
Authors : Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai, Yi Zhang
Institution : University of Cambridge, Amazon AWS AI, The Chinese University of Hong Kong
Publication Date : Sep 29, 2021
Paper link : https://arxiv.org/pdf/2109.14739.pdf
Github : https://github.com/awslabs/pptod
발표장표 : 구글드라이브
Abstract
사전학습 모델을 사용하는 것은 Task-Oriented Dialogue(TOD) system 성능 향상에 많은 도움을 주었습니다. 그러나 기존 방법들은 종종 TOD 과제에 cascade generation 문제를 만듭니다. 이는 서로 다른 하위 과제에서 오류를 누적, 전파하고 학습 데이터를 만들기 위해 데이터에 주석을 다는 것이 복잡해져서 오버헤드를 증가시킬 수 있습니다.
이 논문에서는 위 문제를 해결하고자 PPTOD 를 제안합니다.
- PPTOD (Plug-and-Play model for Task-Oriented Dialogue)
- 이질적인 대화 말뭉치들로부터 주요한 TOD 과제 완성 스킬을 모델이 학습할 수 있도록 하는 새로운 대화 multi-task 사전학습 전략을 소개
- tod 의 대표적인 3개 벤치마크 과제인 end-to-end dialogue modeling, DST, 인텐트 분류를 대상으로 모델을 테스트
- 실험 결과, PPTOD 는 high-resource, low-resource 상황에서 모두 SOTA 를 기록
- PPTOD의 답변은 기존 SOTA 방법들과 비교해서도 더 높은 정확도를 보이고 인간 어노테이터가 의미적으로 더 일관성 있다고 판단함.
1 Introduction
배경
TOD 는 보통 3개의 하위 과제로 구성됩니다.
- Dialogue State Tracking(DST): 사용자의 belief state 를 추적하는 것
- Dialogue Policy Learning(POL): agent 대답 예측
- Natural Language Generation(NLG): 대화 응답 생성
TOD 접근 방법
- modularized pipeline : 하위 과제들을 구분된 모듈로 각기 처리하며 이를 파이프라인 형태로 엮음
- 모든 기능들을 뉴럴넷으로 통합하는 방법
- PLM 에 기반한 각기 다른 기능을 하는 시스템
- 대부분 cascade generation problem 일으킴
- 모델은 이전 하위 과제의 결과에 따라 그 다음 하위 과제를 풀 수 있음.
- 예를 들어, NLG 는 이전 과제인 DST 와 POL 의 결과에 의존한다.
- cascaded formulation 의 3가지 주요 한계점
- 모델이 순차적으로 하위 과제를 풀면, 이전 스텝에서의 축적된 에러가 다음 스텝으로 전파된다.
- 학습 데이터가 모든 하위 과제를 위해서 주석 처리가 되어있어야 한다.
- 주석을 위한 큐레이션에 보다 큰 자원이 투입될 여지 큼.
- 부분적으로 주석이 달린 많은 데이터는 사용하기 어려움.
- 하위 과제의 결과들은 지정된 순서대로 생성되어야 하기 때문에 불가피하게 inference 대기시간이 길어진다.
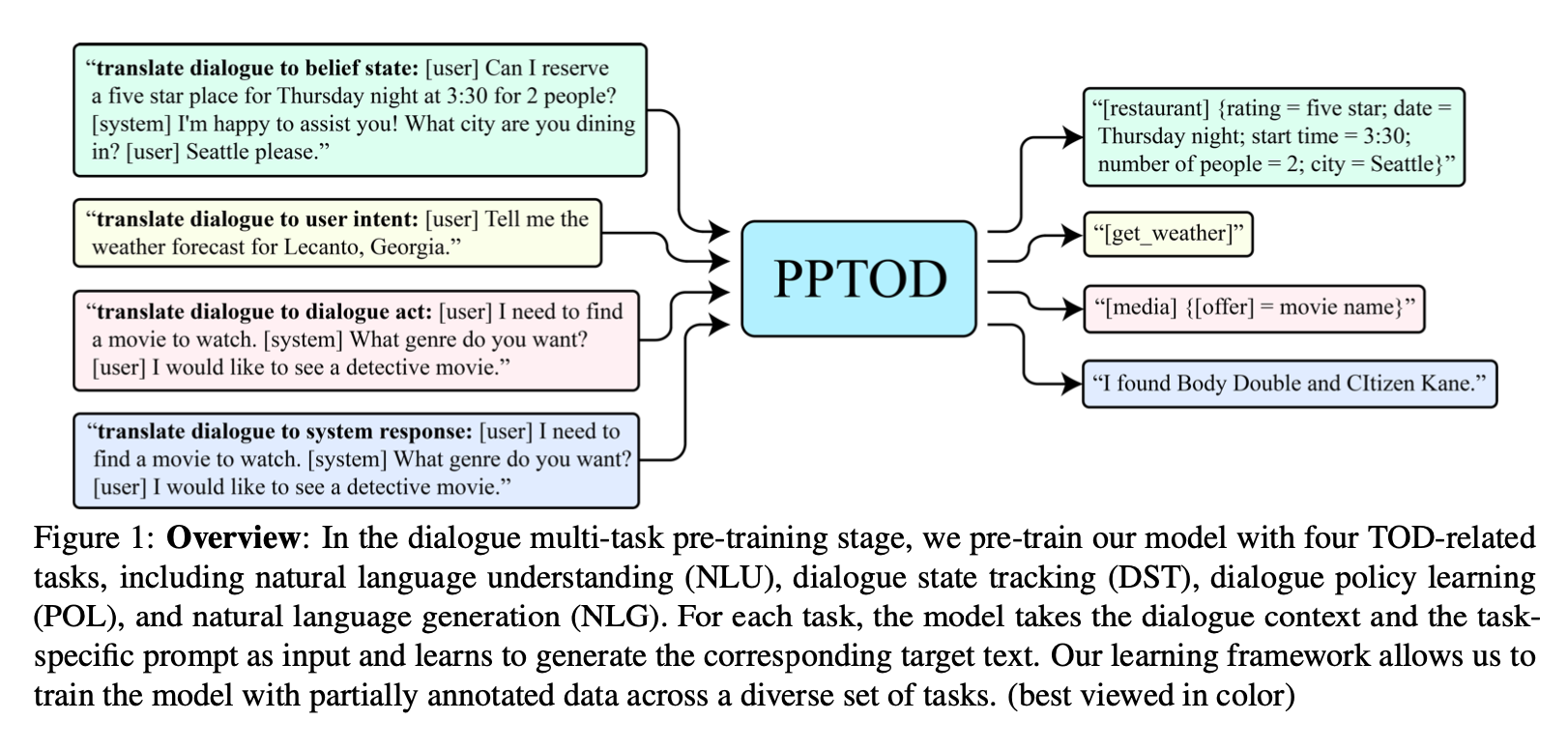
Figure 1 은 PPTOD 의 접근 방식을 표현한 것입니다. 다른 대화 모듈들(DST, POL, NLG)을 단일 모델로 통합했습니다. in-context learning 개념에 영감을 받아, 모델이 서로 다른 TOD 과제들을 풀 수 있도록 조종하기 위해, 특정 과제의 자연어 지시사항(prompt)을 모델 입력으로서 대화 맥락에 꽂았습니다(plug).
