
- 교재 : Deep Reinforcement Learning Hands-On 2/E
- github : https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Second-Edition
Intro
이번 챕터에서는 다음과 같은 내용을 다룰 예정입니다.
- PyTorch 라이브러리 세부사항 및 구현 세부 정보
- 실시간 학습 모니터링 툴
- DL 문제를 단순화하기 위한 목적으로 PyTorch 상의 고차원 라이브러리들
Tensors
tensor는 모든 딥러닝 toolkit에서 기본적인 빌딩 블럭입니다. 텐서의 근본적인 개념은 다차원 배열이라는 것입니다.
딥러닝에서 사용하는 텐서에 대해 주의해야 할 점은 딥러닝의 텐서가 수학에서 텐서 미적분(tensor calculus), 텐서 대수(tensor algebra)와 부분적으로만 관련 있다는 것입니다. 즉, 완전히 같은 텐서가 아닙니다. DL에서 텐서는 임의의 다차원 배열이지만 수학에서 텐서는 벡터 공간 사이의 매핑으로, 경우에 따라서 다차원 배열이 될 수도 있지만 그 뒤에 더 많은 의미를 가지고 있습니다.
The creation of tensors
pytorch는 8개의 텐서 데이터 타입을 가지고 있습니다.
- 3개의 float type
- 16-bit
- 32-bit (torch.FloatTensor)
- 64-bit
- 5개의 integer type
- 8-bit signed
- 8-bit unsigned (torch.ByteTensor)
- 16-bit
- 32-bit
- 64-bit (torch.LongTensor)
위에 이름 달아둔 저 3개를 주로 많이 사용합니다.
파이토치에서 텐서를 생성하는 방법은 3가지가 있습니다.
- 해당 데이터 타입의 contructor를 호출
- numpy array나 python list를 tensor로 변환
- 특정 데이터로 텐서 만들기
- ex)torch.zeros()
위 방법 순서대로 생성해보겠습니다.
import torch
import numpy as np
a = torch.FloatTensor(3, 2)
b = torch.FloatTensor([[1,2,3], [3,2,1]])
c = torch.zeros((3,2))
numpy array를 활용할 때 유의할 점이 있습니다. numpy.zeros() 로 만든 배열을 tensor로 만들 경우에 numpy array는 디폴트로 64-bit float으로 만들어집니다. 이 배열을 입력으로 받은 텐서도 DoubleTensor(64-bit float) type으로 만들어지게 되고요. 근데, DL에서 보통 이 정도로 정밀할 필요없고 또 메모리가 부족하거나 성능 오버헤드가 일어날 수 있습니다. 일반적으로는 32-bit float이나 심지어 16-bit float으로 해도 충분합니다. 그래서 이 경우에 다음과 같이 데이터 타입을 어느 한 쪽에서라도 특정해주는 것이 좋습니다.
>>> n = np.zeros(shape=(3, 2), dtype=np.float32)
>>> torch.tensor(n)
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
>>> n = np.zeros(shape=(3,2))
>>> torch.tensor(n, dtype=torch.float32)
tensor([[ 0., 0.],
[ 0., 0.],
[ 0., 0.]])
Scalar tensors
PyTorch 0.4.0 이후로 0차원 텐서, 즉 scalar tensor 값도 지원합니다. 1차원 벡터의 연산 결과일 수도 있고 바로 생성한 결과일 수도 있습니다. item()이라는 메서드로 python value에 접근도 할 수 있습니다.
>>> a = torch.tensor([1,2,3])
>>> a
tensor([ 1, 2, 3])
>>> s = a.sum()
>>> s
tensor(6)
>>> s.item()
6
>>> torch.tensor(1)
tensor(1)
Tensor operations
텐서로 할 수 있는 operation은 엄청 많습니다. PyTorch 공식 문서 에서 확인할 수 있습니다. 대부분의 연산 메서드는 numpy 연산에 대응하고 있습니다.
tensor operation에는 두가지 타입이 있습니다.
- inplace operation
- 이름에 _(underscore) 가 있음
- tensor의 content를 가지고 작업 수행
- object 그 자체가 반환됨.
- 성능과 메모리 측면에서 보통 더 효과적
- ex) tensor.abs_()
- functional operation
- 원래 tensor를 건드리지 않고 카피 떠서 작업 수행
- ex) abs(tensor)
GPU tensors
PyTorch는 GPU와 CPU 모두에서 지원합니다. 모든 연산은 두 개의 버전을 가지고 있고 이는 자동으로 선택됩니다.
차이점은 GPU tensor는 torch 대신에 torch.cuda 패키지에 있다는 점입니다.
예를 들어, FloatTensor
- CPU : torch.FloatTensor
- GPU : torch.cuda.FloatTensor
CPU에서 GPU로 변환시킬 때는 to(device) 를 사용하면 됩니다. 이는 텐서 자체를 바꾸는 것이 아니고 카피 떠서 특정 디바이스에 올라간 텐서를 만드는 것입니다. device에 “cpu”라고 하면 CPU memory에 올라가고 “cuda”라고 하면 GPU에 올라갑니다. 특정 GPU 번호에 할당할 때는 “cuda:번호”로 지정합니다.
>>> a = torch.FloatTensor([2,3])
>>> a
tensor([ 2., 3.])
>>> ca = a.to('cuda')
>>> ca
tensor([ 2.,3.], device='cuda:0')
>>> ca.device
device(type='cuda', index=0)
Gradients
gradients의 자동계산은 Caffe toolkit에서 처음 구현되었고 DL 라이브러리에서 표준으로 정착되었습니다.
