array(actions), \
np.array(rewards, dtype=np.float32), \
np.array(dones, dtype=np.uint8), \
np.array(next_states)
다음은 에이전트입니다.
class Agent:
def __init__(self, env, exp_buffer):
self.env = env
self.exp_buffer = exp_buffer
self._reset()
def _reset(self):
self.state = env.reset()
self.total_reward = 0.0
@torch.no_grad()
def play_step(self, net, epsilon=0.0, device="cpu"):
done_reward = None
'''
epsilon 값이 1.0에서 시작해서 점점 작아지므로 처음에는 랜덤한 행동을 많이 뽑다가
점차 기존 경험에서 가장 좋은 행동을 선택한다.
'''
if np.random.random() < epsilon:
action = env.action_space.sample()
else:
state_a = np.array([self.state], copy=False)
state_v = torch.tensor(state_a).to(device)
q_vals_v = net(state_v)
_, act_v = torch.max(q_vals_v, dim=1)
action = int(act_v.item())
# do step in the environment
new_state, reward, is_done, _ = self.env.step(action)
self.total_reward += reward
# buffer에 저장
exp = Experience(self.state, action, reward,
is_done, new_state)
self.exp_buffer.append(exp)
self.state = new_state
if is_done:
done_reward = self.total_reward
self._reset()
return done_reward
def calc_loss(batch, net, tgt_net, device="cpu"):
# loss function 계산의 기본은 Deep Q-learning 세션에서 다룬 식과 동일합니다.
# net : 학습 네트워크, gradient 계산하는데 사용
# tgt_net : target network, 다음 상태를 위한 가치 계산하는데 사용. 이 과정은 gradient에 영향을 주면 안됨.
# 기존 Tensor에서 gradient 전파가 안되는 텐서 생성하기 위해 .detach() 사용
states, actions, rewards, dones, next_states = batch
# tensor로 변환
states_v = torch.tensor(np.array(states, copy=False)).to(device)
next_states_v = torch.tensor(np.array(
next_states, copy=False)).to(device)
actions_v = torch.tensor(actions).to(device)
rewards_v = torch.tensor(rewards).to(device)
done_mask = torch.BoolTensor(dones).to(device)
# 학습 네트워크에 관찰값을 입력으로 넣어 행동에 따른 Q값을 추출한다.
# .gather의 첫 번째 argument는 모으고 싶은 차원 인덱스를 뜻한다. 1이 행동이다.
# .gather의 두 번째 argument는 선택한 요소의 인덱스에 해당하는 텐서입니다.
# figure 6.3이 gather()의 프로세스를 간단히 보여줍니다.
state_action_values = net(states_v).gather(
1, actions_v.unsqueeze(-1)).squeeze(-1)
# gradient 계산에 영향을 안 주기 위해서 적용
with torch.no_grad():
# 타켓 네트워크에 다음 상태를 입력으로 주고
# action(dim=1)에 대해 다음 상태에서의 최대 Q값을 계산한다.
# .max()은 최대 값과 인덱스 둘 다 반환해서 편리하다. 0을 선택한건 값만 사용하겠다는 의미
next_state_values = tgt_net(next_states_v).max(1)[0]
''' 중요 포인트!!
에피소드의 마지막 단계에서 transition이 시작되면 다음 상태가 없기 때문에 행동의 가치는 다음 상태에 대한 할인된 보상이 없습니다.
이것은 사소한 것처럼 보일 수 있지만 매우 중요합니다. 그래서 아래처럼 처리를 해주어야 합니다. 이것이 없으면 학습이 수렴되지 않습니다.
'''
next_state_values[done_mask] = 0.0
# gradient 전파가 안되는 텐서 복사
next_state_values = next_state_values.detach()
# 벨만 근사
expected_state_action_values = next_state_values * GAMMA + \
rewards_v
# Mean Squared Error loss
# 학습 네트워크의 값과 타켓 네트워크의 값 비교
return nn.MSELoss()(state_action_values,
expected_state_action_values)
아래 figure 6.3은 4개의 행동과 6개의 배치가 있다고 할 때, gather() 이 어떤 과정인지 보여줍니다.