하위 과제들을 분리해낸 이 방식은 적어도 두 가지의 장점을 가져옵니다.
- 별개의 하위 과제들이 개별로 풀리면, 모델은 각 과제만을 위해 주석이 달린 데이터로부터 학습할 수 있다.
- 각 하위 과제들의 출력값은 병렬적으로 생성될 수 있다. 이는 에러 축적 문제를 경감시키고 시스템 예측 대기시간을 줄일 수 있다.
대화 언어 모델의 사전학습의 성공에 영감을 받아, 이 연구자들도 대화의 멀티 태스크 사전학습 전략을 제안했습니다. 그것은 모델로 하여금 주요 TOD 과제 완성 스킬을 갖추도록 한 것입니다.
부분적으로 주석이 달린 데이터로 구성된 이종의 대화 말뭉치들로 모델을 사전학습(T5)시켰습니다. 사전학습 말뭉치들을 만들기 위해, 인간이 쓴 11개의 멀티턴 대화 말뭉치를 모아 결합했습니다. 이 데이터들을 TOD 하위 과제들을 위해서 일부 주석이 달려있습니다. 사전학습 말뭉치 전체는 80개 도메인 이상에서 2.3M 개 이상의 발화를 포함하고 있습니다. 사전학습한 PPTOD 를 새로운 과제에 적용시킬 때, 사전학습 단계에서 사용한 목적함수를 동일하게 사용하여 파인튜닝했습니다.
PPTOD 검증을 위해 3가지 벤치마크 TOD 과제를 준비했습니다. (end-to-end dialogue modelling, DST, intent classification) 이전 SOTA 접근법과 비교해보면, PPTOD 는 데이터가 많을 때, 적을 때 모든 상황에서 자동, 인간 평가 모두에게 더 높은 성능을 보였습니다.
Contributions
- TOD 를 위해 사전학습 모델을 효과적으로 사용하는 PPTOD 라는 새로운 모델 제안
- 이종의 대화 말뭉치들에서 모델의 능력을 향상시키는 대화 멀티 태스크 사전학습 전략 제안
- 데이터가 적고 많을 때 모두와 모든 TOD 벤치마크 과제에서 SOTA
- PPTOD 와 새로운 사전학습 전략에 대해 심도있는 분석함
2 Related work
Task-Oriented Dialogues
생략
Language Model Pre-training
생략
Pre-training on Supplementary Data
최근 연구에서 부분 레이블이 달린 데이터로 추가로 그 과제에 대해 학습한 것이 GLUE nlu benchmark 성능을 개선시킨다는 것이 나타났습니다. 이 논문은 부분 레이블이 담긴 데이터로 추가 학습한다는 셋업과 유사한 면이 있습니다. 이전 연구와 본 연구의 차이는 PPTOD 는 TOD 하위 과제들을 위해 단일한 모델을 사용한다는 점입니다.
3 Methodology
이 섹션에서는 사전학습에서 사용한 데이터와 목적 함수에 대해 다루도록 하겠습니다.