최근 라이브러리들에서는 input에서 output까지 레이어의 순서만 잘 정의하면 모든 gradient 계산, 역전파가 정확하게 계산될 것입니다.
gradient 계산에는 두 가지 접근법이 있습니다.
- Static graph : 사전에 계산법을 정의해야 하며 나중에는 변경할 수 없음.
- Dynamic graph :
- 실행되기 전까지 미리 그래프를 정의할 필요가 없다. 실제 데이터의 데이터 변환에 사용할 작업만 실행하면 된다.
- 이 기간에 라이브러리는 수행된 연산의 순서를 기록하고, 그래디언트 계산을 요청하면 연산 기록을 제거하여 네트워크 패러미터의 그래디언트를 누적시킨다.
- 이 방법은 notebook gradients라고도 불리며 PyTorch, Chainer 등에서 구현되어 있다.
Tensors and gradients
pytorch tensor는 gradient 계산 기능을 내장하고 있습니다. gradient와 관련한 tensor의 속성은 다음과 같습니다.
- grad : 계산된 그래디언트 값을 포함하여 동일한 모양의 텐서를 유지시키는 속성
- is_leaf : 해당 텐서가 유저에 의해 만들어졌으면 True, 아니면 False
- requires_grad : 텐서의 그래디언트를 계산하길 원하면 True, 아니면 False. 이 속성은 리프 텐서부터 상속받을 수 있다.
>>> v1 = torch.tensor([1.0, 1.0], requires_grad=True)
>>> v2 = torch.tensor([2.0, 2.0])
>>> v_sum = v1 + v2
>>> v_res = (v_sum*2).sum()
>>> v_res
tensor(12., grad_fn=<SumBackward0>)
>>> v1.is_leaf, v2.is_leaf
(True, True)
>>> v_sum.is_leaf, v_res.is_leaf
(False, False)
>>> v1.requires_grad
True
>>> v2.requires_grad
False
>>> v_sum.requires_grad
True
>>> v_res.requires_grad
True
>>> v_res.backward()
>>> v1.grad
tensor([ 2., 2.])
>>> v2.grad
v2는 requires_grad=True를 주지 않았기 때문에 grad 계산이 되지 않습니다.
위와 같은 그래디언트 계산 능력으로 neuralnet optimizer를 만들 수 있습니다. 댜음 세션에서는 뉴럴넷 빌딩 블럭, 인기 있는 최적화 알고리즘, loss function을 간편하게 사용할 수 있는 함수들을 다룰 예정이지만 그것들이 아니더라도 torch tensor를 이용해서 자기 입맛에 맞게 바꿀 수 있습니다. 이 점이 pytorch가 DL 연구자들에게 인기 있는 이유 중 하나 입니다.
NN building blocks
torch.nn package는 기본적인 기능 블럭들과 함께 사전 정의한 클래스들을 제공합니다. 모두 실제 상황을 고려하여 설계되었습니다. 예를들어, minibatch를 지원하고 기본값이 정상이며 가중치가 적절히 초기화되어 있습니다. 모든 모듈들은 callable하게 만들었습니다. 모든 클래스의 인스턴스는 인자가 적용되면 함수 역할을 할 수 있다는 의미입니다. 아래 예시에서 nn.Linear는 인스턴스 생성 후에는 함수로 역할을 수행합니다.
>>> import torch.nn as nn
>>> l = nn.Linear(2, 5)
>>> v = torch.FloatTensor([1, 2])
>>> l(v)
tensor([ 1.0532, 0.6573, -0.3134, 1.1104, -0.4065], grad_
fn=<AddBackward0>)
torch.nn의 모든 클래스는 nn.Module 클래스를 상속하는데 이 nn.Module 클래스의 유용한 메서드를 살펴봅시다.
- parameters(): 그래디언트 계산에 필요한 모든 변수들의 iterator를 반환 (즉, module weigts)
- zero_grad(): 모든 패러미터의 그래디언트를 0으로 초기화
- to(device): 모든 모듈 패러미터를 주어진 디바이스로 옮김.
- state_dict(): 모든 모듈 패러미터를 딕셔너리 형태로 반환하고 이는 model serialization에 유용함.
- load_state_dict(): state dictionary를 지닌 모듈을 초기화.
모든 클래스 목록은 다음 공식 문서에서 찾아볼 수 있습니다.
Sequential
Sequential은 파이프라인 구조로 레이어를 쌓을 때 쓸 수 있는 아주 유용한 클래스입니다. 다음처럼 사용할 수 있습니다.
>>> s = nn.Sequential(
... nn.Linear(2, 5),
... nn.ReLU(),
... nn.Linear(5, 20),
... nn.ReLU(),
... nn.Linear(20, 10),
... nn.Dropout(p=0.3),
... nn.Softmax(dim=1))
>>> s
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): ReLU()
(2): Linear(in_features=5, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=10, bias=True)
(5): Dropout(p=0.3)
(6): Softmax()
)
>>> s(torch.FloatTensor([[1,2]]))
tensor([[0.1115, 0.0702, 0.1115, 0.0870, 0.1115, 0.1115, 0.0908,
0.0974, 0.0974, 0.1115]], grad_fn=<SoftmaxBackward>)
Custom layers
앞서 간단히 nn.Module 클래스를 사용해서 NN building block를 만들어보았습니다. 이번 섹션에서는 nn.Module의 subclass들을 이용해서 custom layer를 만들 것입니다. 이는 여러 개를 쌓을 수도 있고 나중에 재사용도 가능합니다.
nn.Module은 꽤 풍부한 기능들을 자식 클래스에 제공합니다.