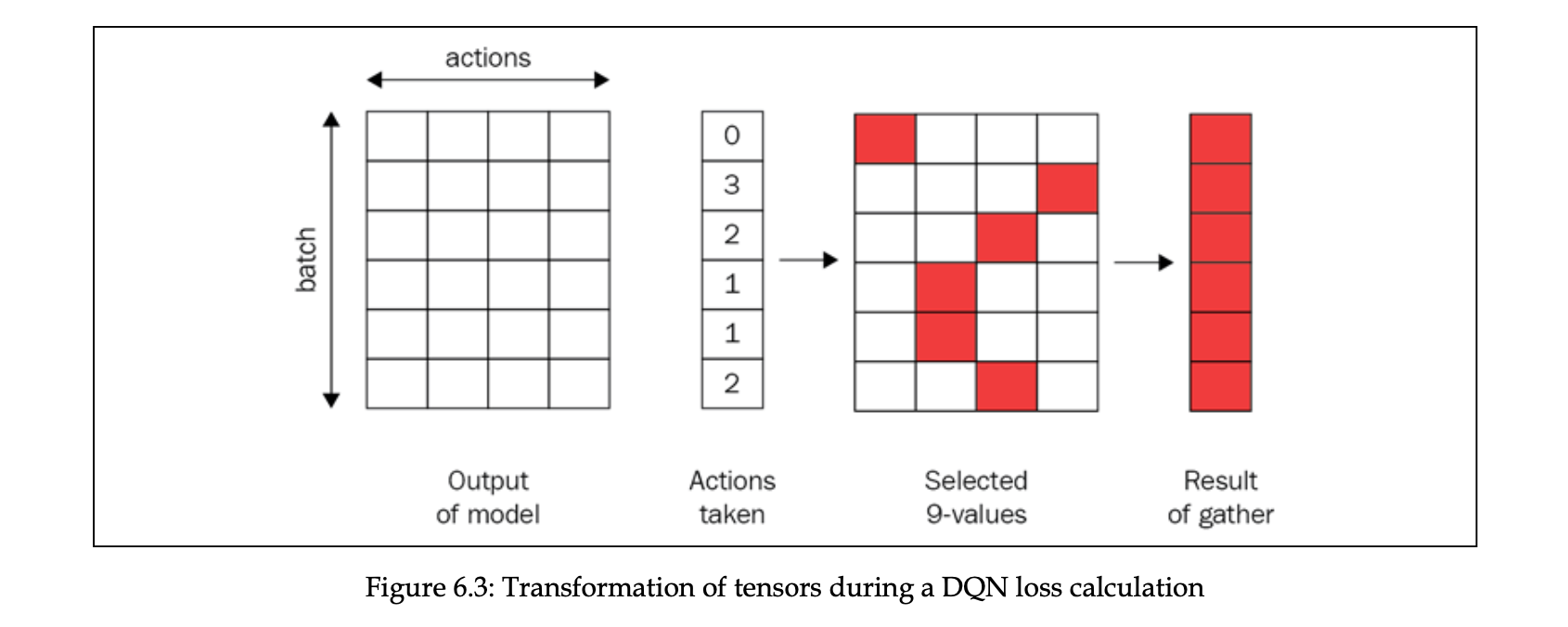
다음은 메인함수입니다.
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--cuda", default=False,
action="store_true", help="Enable cuda")
parser.add_argument("--env", default=DEFAULT_ENV_NAME,
help="Name of the environment, default=" +
DEFAULT_ENV_NAME)
args = parser.parse_args()
device = torch.device("cuda" if args.cuda else "cpu")
env = wrappers.make_env(args.env)
# 학습 네트워크와 타켓 네트워크의 아키텍처는 동일
net = dqn_model.DQN(env.observation_space.shape,
env.action_space.n).to(device)
tgt_net = dqn_model.DQN(env.observation_space.shape,
env.action_space.n).to(device)
writer = SummaryWriter(comment="-" + args.env)
# 네트워크 구조 출력
print(net)
# buffer, agent 인스턴스 생성
buffer = ExperienceBuffer(REPLAY_SIZE)
agent = Agent(env, buffer)
# 엡실론 초기값(1.0) 설정
epsilon = EPSILON_START
optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE)
total_rewards = []
frame_idx = 0
ts_frame = 0
ts = time.time()
best_m_reward = None
while True:
frame_idx += 1
epsilon = max(EPSILON_FINAL, EPSILON_START -
frame_idx / EPSILON_DECAY_LAST_FRAME)