3.1 Pre-training Datasets
- 11개의 멀티턴 TOD 말뭉치들
- MetaLWOZ, SNIPS, CLINC, ATIS, KVRET, WOZ, CamRest676, MSR-E2E, Frames, TaskMaster, Schema-Guided
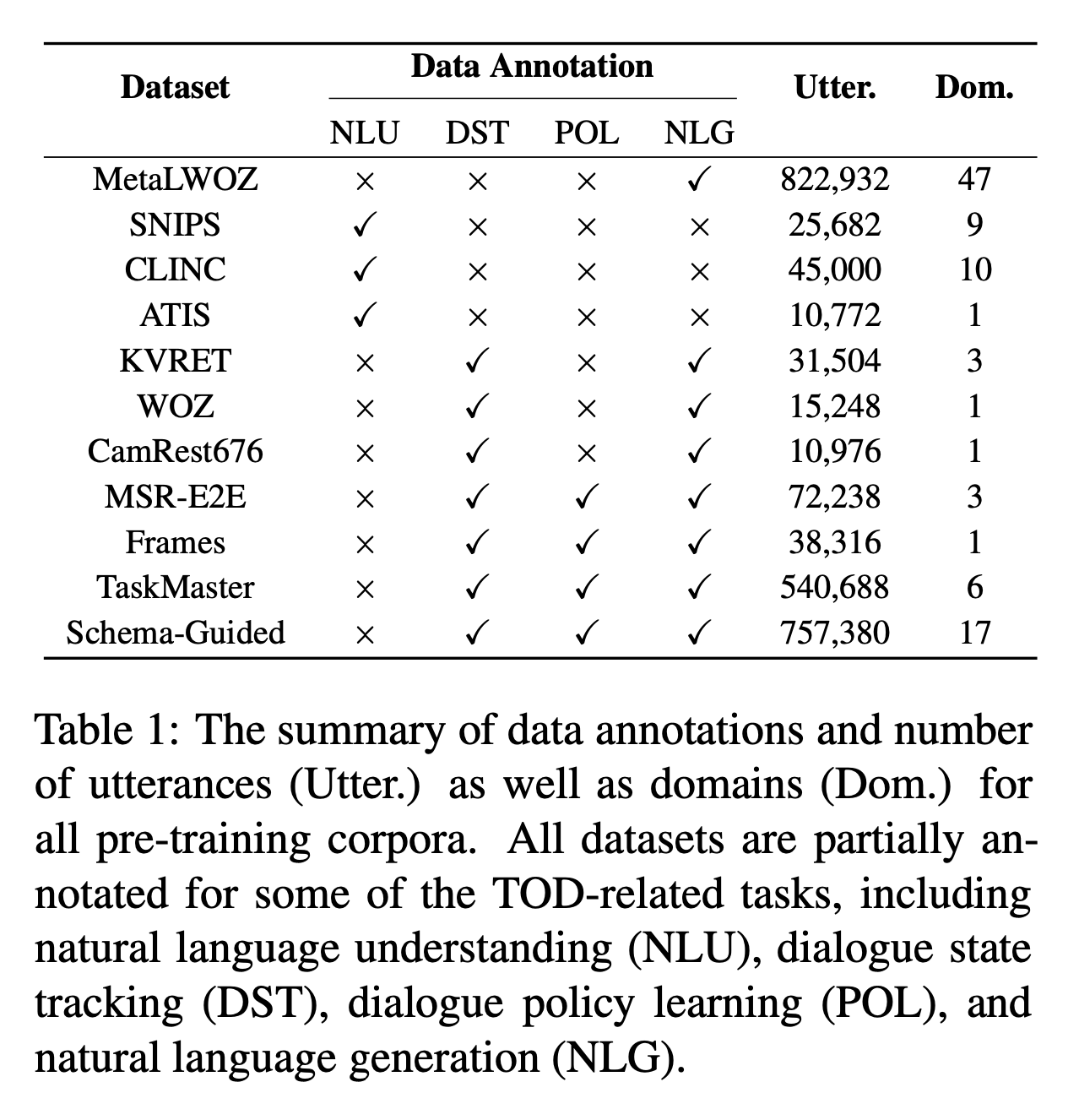
- 80 개 도메인 이상, 2.3M 개 발화 이상
- Table 1 에서 발화 개수와 도메인 개수, 레이블 작업이 어떤 과제로 되어있는지 확인 가능
3.2 Dialogue Multi-Task Pre-training
여러 NLP 과제들을 공통의 포맷으로 통합한 이전 연구들에 추진을 받아서, 모든 TOD 관련 과제를 합쳐서 plug-and-play text generation 문제로 만들었습니다. 특정 과제를 지정하려면, 특정 과제의 프롬프트(그 과제의 지시사항)를 모델 입력으로서 대화 맥락에 꽂으면 됩니다.
multi-task pre-training 단계에서 각 학습 샘플은 다음과 같이 표현됩니다.
(1) \(d = (z_t, x, y)\)
- \(t\) 는 샘플 d 가 속한 TOD 과제(task)를 나타내고, NLU, DST, POL, NLG 중 하나입니다.
- \(z_t\) 는 특정 과제의 프롬프트이고 “translate dialogue to A:” 라는 포맷을 가집니다. (A는 과제마다 달라진다.)
- NLU 에서는 “user intent”, DST 에서는 “belief state”, POL 에서는 “dialogue act”, NLG 에서는 “system response” 입니다.
- \(x\) 는 input dialogue context 이며, 이전 에이전트와 사용자의 발화 모두를 이은 것입니다.
- \(y\) 는 target output text 입니다.
figure 1 을 보면, 인텐트 분류 과제를 수행하기 위해서, 모델은 “translate dialogue to user intent: [user] Tell me the weather forecast for Lecanto, Georgia.” 라는 시퀀스를 입력으로 받고 사용자 인텐트 레이블 텍스트인 “[get_weather]”를 생성하기 위해 학습됩니다.
학습
모델 학습을 위해 maximum likelihood objective 함수를 사용합니다.
학습 샘플 \(d = (z_t, x, y)\) 가 주어진 상황에서, objective \(L_{\Theta}\) 는 다음과 같이 정의됩니다.
(2)
\(L_{\Theta} = -\sum_{i=1}^{|y|} log P_{\Theta} (y+i|y_{<i};z_t, x),\)
- \(\Theta\) 는 모델 패러미터
멀티 태스크 사전학습 단계에서 모델은 모든 TOD 과제들을 각 과제를 위해 주석이 달린 데이터로 학습을 진행합니다.
모델 패러미터를 최적화하기 위해, 미니 배치 방식을 사용합니다.

3.3 Fine-Tuning to a New Task
사전학습한 PPTOD 를 특정 과제에 맞는 데이터를 가지고 새로운 다운스트림 과제에 맞게 학습시킬 때, 사전학습 단계에서 사용한 목적 함수(식2)를 동일하게 사용합니다.
3.4 Implementation Details
모델 사이즈에 따라 결과를 보고하였습니다.
- 사이즈는 small, base, large 입니다.