- 현재 모듈이 포함하고 있는 하부 모듈들을 모두 추적해준다.
- 등록된 하부 모듈들의 모든 패러미터를을 처리하는 함수를 제공한다. 모듈의 패러미터들의 리스트를 parameters() method로 얻을 수 있고 gradients를 0으로 초기화할 수 있고(zero_grads() method), 모듈을 serialize, deserialize할 수도 있다.(state_dict(), load_state_dict())
- 데이터에 대한 Module application의 관습을 만들었다. 모든 모듈은 forward() method를 overriding함으로써 forward() 메서드 안에서 data transformation을 수행할 필요가 있다.
이 기능들은 하위 모델들을 통일된 방식으로 상위 모델에 중첩시킬 수 있으며, 이는 복잡성을 처리할 때 매우 유용합니다. 한 겹의 선형 레이어가 될 수도 있고 1001 층의 ResNet이 될 수도 있지만 둘 다 동일한 방식으로 컨트롤할 수 있다는 이야기입니다.
그래서 custom module을 만들기 위해서는 보통 두 가지를 하면 됩니다. submodule들을 등록하고 forward() method를 구현하는 것입니다.
이전 챕터에서 사용했던 Sequential 예제를 통해 커스텀 모듈을 만들어보겠습니다. (Chapter03/01_modules.py)
class OurModule(nn.Module):
def __init__(self, num_inputs, num_classes, dropout_prob=0.3):
super(OurModule, self).__init__()
self.pipe = nn.Sequential(
nn.Linear(num_inputs, 5),
nn.ReLU(),
nn.Linear(5, 20),
nn.ReLU(),
nn.Linear(20, num_classes),
nn.Dropout(p=dropout_prob),
nn.Softmax(dim=1)
class 형태의 모델은 항상 nn.Module을 상속 받아야 하며, super(모델명, self).init() 을 통해 nn.Module.init() 을 실행시킵니다. 생성자에서 self.pipe라는 하위 모듈을 만들어놓으면 다음과 같이 재사용할 수 있습니다.
def forward(self, x):
return self.pipe(x)
forward() 는 모델이 학습 데이터를 입력받아서 forward propagation을 진행시키는 함수이고, 반드시 forward 라는 이름의 함수여야 합니다. 모듈들은 callable하기 때문에 사용자들도 forward()를 직접 호출하는 방식을 사용하지 않습니다. 이는 nn.Module 이 call() method를 override해서 인스턴스가 callable 하도록 했기 때문입니다.
아래 예제는 위에서 작성한 custom module을 사용해본 것입니다.
if __name__ == "__main__":
net = OurModule(num_inputs=2, num_classes=3)
v = torch.FloatTensor([[2, 3]])
out = net(v)
print(net)
print(out)
제 노트북에서 실행한 결과입니다.
OurModule(
(pipe): Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): ReLU()
(2): Linear(in_features=5, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=3, bias=True)
(5): Dropout(p=0.3, inplace=False)
(6): Softmax(dim=1)
)
)
tensor([[0.4031, 0.4031, 0.1937]], grad_fn=<SoftmaxBackward>)
그 다음은 loss function과 optimizer에 대해 알아보겠습니다.
The final glue - loss functions and optimizers
Loss Function
손실 함수(loss function) 혹은 비용 함수(cost function)이라고 불리는 것은 모델이 예측한 값과 실제 값이 얼마나 유사한지 판단하는 기준을 정해주는 역할을 합니다. 예측값과 실제값 간 차이를 loss라고 하며, 이 loss를 줄이는 방향으로 학습이 진행됩니다.
통계학적 모델은 일반적으로 회귀와 분류로 나뉘는데 손실 함수도 그에 따라 두 가지 종류로 나뉩니다. 회귀에 쓰이는 대표적 손실 함수는 MAE, MSE, RMSE가 있으며, 분류에 쓰이는 손실함수는 Binary cross-entropy, Categorical cross-entropy 등이 있습니다.
손실 함수도 nn.Module의 하위모듈로 구현되어 있으며 자주 사용되는 것은 다음과 같습니다.
- nn.MSELoss : MSE(Mean Squared Error) 손실 함수
- nn.BCELoss & nn.BCEWithLogits : Binary cross-entropy loss.
- nn.BCELoss : 보통 sigmoid layer의 결과로 하나의 확률 값을 반환한다.
- nn.BCEWithLogits : BCELoss 앞에 sigmoid layer를 더한 레이어로 sigmoid를 사용한다면 sigmoid와 BCELoss를 둘 다 사용하는 것보다는 한 번에 쓰는 것이 더 안정적이다.
- nn.CrossEntropyLoss & nn.NLLLoss : multi classification problem에서 사용됨.
- nn.LogSoftmax : 신경망 말단의 결과 값들을 확률 개념으로 해석하기 위한 softmax의 결과에 log 값을 취한 연산
- nn.NLLLoss : nn.LogSoftmax의 log 결과값에 대한 교차 엔트로피 손실 연산
- nn.CrossEntropyLoss : nn.LogSoftmax와 nn.NLLLoss의 연산의 조합으로, 수식이 간소화되어 역전파가 더 안정적으로 이루어지므로 실제 사용에 권장된다.