# 엡실론 값에 따라 최적 혹은 랜덤 행동을 하고 그에 따른 결과값을 버퍼에 저장한다.
reward = agent.play_step(net, epsilon, device=device)
if reward is not None:
total_rewards.append(reward)
# 각 단계마다 소요 시간 체크
speed = (frame_idx - ts_frame) / (time.time() - ts)
ts_frame = frame_idx
ts = time.time()
# 최근 보상값 최대 100개까지의 평균
m_reward = np.mean(total_rewards[-100:])
print("%d: done %d games, reward %.3f, "
"eps %.2f, speed %.2f f/s" % (
frame_idx, len(total_rewards), m_reward, epsilon,
speed
))
writer.add_scalar("epsilon", epsilon, frame_idx)
writer.add_scalar("speed", speed, frame_idx)
writer.add_scalar("reward_100", m_reward, frame_idx)
writer.add_scalar("reward", reward, frame_idx)
# 최고 보상 평균이 없거나 현재 보상 평균보다 작으면 학습 네트워크 저장
if best_m_reward is None or best_m_reward < m_reward:
torch.save(net.state_dict(), args.env +
"-best_%.0f.dat" % m_reward)
if best_m_reward is not None:
print("Best reward updated %.3f -> %.3f" % (
best_m_reward, m_reward))
best_m_reward = m_reward
# 현재 보상 평균이 보상 평균 경계값을 넘어서면 문제 풀이 종료
if m_reward > MEAN_REWARD_BOUND:
print("Solved in %d frames!" % frame_idx)
break
if len(buffer) < REPLAY_START_SIZE:
continue
# SYNC_TARGET_FRAMES 스텝마다 학습 네트워크와 타켓 네트워크 동기화
if frame_idx % SYNC_TARGET_FRAMES == 0:
tgt_net.load_state_dict(net.state_dict())
optimizer.zero_grad()
batch = buffer.sample(BATCH_SIZE)
# loss 계산
loss_t = calc_loss(batch, net, tgt_net, device=device)
loss_t.backward()
optimizer.step()
writer.close()
Running and performance
Pong game에서 보상 평균이 17점(80% 성공) 정도 되려면 400K 프레임이 필요합니다. 책의 저자는 GTX 1080 ti로 학습시켜서 2시간 걸렸다고 합니다.