- 각각은 T5-small, T5-base, T5-large 모델로 초기화되었습니다.
- ~60M, ~220M, ~770M 개의 패러미터를 지니고 있습니다.
- 사전 학습
- epochs: 10
- optimizer: Adam
- learning rate: 5e-5
- batch size: 128
- 구현은 Huggingface 기반으로 만들었습니다.
4 Experiments
PPTOD 를 3개의 벤치마크 과제로 테스트하였습니다.
- end-to-end dialogue modeling
- dialogue state tracking
- user intent classification
4.1 End-to-End Dialogue Modeling
- PPTOD 검증 1번째 과제 - End-to-End Dialogue Modeling
End-to-End Dialogue Modeling 은 가장 현실적이고 완전히 end-to-end 설정에서 모델을 검증하는 작업입니다.
이는 생성된 dialogue states 를 데이터베이스 검색과 응답 생성에 사용한다는 것을 의미합니다.
4.1.1 Dataset and Evaluation Metric
- 검증 데이터셋: MultiWOZ 2.0 & 2.1 datasets
- process
- inference 하는 동안, PPTOD 는 DST 수행
- dialogue state 활용하여 DB state 를 추출
- 추출된 DB state 와 대화 맥락에 기반하여, POL 과 NLG 를 동시에 수행
- 대화 맥락 뿐만 아니라 사전 구축되어 있는 데이터베이스로부터도 정보를 얻을 수 있다는 특징!
- Evaludation Metric
- 검증을 위해 원래 MultiWOZ 가이드에 있는 메트릭을 모두 사용
- Inform: 시스템이 적절한 entity 를 제공했는지
- Success: 시스템이 모든 요구하는 속성에 대답을 했는지
- BLEU score - fluency 판단에 사용
- 최종 결합된 점수(combined score)는 다음과 같이 계산
- Combined = (Inform + Success) x 0.5 + BLEU
- 검증을 위해 원래 MultiWOZ 가이드에 있는 메트릭을 모두 사용
4.1.2 Baselines
비교군으로 11개의 베이스라인을 선정
- Sequicity, MD-Sequicity, DAMD, MinTL, HIER-Joint, SOLOIST, TOP, TOP+NOD, LABES-S2S, UBAR, SimpleTOD
4.1.3 Full Training Evaluation
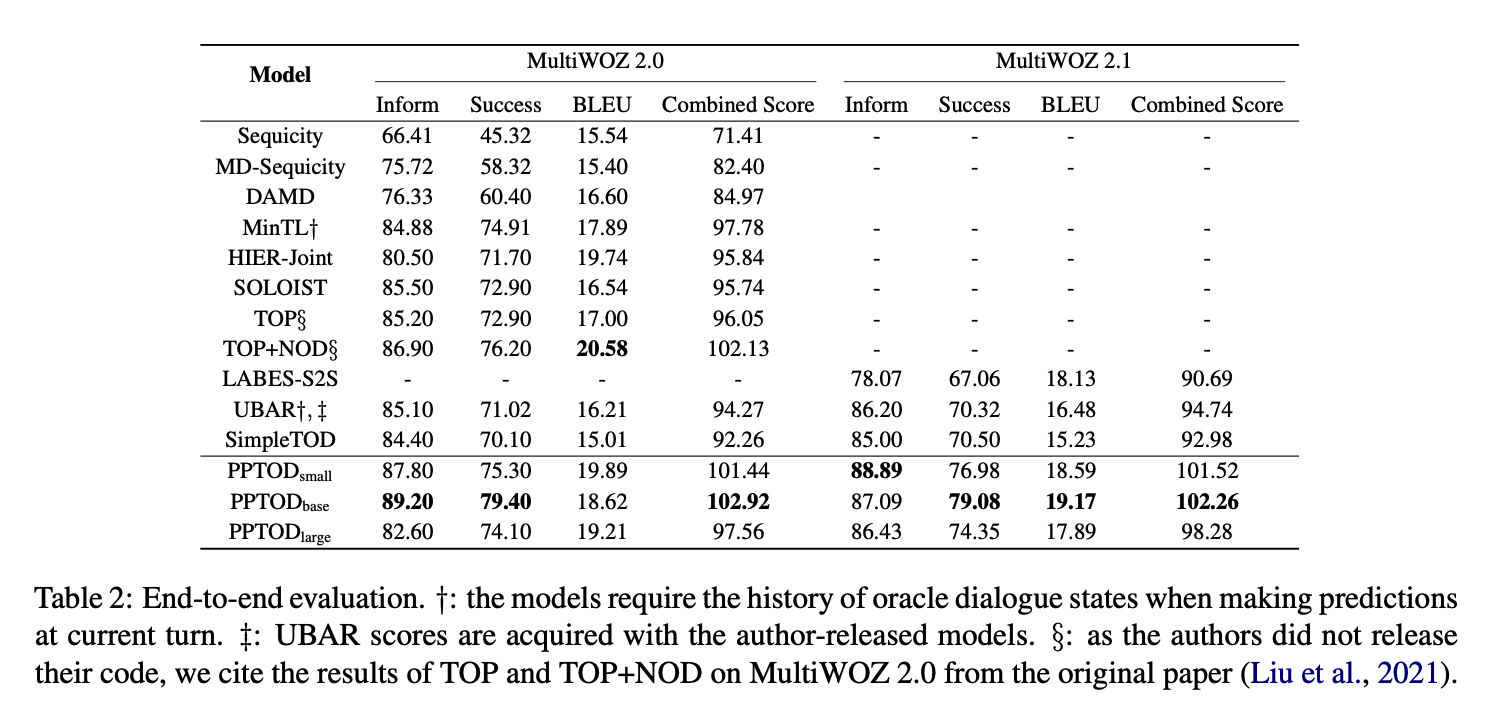
- table 2 : 주요 실험 결과
- MultiWOZ 2.0, 2.1 모두에서 PPTOD 는 8개의 메트릭 중 7개에서 다른 베이스라인 모델들보다 성능이 좋다.