Optimizer
기본 optimizer의 책임은 모델 패러미터의 그래디언트를 받아서 loss value가 작아지도록 패러미터를 변화시키는 것입니다. PyTorch에서는 torch.optim 패키지에서 여러 유명한 optimizer를 통일된 interface로 제공합니다. 다음이 가장 넓게 쓰이는 optimizer입니다.
- SGD : torch에서 제공하는 SGD는 momentum 옵션이 가능한 SGD.
- Adagrad : 학습률이 너무 작으면 학습 시간이 너무 길고, 학습률이 너무 크면 발산해서 학습이 제대로 이루어지지 않는데 이 문제를 Adagrad는 학습률 감소(learning rate decay)로 해결한다. AdaGrad 가 간단한 convex function 에선 잘 동작하지만, 복잡한 다차원 곡면 함수를 (상대적으로) 잘 탐색하도록 설계되지 않기도 했고. 기울기의 단순한 누적만으로는 충분하지 않다.
- RMSprop : 기울기를 단순 누적하지 않고 지수 가중 이동 평균(Exponentially weighted moving average)를 사용하여 최신 기울기들이 더 크게 반영되도록 하였다.
- Adam : Adagrad와 RMSprop의 조합으로 가장 성공적이고 유명하다. 주요 장점은 step size가 gradient의 rescaling에 영향을 받지 않는다는 점이다. gradient가 커져도 step size는 제한이 있어서 어떠한 objective function을 사용한다 하더라도 안정적으로 최적화를 위한 하강이 가능하다.
다음은 학습 루프의 일반적인 청사진입니다.
for batch_x, batch_y in iterate_batches(data, batch_size=32): #1
batch_x_t = torch.tensor(batch_x) #2
batch_y_t = torch.tensor(batch_y) #3
out_t = net(batch_x_t) #4
loss_t = loss_function(out_t, batch_y_t). #5
loss_t.backward() #6
optimizer.step() #7
optimizer.zero_grad() #8
- #1
- 보통 학습 시에 데이터는 반복 과정을 거칩니다. (학습 전체 예제를 모두 돌리는 것을 epoch 이라고 부릅니다.) 데이터는 CPU 혹은 GPU 메모리에 한 번에 들어가기 큰 경우가 많아서 이를 동일한 크기의 배치로 자릅니다.
- #2, #3
- 모든 배치는 데이터 샘플과 레이블, 그리고 이 두개의 텐서를 가지고 있습니다.
- #4
- 데이터 샘플을 위에서 만든 네트워크에 입력으로 주고 출력값을 out_t에 할당합니다.
- #5
- 출력값과 레이블을 손실 함수에 입력으로 주고 손실값을 할당 받습니다. 손실값은 타겟 레이블과 비교하여 네트워크 결과의 “안좋음”을 보여줍니다. 네트워크와 네트워크 가중치의 입력이 모두 텐서이기 때문에 네트워크의 transformation은 중간 텐서 인스턴스를 사용하는 작업의 그래프에 지나지 않습니다.
- #6
- 이 계산 그래프의 모든 텐서는 상위 텐서를 기억하므로 전체 네트워크의 그래디언트를 계산하기 위해 손실 함수의 결과에서 backward() method를 호출하기만 하면 됩니다. require_grad=True 가 되어 있는 모든 leaf tensor에 대해서 역전파 계산이 이루어질 것입니다.
- #7
- 역전파 후에 그래디언트 값들을 축적하고 optimizer가 그래디언트 값을 기반으로 작업을 수행합니다. 이 작업은 step() 하나로 됩니다.
- #8
- 그래디언트를 0으로 만듭니다. training loop의 처음에 하는 경우도 있습니다.
이 구성은 최적화를 수행하는 데 매우 유연한 방법이며 정교한 연구에서도 적용될 수 있습니다. 예를 들어, Generative Adversarial Network(GAN) 학습에서는 2개의 optimizer를 쓸 수도 있습니다.
이로써 기본적인 PyTorch 기능에 대해 알아보았고, 텐서보드를 통해 학습 프로세스를 모니터링하는 법을 배우고 나서 중간 사이즈의 예제를 보겠습니다.
Monitoring with TensorBoard
뉴럴넷을 설계하고 그 결과를 얻는 데 있어서 여러 어려움이 있는데 학습 과정을 관찰할 수 있는 것은 큰 장점을 지닙니다. 보통 다음 값들이 관찰 대상입니다.
- 손실값
- 학습, 테스트 데이터 검증 결과
- 그래디언트와 가중치에 대한 통계치
- 네트워크에 의해 만들어진 값들 : 예를 들어, 분류 문제의 경우 예측 클래스 확률의 엔트로피를 측정하기를 원할 것이고, 회귀 문제의 경우 예측값을 원할 것이다.
- 학습율과 다른 hyperparameters : 만약 시간에 따라 변한다면 보여주는 것이 좋다.
이외에도 학습 속도 등을 관찰 대상으로 지정할 수 있습니다.
TensorBoard 101
이 책에서는 모니터링 툴로 TensorBoard를 사용할 것입니다. 텐서보드는 학습 과정에서 뉴럴넷 특징들을 관찰하고 분석할 수 있는 툴입니다. 텐서보드는 강력하고 제너럴한 솔루션이면서 외양도 꽤 이쁩니다.
텐서보드는 로컬에서 띄울 수 있는 python web service입니다. 클라우드에 올려놓고 어디서든 볼 수도 있습니다. 원래는 Tensorflow의 일부로 deploy되었지만 최근에는 별개의 프로젝트로 옮겨졌고 tensorflow와 별개로 사용할 수 있습니다. 다만 여전히 TensorBoard는 tensorflow 데이터포맷을 사용하기 때문에 Tensorflow와 TensorBoard 둘 다 설치해야 합니다.