제가 올려놓은 환경은 GTX 3090이니 더 빠르지 않을까 싶습니다.
챕터8에서는 학습 속도를 높이고 데이터 효율성을 높이는 다양한 접근법에 대해서 다룰 것이고 챕터9에서는 학습 속도를 높이는 엔지니어링 트릭에 대해 알아볼 것입니다.
figure 6.4는 시간에 따라 최근 100개의 에피소드 보상 평균이 어떻게 변화되는지 보여줍니다.
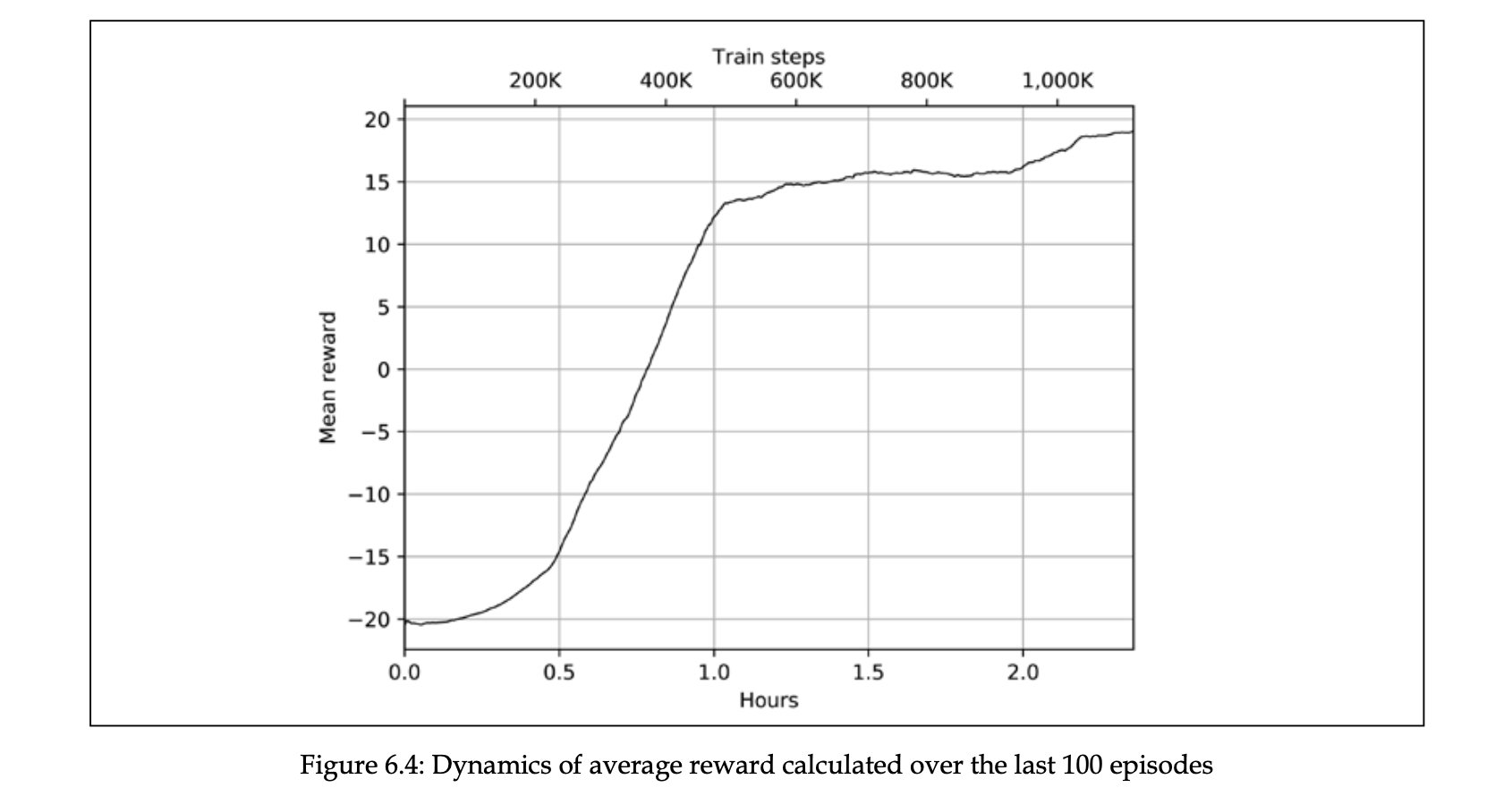
다음은 코드 실행의 초기 결과값들입니다.
~/Chapter06$ python 02_dqn_pong.py --cuda
DQN(
(conv): Sequential(
(0): Conv2d(4, 32, kernel_size=(8, 8), stride=(4, 4))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2))
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(5): ReLU()
)
(fc): Sequential(
(0): Linear(in_features=3136, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=6, bias=True)
)
)
958: done 1 games, reward -20.000, eps 0.99, speed 1183.42 f/s
1806: done 2 games, reward -20.500, eps 0.99, speed 1171.71 f/s
3083: done 3 games, reward -20.333, eps 0.98, speed 1180.97 f/s
3970: done 4 games, reward -20.250, eps 0.97, speed 1182.29 f/s
4900: done 5 games, reward -20.200, eps 0.97, speed 1171.93 f/s
5812: done 6 games, reward -20.333, eps 0.96, speed 1168.39 f/s
6680: done 7 games, reward -20.286, eps 0.96, speed 1158.59 f/s
7530: done 8 games, reward -20.375, eps 0.95, speed 1149.22 f/s
8352: done 9 games, reward -20.444, eps 0.94, speed 1153.33 f/s
9276: done 10 games, reward -20.400, eps 0.94, speed 1142.67 f/s
10117: done 11 games, reward -20.455, eps 0.93, speed 586.96 f/s
11057: done 12 games, reward -20.500, eps 0.93, speed 147.79 f/s
11897: done 13 games, reward -20.462, eps 0.92, speed 147.96 f/s
12699: done 14 games, reward -20.500, eps 0.92, speed 148.66 f/s
(...생략...)