- TOP+NOD 는 출력값을 re-ranking 하기 위해 추가적인 언어 모델을 요구하지만 PPTOD 는 유사성능을 내면서도 단일 모델
4.1.4 Few-Shot Evaluation
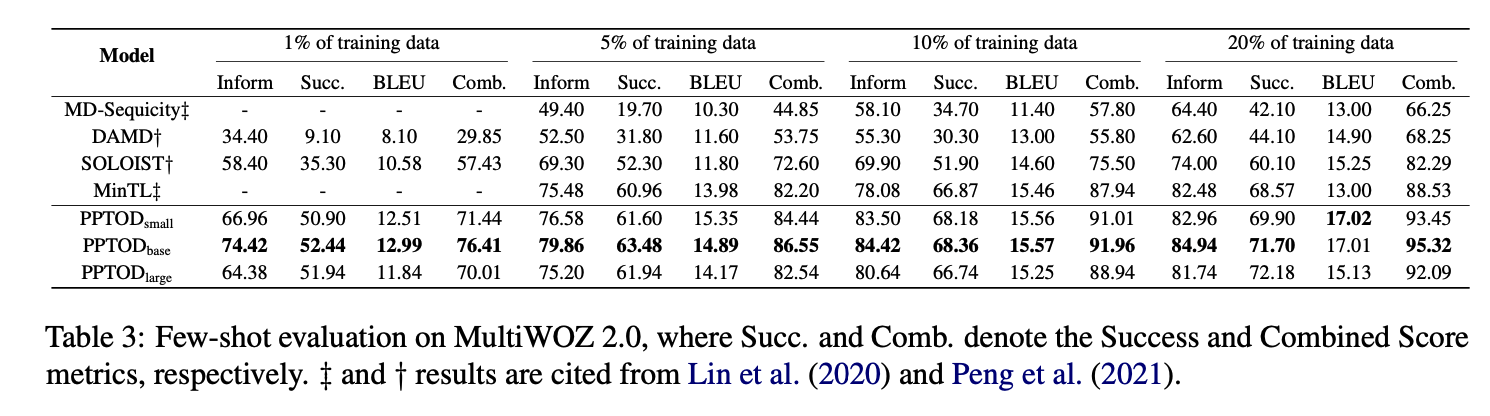
- PPTOD 의 일반화 능력을 알아보기 위해 더 현실적인 상황인 데이터가 부족할 때의 상황에서의 성능을 확인한 것이 table 3
- MultiWOZ 2.0 의 학습 데이터셋을 전체의 1%(~ 80개) 에서 20%(~1600개) 정도로 구성
- MD-Sequicity, DAMD, SOLOIST, and MinTL 을 대상으로 비교
- TOP+NOD 의 경우 코드와 사전학습 모델이 공개되어 있지 않아서 비교 불가
- table 3 결과는 5번 수행하여 나온 결과의 평균값
- 다른 랜덤 시드 사용
- 각기 다른 학습 데이터
- 결과는 PPTOD 가 다른 베이스라인보다 꽤 큰 차이로 점수가 높은 편
- 데이터가 적을 때 차이가 더 크다
- PPTOD 가 사전학습으로부터 나온 사전 지식을 더 잘 활용하기 때문에 극단적으로 데이터가 적은 상황에서 성능이 더 높은 것이다.
- 학습데이터로 데이터의 20%를 사용했을 때, PPTOD 는 (table 2) SOLOIST가 전체 데이터로 학습한 성능에 가깝게 수치를 보였다.
4.2 Dialogue State Tracking
- PPTOD 검증 2번째 과제 - DST
- 앞서와 같이 MultiWOZ 2.0, 2.1 데이터셋 사용
- metric : joint goal accuracy
4.2.1 Baselines
두 종류의 베이스라인
- 분류 기반 접근법
- 생성 기반 접근법
4.2.2 Full Training Evaluation
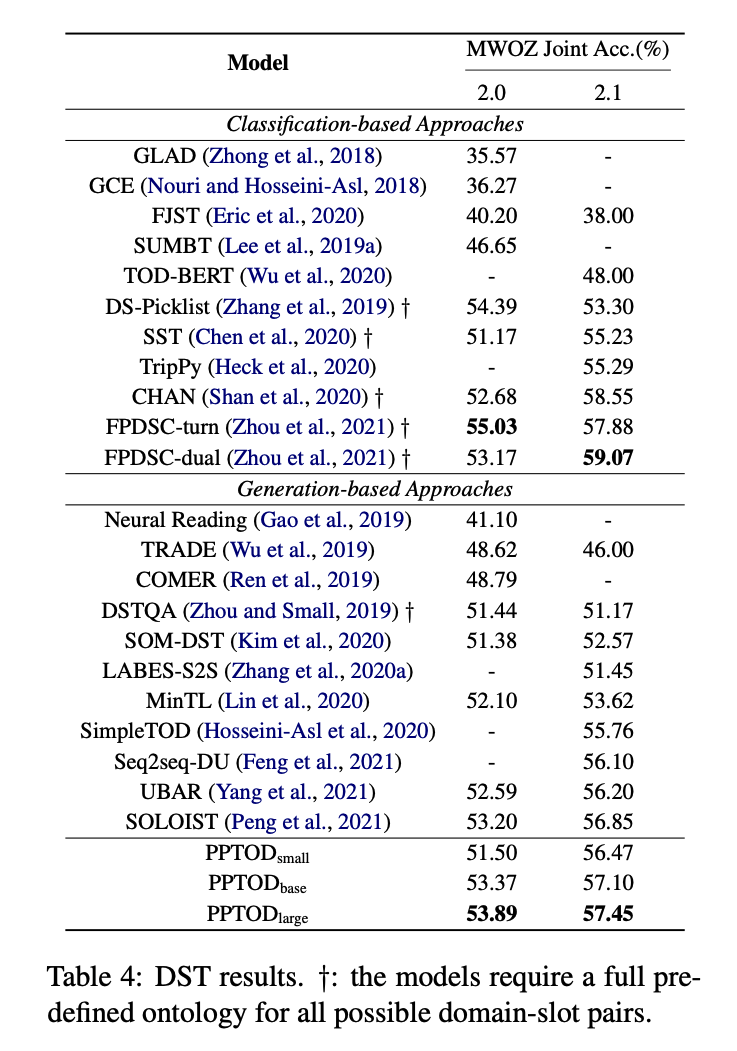
- table 4 : DST 결과
- 생성 기반 접근 방식과 달리, PPTOD large 는 두 데이터셋 모두에서 높은 정확도를 보임
- PPTOD 모델의 성능은 분류 기반 접근법의 SOTA(FPDSC) 보다는 낮다
- FPDSC 는 고정된 온톨로지에서 작동하고 사전에 정의된 slot-value pair 내에서만 예측 가능
- 즉, 확장가능성 없음(not scalable)
- 반면 PPTOD 는 학습 때 못보거나 흔하지 않은 레이블에 대해서도 출력 가능 -> 더 일반화
4.2.3 Few-Shot Evaluation
앞선 벤치마크 과제외 동일하게 DST 과제에서도 few-shot 상황에서는 어느 정도 성능을 내는지 살펴보았습니다.