몇몇 써드파티 오픈소스에서 텐서보드를 이용해서 더 편리하고 고급진 인터페이스를 제공하고 있고 그 중 하나가 tensorboardX입니다. 이 책에서는 이를 다룰 예정입니다.
- 참고사항
- PyTorch 1.1부터 TensorBoard format을 실험적으로 지원하고 있어서 tensorboardX를 설치할 필요가 없지만 뒤에 나올 PyTorch Ignite가 tensorboardX에 의존성이 있어서 계속 쓸 예정입니다.
Plotting stuff
간단한 예제(뉴럴넷 아님)를 통해 tensorboardX에 대해 알아보겠습니다. 다음 예제는 Chapter03/02_tensorboard.py 에 있는 내용입니다.
import math
from tensorboardX import SummaryWriter
if __name__ == "__main__":
writer = SummaryWriter()
funcs = {"sin": math.sin, "cos": math.cos, "tan": math.tan}
먼저 필요한 패키지를 임포트하고 writer를 생성하고 시각화할 예정인 함수들을 정의합니다. SummaryWriter는 기본적으로 runs 디렉토리를 생성하고 여기에 내용을 저장합니다. runs 디렉토리 밑에 오늘 날짜, 시간, hostname을 포함한 디렉토리를 기준으로 로그가 작성됩니다. 동일한 디렉토리에 계속 저장하고 싶으면 log_dir argument를 사용하면 됩니다.
for angle in range(-360, 360):
angle_rad = angle * math.pi / 180
for name, fun in funcs.items():
val = fun(angle_rad)
writer.add_scalar(name, val, angle)
writer.close()
이 예제는 -360도에서 360도까지 각도를 변해가면서 라디안으로 바꾸고 사전에 정의한 함수들에 입력하여 결과값을 얻고 add_scalar 함수로 값을 저장하고 있습니다. writer는 주기적으로 flush(기본은 매 2분마다)하기 때문에 오래 걸리는 최적화 과정도 그 값들을 볼 수 있습니다.
저 예제를 실행하고 나면 runs/date_time_hostname 해당하는 디렉토리 밑에 이벤트 파일이 생깁니다. 그러면 다음과 같이 명령어를 작성합니다.
.../Chapter03$ tensorboard --logdir runs
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.4.0 at http://localhost:6006/ (Press CTRL+C to quit)
그러면 “http://localhost:6006” 이 주소 가면 로그를 볼 수 있습니다.
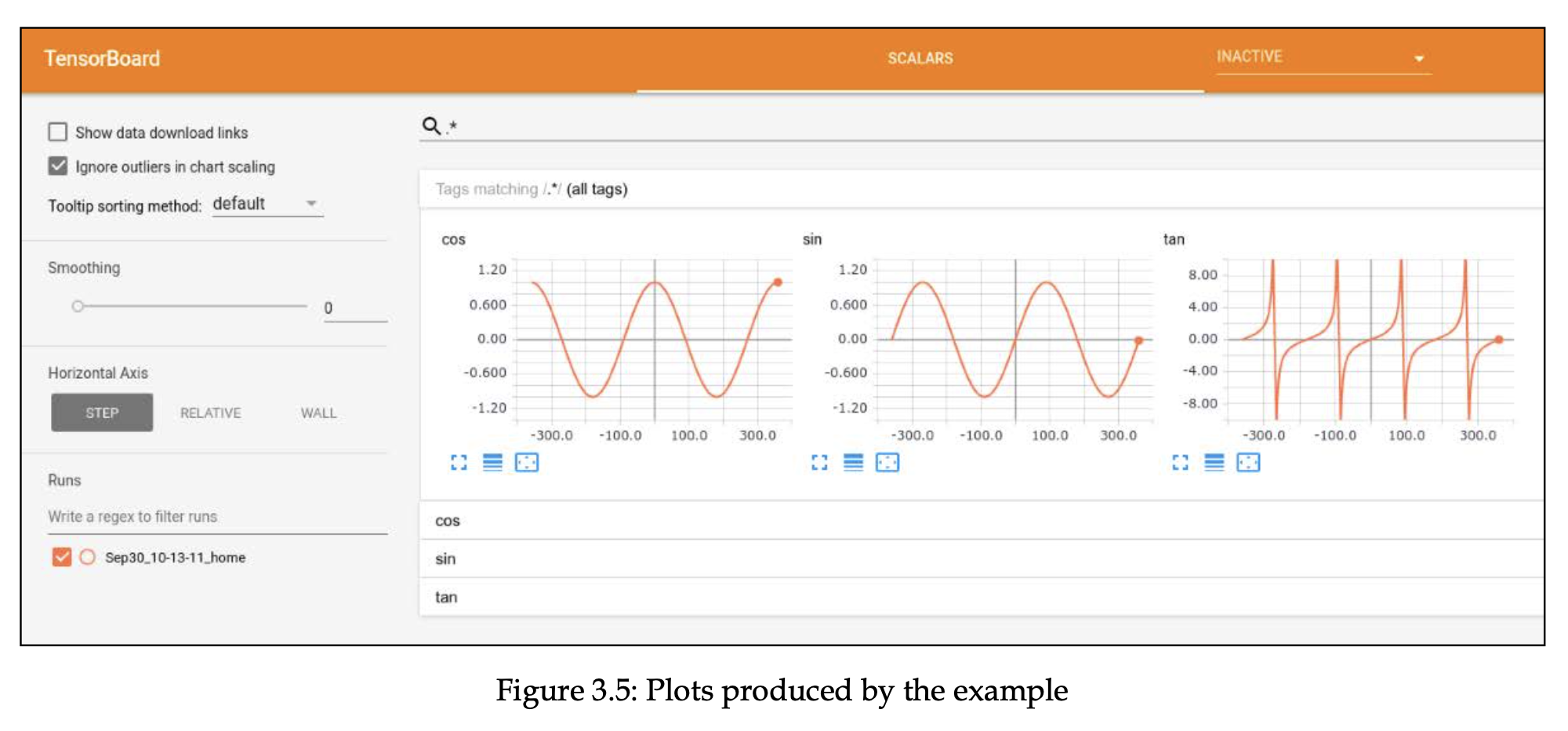
- 그래프에 마우스를 올리면 그 지점에서의 값을 볼 수 있습니다.