처음에는 초당 1000개 넘는 프레임을 처리하다가 후반부로 갈수록 140 개의 프레임을 처리하고 있습니다. GTX 1080에서는 평균 120개라고 했으니 20개 정도의 차이가 납니다.
10k미만에서 빠른 이유는 10K 프레임까지는 학습하지 않고 기다리기 때문입니다.
랜덤한 값 때문에 수렴하지 않을 수도 있으니 100k~200k 프레임인데 -21의 보상을 유지하고 있으면 재실행해야 한다고 합니다.
책의 저자는 1,116,437 번째 프레임에서 문제가 풀렸습니다.
Your model in action
학습 과정은 전체의 반 밖에 오지 않았습니다. 저희의 목적은 모델 학습 뿐만 아니라 이 모델로 게임하여 좋은 결과를 내는 것입니다. 앞선 코드에서 최신 100개 에피소드의 보상 평균이 갱신될 때마다 모델을 “PongNoFrameskip-v4-best.dat”에 저장하였습니다.
Chapter06/03_dqn_play.py 에서는 모델 파일을 로드해서 하나의 에피소드를 플레이할 것입니다. 코드는 매우 간단하지만, 백만 개의 매개변수를 가진 여러 매트릭스가 픽셀만 관찰하여 초인적인 정확도로 Pong game을 플레이하는 모습을 볼 수 있습니다.
#!/usr/bin/env python3
import gym
import time
import argparse
import numpy as np
import torch
from lib import wrappers
from lib import dqn_model
import collections
DEFAULT_ENV_NAME = "PongNoFrameskip-v4"
# Frames Per Second
FPS = 25
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# 2번째 코드에서 얻은 모델을 명시한다.
parser.add_argument("-m", "--model", required=True,
help="Model file to load")
parser.add_argument("-e", "--env", default=DEFAULT_ENV_NAME,
help="Environment name to use, default=" +
DEFAULT_ENV_NAME)
parser.add_argument("-r", "--record", help="Directory for video")
parser.add_argument("--no-vis", default=True, dest='vis',
help="Disable visualization",
action='store_false')
args = parser.parse_args()
env = wrappers.make_env(args.env)
if args.record:
env = gym.wrappers.Monitor(env, args.record)
# 모델 로드
net = dqn_model.DQN(env.observation_space.shape,
env.action_space.n)
state = torch.load(args.model, map_location=lambda stg, _: stg)
net.load_state_dict(state)
state = env.reset()
total_reward = 0.0
c = collections.Counter()
while True:
start_ts = time.time()
if args.vis:
env.render()
state_v = torch.tensor(np.array([state], copy=False))
q_vals = net(state_v).data.numpy()[0]
action = np.argmax(q_vals)
c[action] += 1
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
if args.vis:
delta = 1/FPS - (time.time() - start_ts)
if delta > 0:
time.sleep(delta)
print("Total reward: %.2f" % total_reward)
print("Action counts:", c)
if args.record:
env.env.close()
https://youtu.be/q0gpmViAuho 는 유튜브에 게임 영상을 올린 것입니다.
Summary
- 큰 observation space를 가진 복잡한 환경에서 value iteration의 한계점과 그 한계점을 Q-learning으로 어떻게 극복하는지 알아보았습니다.
- FrozenLake 환경에서 Q-learning이 어떻게 작동하는지 간단히 알아보았고 뉴럴넷을 사용한 Q-value 근사에 대해 논의했습니다.
- DQN의 학습 안정성과 수렴을 향상시키기 위한 몇 가지 트릭(experience replay buffer, target networks, frame stacking)에 대해 다뤘습니다.
- 이 트릭들과 배운 것을 총괄하여 Pong 환경에서 DQN을 학습하고 게임 플레이를 해보았습니다.
다음 챕터에서는 고수준 강화학습 라이브러리(특히 PTAN)에 대해 다뤄보도록 하겠습니다.
References
- Deep Reinforcement Learning Hands On 2/E Chapter 06 : Deep Q-Networks
- https://talkingaboutme.tistory.com/entry/RL-Off-policy-Learning-for-Prediction
- https://mangkyu.tistory.com/61
- https://electronicsdo.tistory.com/entry/independent-identically-distribution-%EB%8F%85%EB%A6%BD-%EB%8F%99%EC%9D%BC-%EB%B6%84%ED%8F%AC