- MultiWOZ 2.0 학습 데이터에서 1%, 5%, 10%, 20% 를 학습에 사용
- 3가지 생성 기반 메서드와 비교(SimpleTOD, MinTL, SOLOIST)
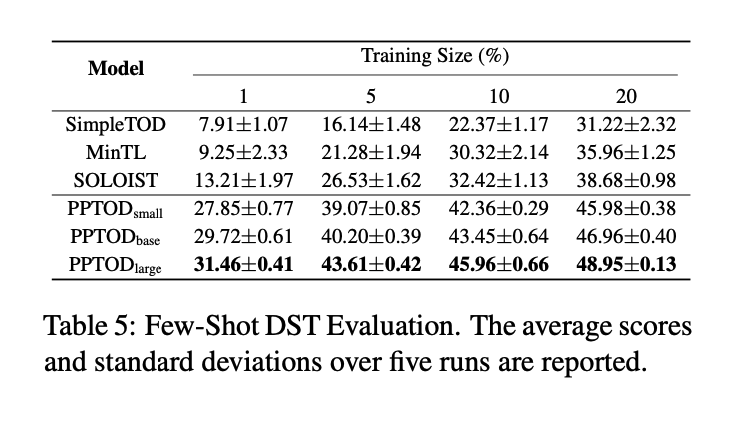
- 모든 few-shot 상황에서 PPTOD 가 다른 베이스라인보다 성능 월등함
- PPTOD 가 더 일반적이고 학습 데이터 양이 제한적인 새로운 과제에 적용하기 더 적합
4.3 Intent Classification
- PPTOD 검증 3번째 과제 - 인텐트 분류
- 인텐트 분류 : 사용자 발화에 근거하여 사용자의 의도를 분류하는 과제
- dataset : Banking77 (77 개의 인텐트 포함한 데이터셋)
- baselines : BERT-Fixed, BERT-Tuned, USE+ConveRT, USE, ConveRT, SOLOIST
- 모두 분류 기반 접근법 : 사전에 정의한 인텐트 셋에 대해서만 예측 가능
- PPTOD 는 인텐트 분류를 생성 문제로 푼다.
- 새로운 분류 과제에 적응해야 할 때, PPTOD 가 더 유연하고, 추가적인 모델 패러미터를 요구하지 않는다는 장점 있음
- 학습은 다른 학습 데이터로 5번을 돌렸고 최종 점수는 정확도를 평균낸 값임
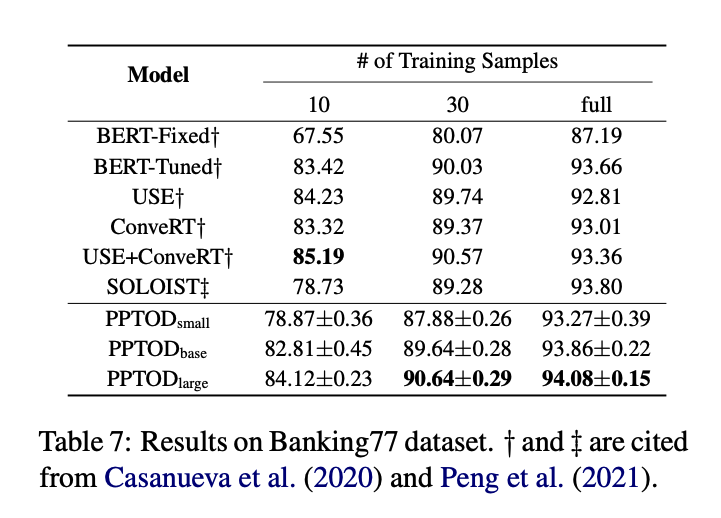
- PPTOD 는 기존 방법들과 대등한 수준
- 30%, 전체 데이터일 때는 PPTOD large 가 최고 점수
- PPTOD는 분류 문제에서 추가적인 패러미터 없이 높은 성능을 보여줌
5 Further Analysis
5.1 Plug-and-Play vs Cascaded Generation
- plug-and-play generation 방식과 Cascaded Generation 방식을 비교
- T5-small 모델 사용
- MultiWOZ 2.0 데이터셋
- 추가적으로, 모델 성능에 DB state 의 영향력을 알아보기 위해 DB state 유무에 따른 성능 비교
- DB state 를 사용할 때
- 사전 정의된 DB 에서 DB state 를 추출하기 위해 dialogue state 를 예측하고 나서 그 DB state 와 대화 맥락에 근거하여 POL 과 NLG 를 병렬적으로 진행
- DB state 를 사용하지 않을 때
- DST, POL, NLG 를 모두 병렬로 진행
- DB state 를 사용할 때
- 평가 과제: end-to-end dialogue modelling task
- 추가로 평균 inference latency(ms) 와 상대적인 속도(speedup)를 측정
- single Nvidia V100 GPU 에서 진행
- latency는 batch size 1 기준
- baselines : SOLOIST, MinTL
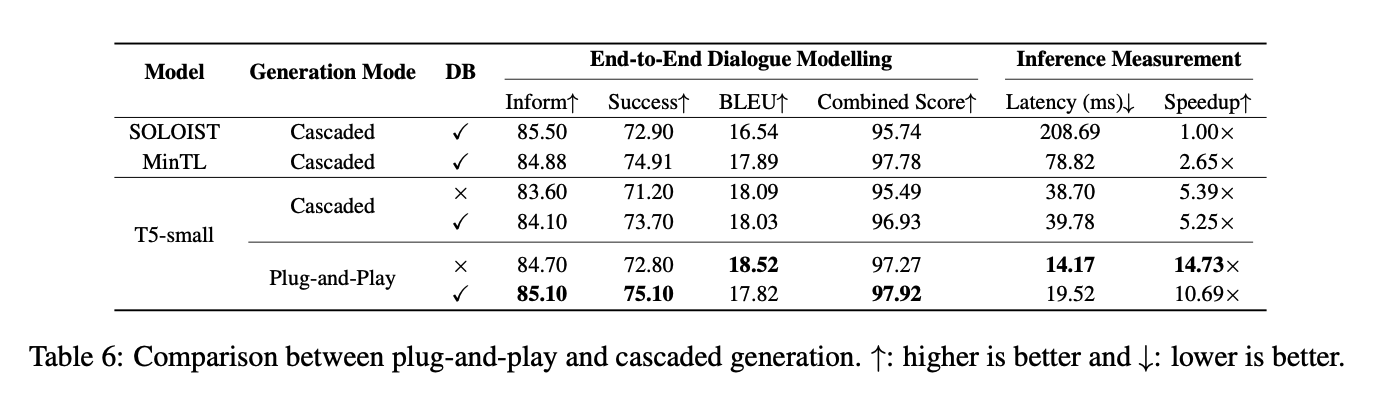