- 로그가 여러 개가 쌓였을 경우에는 runs 아래에 여러 디렉토리가 생겼을텐데 그러면 각 디렉토리별로 내용을 볼 수 있고 비교도 가능합니다.
- 스칼라 값 뿐만 아니라 이미지, 오디오, 텍스트 데이터, 임베딩도 분석 가능하고, 심지어 네트워크 구조도 보여줄 수 있습니다.
이제 모니터링 툴까지 준비했으니 토치를 이용한 실제 뉴랄넷 최적화 문제를 통해 이번 챕터에서 배운 내용들을 실습해보도록 하겠습니다.
Example - GAN on Atari images
실습 예제는 아타리 게임에서의 GAN입니다.
- 가장 간단한 GAN 구조 사용
- 두 개의 경쟁적인 관계를 가진 네트워크를 가지고 있음
- cheater( == the generator) : 가짜 데이터를 만들어냄
- detective( == the discriminator) : 생성된 데이터(가짜)를 탐지해내고자 함.
- 두 개의 경쟁적인 관계를 가진 네트워크를 가지고 있음
- GAN의 실용적인 측면보다는 복잡한 모델을 PyTorch를 통해 얼마나 깔끔하고 짧게 코딩할 수 있는지 보여주고자 함.
- Chapter03/03_atari_gan.py
IMAGE_SIZE = 64
class InputWrapper(gym.ObservationWrapper):
"""
Preprocessing of input numpy array:
1. resize image into predefined size
2. move color channel axis to a first place
"""
def __init__(self, *args):
super(InputWrapper, self).__init__(*args)
assert isinstance(self.observation_space, gym.spaces.Box)
old_space = self.observation_space
self.observation_space = gym.spaces.Box(
self.observation(old_space.low),
self.observation(old_space.high),
dtype=np.float32)
def observation(self, observation):
# resize image
new_obs = cv2.resize(
observation, (IMAGE_SIZE, IMAGE_SIZE))
# transform (210, 160, 3) -> (3, 210, 160)
new_obs = np.moveaxis(new_obs, 2, 0)
return new_obs.astype(np.float32)
이 Wrapper 클래스는 다음과 같은 작업을 합니다.
- 210 X 160 크기의 입력 이미지를 64 x 64 사이즈로 변환한다.
- 색깔을 첫번째 축에서 마지막 축으로 변경한다.
- pytorch가 (채널, 높이, 너비) 순으로 받기 때문
- 이미지를 bytes에서 float 타입으로 변환
이제 두개의 nn.Module class(Discriminator와 Generator)를 작성하면 됩니다. 이 두 개의 네트워크는 경쟁 관계이면서 형태를 보면 데칼코마니 같이 유사합니다.
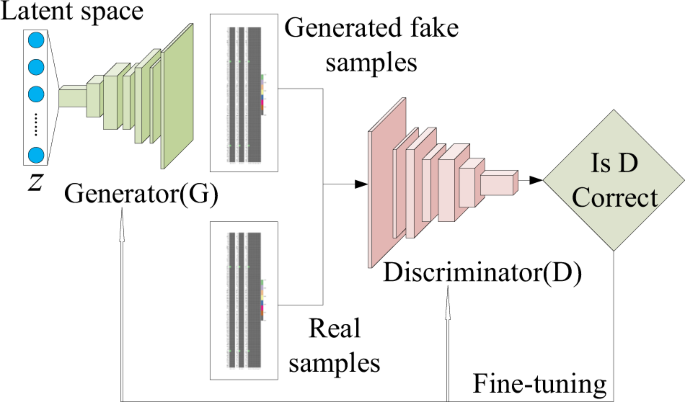
여기서 GAN 자체가 초점이 아니라 GAN에 대한 자세한 설명은 생략하겠습니다.

입력값으로 랜덤 에이전트에서 동시에 플레이하는 여러 개의 아타리 게임의 스크린샷을 이용할 것이고 그림 3.6은 입력 데이터가 어떻게 생겼는지 보여줍니다. 이 예제는 다음 함수에 의해 생성됩니다.
def iterate_batches(envs, batch_size=BATCH_SIZE):
batch = [e.reset() for e in envs]
env_gen = iter(lambda: random.choice(envs), None)
while True:
e = next(env_gen)
obs, reward, is_done, _ = e.step(e.action_space.sample())
if np.mean(obs) > 0.01:
batch.append(obs)
if len(batch) == batch_size:
# Normalising input between -1 to 1
batch_np = np.array(batch, dtype=np.float32) * 2.0 / 255.0 - 1.0
yield torch.tensor(batch_np)
batch.clear()
if is_done:
e.reset()
- 이 함수를 통해 제공된 배열에서 환경을 무한히 샘플링하고 임의의 action을 하게 하며 배치 리스트에 관찰값들을 저장합니다.
- 배치가 필요한 크기가 되면, 이미지를 정규화하고 텐서로 변환하여 generator로부터 이미지를 생성시킵니다.
이제 main function을 봐보면, 먼저 CUDA 설정과 환경을 준비합니다.
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--cuda", default=False, action='store_true',
help="Enable cuda computation")
args = parser.parse_args()
device = torch.device("cuda" if args.cuda else "cpu")
envs = [
InputWrapper(gym.make(name))
for name in ('Breakout-v0', 'AirRaid-v0', 'Pong-v0')
]
input_shape = envs[0].observation_space.shape
–cuda argument로 GPU 사용하도록 설정할 수 있고, 3개의 아타리 게임을 환경 리스트로 만들었습니다. 이 환경들이 iterate_batches function을 거치면 학습 데이터가 만들어 집니다.
net_discr = Discriminator(input_shape=input_shape).to(device)
net_gener = Generator(output_shape=input_shape).to(device)
objective = nn.BCELoss() # Binary Cross Entropy Loss
gen_optimizer = optim.Adam(
params=net_gener.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
dis_optimizer = optim.Adam(
params=net_discr.parameters(), lr=LEARNING_RATE,
betas=(0.5, 0.999))
writer = SummaryWriter()
이 코드에서는 summary writer, 두 개의 네트워크, 손실 함수, 두 개의 optimizer를 만들었습니다.
gen_losses = []
dis_losses = []
iter_no = 0
true_labels_v = torch.ones(BATCH_SIZE, device=device)
fake_labels_v = torch.zeros(BATCH_SIZE, device=device)
두 네트워크의 손실값들을 저장할 리스트, counter, 진짜, 가짜 레이블의 변수를 만들었습니다.
for batch_v in iterate_batches(envs):
# fake samples, input is 4D: batch, filters, x, y
gen_input_v = torch.FloatTensor(
BATCH_SIZE, LATENT_VECTOR_SIZE, 1, 1)
gen_input_v.normal_(0, 1)
gen_input_v = gen_input_v.to(device)
batch_v = batch_v.to(device)
gen_output_v = net_gener(gen_input_v)
학습 루트 처음에는 랜덤 벡터를 생성하고 이를 generator network에 입력으로 넘깁니다.
# train discriminator
dis_optimizer.zero_grad()
dis_output_true_v = net_discr(batch_v)
dis_output_fake_v = net_discr(gen_output_v.detach())
dis_loss = objective(dis_output_true_v, true_labels_v) + \
objective(dis_output_fake_v, fake_labels_v)
dis_loss.backward()
dis_optimizer.step()
dis_losses.append(dis_loss.item())
각각 실제 데이터 샘플과 그 레이블, 생성된 샘플과 그 레이블로 discriminator를 학습시킵니다. discriminator의 학습에서 사용한 그래디언트가 generator로 유입되는 것을 막기 위해 detach() 를 호출합니다. detach()는 상위 operation과의 연결 없이 복사본을 만드는 텐서 방법입니다.
# train generator
gen_optimizer.zero_grad()
dis_output_v = net_discr(gen_output_v)
gen_loss_v = objective(dis_output_v, true_labels_v)
gen_loss_v.backward()
gen_optimizer.step()
gen_losses.append(gen_loss_v.item())
이제는 generator의 학습입니다. generator의 출력값을 discriminator로 전달하지만 gradient를 막지 않습니다. 대신 true label이 있는 데이터쌍만 목적함수의 입력으로 사용합니다. 이로 인해 실제 데이터와 더 유사하게 만드는 방향으로 나아갈 것입니다.
위에까지가 학습이고 다음은 100개 이터레이션마다 로그를 찍고 텐서보드에 관찰값들을 기록하는 코드입니다. 이미지는 1000개마다 저장합니다.
iter_no += 1
if iter_no % REPORT_EVERY_ITER == 0:
log.info("Iter %d: gen_loss=%.3e, dis_loss=%.3e",
iter_no, np.mean(gen_losses),
np.mean(dis_losses))
writer.add_scalar(
"gen_loss", np.mean(gen_losses), iter_no)
writer.add_scalar(
"dis_loss", np.mean(dis_losses), iter_no)
gen_losses = []
dis_losses = []
if iter_no % SAVE_IMAGE_EVERY_ITER == 0:
writer.add_image("fake", vutils.make_grid(
gen_output_v.data[:64], normalize=True), iter_no)
writer.add_image("real", vutils.make_grid(
batch_v.data[:64], normalize=True), iter_no)
이 예제의 학습 과정은 꽤 오래 걸립니다. 처음에 만든 이미지들은 거의 랜덤한 노이즈 값인데 10,000~20,000번의 이터레이션 후에는 점점 더 실제 이미지와 유사해지는 경향이 있습니다. 저자는 40,000~50,000 정도 했을 때 다음과 같이 꽤 잘 따라한 이미지를 얻을 수 있다고 합니다.

PyTorch Ignite
pytorch를 사용하면서 함께 쓰면 유용한 라이브러리들이 있습니다. ptlearn, fastai, ignite 등 입니다. 다른 라이브러리들은 https://pytorch.org/ecosystem 이 곳에서 확인할 수 있습니다.