- plug-and-play model 이 cascaded model 보다 더 좋은 성능을 보임
- cascade 방식은 에러를 전파하여 축적시키기 때문
- DB state 를 사용하는 것이 두 방식 모두에서 일반적으로 모델 성능을 향상시킴
- inference latency 도 크게 줄고, 속도도 빨라졌음
5.2 Multi-Task Pre-Training Investigation
이 섹션에서는 대화 영역의 multi-task 사전학습 전략에 대해 분석해보도록 하겠습니다.
- 다른 사전학습 데이터의 중요도를 정량화하기 위해 T5-small 모델을 각 TOD 과제를 위해 레이블링된 데이터로 사전학습시킴
- 사전학습 전략 평가를 위해 2개의 데이터셋(MultiWOZ 2.0, Banking77)을 이용하여 다운스트림 과제 수행
- 다운스트림 과제 조건
- end-to-end dialogue modelling, DST
- 학습 데이터의 1%, 전체 사용 조건
- intent 분류
- 인텐트별 10개 예제, 전체
- end-to-end dialogue modelling, DST
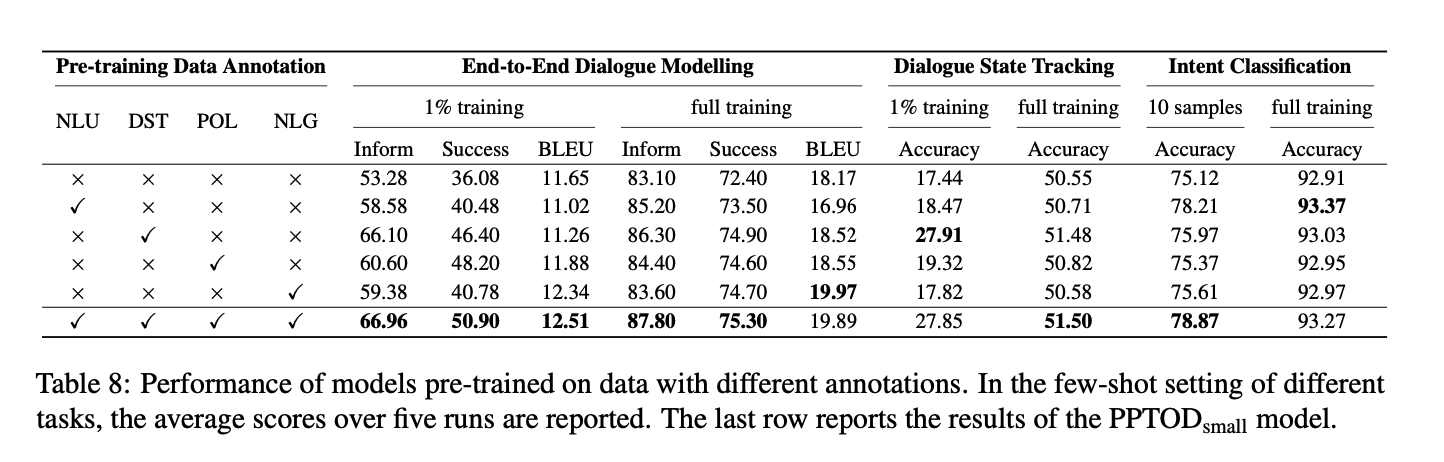
- 첫 줄의 결과는 vanilla T5-small 모델 성능
- 성능이 떨어지는 편
- 각 TOD 과제로 사전학습한 경우 그에 해당하는 다운스트림 과제의 성능을 높임
- 마지막 줄은 T5-small 모델로 모든 TOD 과제를 사전학습한 케이스인데 모든 성능이 꽤 올라간 것을 볼 수 있음
5.3 Human Evaluation
- 영어에 유창한 사람들을 대상으로 평가 진행
- MultiWOZ 2.0 데이터셋으로 수행한 결과 중 랜덤하게 50개의 대화 세션 골라서 평가 맡김
- PPTOD base vs SOLOIST
- 평가자 5명
- 리커트 척도: 0, 1, 2
- 평가 항목
- Understanding: 시스템이 사용자의 목적을 맞게 이해했는지
- Truthfulness: 시스템의 응답이 레퍼런스에 의해 사실로 지지되는지
- Coherency: 시스템 응답이 맥락에 일관성이 있는지
- Fluency: 시스템 응답이 문법적으로 맞고, 이해하기 쉬운지
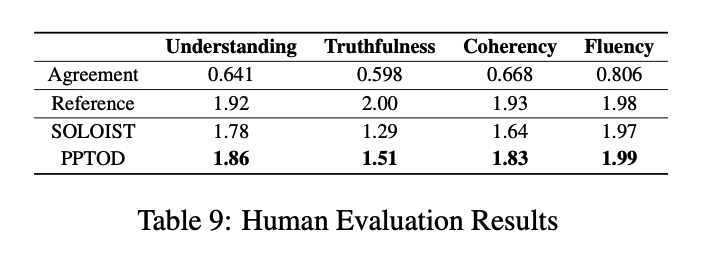
- Agreement: Fleiss’ Kappa 계수
- 범주형 데이터에 대해 여러 명의 평가자(응답자)가 있을 때
- 1에 가까우면 평가자들이 명확히 같은 의견을 내고 있다는 의미
- 0에 가까우면 평가자들의 의견이 같은 것은 우연에 가깝다는 의미
- -1에 가까우면 우연보다 강한 우연~(사실상 나오기 힘든 값)
- 일반적으로 0.75 정도만 넘으면 평가자들이 동일한 의견을 가진다고 말함. (물론 케바케)
- 범주형 데이터에 대해 여러 명의 평가자(응답자)가 있을 때
- Reference : 정답
- SOLOIST 와 비교해서 PPTOD 가 모든 메트릭에서 점수가 더 높음
- truthfulness 와 coherency 에서는 통계적으로 더 유의미하게 점수가 높음 (by Sign Test, p-value < 0.05)
- Fluency 영역에서 두 개의 시스템은 reference 와 대등한 수준
6 Conclusion
- plug-and-play 방식의 TOD 아키텍쳐인 PPTOD 제안
- 새로운 multi-task 사전학습 전략 제안
- 3개의 TOD 벤치마크 과제 X 데이터가 적고 많음 상황 모두 X 자동,인간 평가 모두에서 현재 SOTA 를 넘었다.
소견
PPTOD 를 사용하면 데이터 활용에 큰 이점이 있다고 생각합니다.
- 각 TOD의 다운스트림 과제만을 위한 데이터를 사용해도 되면 레이블링 작업에 들어가는 수고가 줄어들 것입니다. 하나의 시스템에서 사용하기 위해서는 특정 데이터가 모든 과제를 위한 속성(intent, entity 등)들을 갖추고 있어야 하는게 이전 방법들인데 이 경우 복잡하여 레이블 작업에 많은 수고가 생깁니다.
- 새로 개발하려는 서비스를 위한 데이터는 적을 수 있지만 학계와 정부가 내놓은 데이터는 꽤 있습니다. 사전학습에서 공개된 데이터를 사용하고 새로운 서비스를 위한 데이터는 적게 유지할 수 있다는 점에서 이점이 있습니다.
PPTOD의 사전학습 및 파인튜닝은 TAPT 와 PET 의 결합이 아닌가 싶습니다.
PPTOD 논문에서 말하는 사전학습은 엄밀히 말하면 2번째 사전학습입니다. 실제 다운스트림 과제 전에 한 학습은 모두 사전학습이라고 볼 수 있으니까요. T5 최초 사전학습한 것이 첫 번째 사전학습이고 task에 맞는 데이터를 학습한 것이 두 번째 사전학습입니다. Task-Adaptive Pre-Training(TAPT) 는 task에 맞는 비교적 적은 데이터만으로 추가 학습을 하여 성능을 올릴 수 있습니다.
추가로 두 번째 사전학습과 다운스트림 과제의 형태를 동일하게 맞춰서 더한 이득을 봤다고 생각합니다. 생성 문제 스타일로 모든 입출력을 통일하니 모델 성능이 올라간 것입니다. 이런 아이디어는 Pattern-Exploiting Training(PET) 식이라고 봅니다. 이 논문에서는 BERT가 사전학습에서 masking 하는 것이 결국 빈칸 채우기이기 때문에 다운스트림 과제에서도 빈칸채우기로 정답을 예측하도록 하여 성능을 높였습니다.
병렬 처리를 통한 에러 전파 방지와 시스템 반응 속도 개선이 또 다른 주요한 PPTOD의 매력입니다.
DB에서 DB state를 결합시킬 수 있도록 한 것도 기존 데이터베이스를 활용할 수 있는 길을 열어줬다는 점에서 의미가 있습니다. 이렇게 보면 검색을 데이터베이스 뿐만 아니라 웹 검색을 통해서도 가능하지 않을까 생각이 드네요.
References