물론 이런 라이브러리들만 쓰다가 pytorch를 비롯해 low level의 디테일을 잊으면 안됩니다. 그래서 초반에는 pytorch code 중심으로 사용하고 후에는 high level 라이브러리들을 사용할 예정입니다. 특히 pytorch ignite 를 사용할 예정인데 여기서 간단히 살펴보도록 하겠습니다.
Ignite concepts
Ignite는 PyTorch에서 학습 루트의 코드 작성을 단순화해줍니다. Ignite의 핵심은 Engine class 입니다. 이 클래스는 데이터 소스에서 루프를 돌리고 데이터 배치에서 학습을 진행시킵니다. 또한 Ignite는 학습 루프의 다믕과 같은 조건에서 호출되는 기능을 제공합니다.
- 전체 학습 절차의 처음과 끝
- 학습 에폭의 처음과 끝
- 단일 배치 과정의 처음과 끝
이외에도 커스텀 이벤트가 존재합니다. 예를 들어, 100개의 배치 또는 매 초마다 계산을 수행하려는 경우와 같이 모든 N개의 이벤트로 호출할 함수를 지정할 수 있습니다.
다음과 같은 식으로 Ignite를 쓸 수 있습니다. 아래 코드는 형태만 어떤 방식인지 써놓은 것입니다.
from ignite.engine import Engine, Events
def training(engine, batch):
optimizer.zero_grad()
x, y = prepare_batch()
y_out = model(x)
loss = loss_fn(y_out, y)
loss.backward()
optimizer.step()
return loss.item()
engine = Engine(training)
engine.run(data)
Ignite의 다양한 기능에 대한 설명은 공식 홈페이지에서 확인하면 되고, 여기에선 앞서 다룬 아타리 게임 코드를 Ignite를 쓰면 어떻게 바뀔지 살펴보겠습니다.
from ignite.engine import Engine, Events
from ignite.metrics import RunningAverage
from ignite.contrib.handlers import tensorboard_logger as tb_logger
코드를 보기 전에 임포트할 클래스를 살펴보면, RunningAverage는 np.mean() 대신에 손실값들을 평균 내주는 역할을 합니다. 이 메서드가 더 간편하면서 수학적으로 더 정확하다고 합니다. 그리고 텐서보드의 로거를 임포트합니다.
def process_batch(trainer, batch):
gen_input_v = torch.FloatTensor(
BATCH_SIZE, LATENT_VECTOR_SIZE, 1, 1)
gen_input_v.normal_(0, 1)
gen_input_v = gen_input_v.to(device)
batch_v = batch.to(device)
gen_output_v = net_gener(gen_input_v)
# train discriminator
dis_optimizer.zero_grad()
dis_output_true_v = net_discr(batch_v)
dis_output_fake_v = net_discr(gen_output_v.detach())
dis_loss = objective(dis_output_true_v, true_labels_v) + \
objective(dis_output_fake_v, fake_labels_v)
dis_loss.backward()
dis_optimizer.step()
# train generator
gen_optimizer.zero_grad()
dis_output_v = net_discr(gen_output_v)
gen_loss = objective(dis_output_v, true_labels_v)
gen_loss.backward()
gen_optimizer.step()
if trainer.state.iteration % SAVE_IMAGE_EVERY_ITER == 0:
fake_img = vutils.make_grid(
gen_output_v.data[:64], normalize=True)
trainer.tb.writer.add_image(
"fake", fake_img, trainer.state.iteration)
real_img = vutils.make_grid(
batch_v.data[:64], normalize=True)
trainer.tb.writer.add_image(
"real", real_img, trainer.state.iteration)
trainer.tb.writer.flush()
return dis_loss.item(), gen_loss.item()
그 다음으로는 processing function을 정의해야 합니다. processing function은 데이터 배치를 받아서 discriminator와 generator 모델을 업데이트합니다. 이 함수는 학습 과정에서 추적되는 모든 데이터를 반환할 수 있습니다. 이 예제에서는 각 모델의 손실값이 해당됩니다. 텐서보드에 표시할 이미지도 저장할 수 있습니다.
그 다음은 Engine instance를 생성하고 logger를 붙이고, 학습 프로세스를 실행시키는 코드입니다.
engine = Engine(process_batch)
tb = tb_logger.TensorboardLogger(log_dir=None)
engine.tb = tb
RunningAverage(output_transform=lambda out: out[1]).\
attach(engine, "avg_loss_gen")
RunningAverage(output_transform=lambda out: out[0]).\
attach(engine, "avg_loss_dis")
handler = tb_logger.OutputHandler(tag="train",
metric_names=['avg_loss_gen', 'avg_loss_dis'])
tb.attach(engine, log_handler=handler,
event_name=Events.ITERATION_COMPLETED)
정리하면, processing function을 전달하고 RunningAverage 를 거친 두 개의 손실값을 입력으로 주어 Engine을 만듭니다. 학습 과정에서 RunnningAverage는 계속해서 측정값을 생성하고 generator로부터 온 값은 “avg_loss_gen”이고 discriminator에서 온 값은 “avg_loss_dis”입니다. 이 두 값은 매 이터레이션 후에 텐서보드에 기록됩니다.
@engine.on(Events.ITERATION_COMPLETED)
def log_losses(trainer):
if trainer.state.iteration % REPORT_EVERY_ITER == 0:
log.info("%d: gen_loss=%f, dis_loss=%f",
trainer.state.iteration,
trainer.state.metrics['avg_loss_gen'],
trainer.state.metrics['avg_loss_dis'])
engine.run(data=iterate_batches(envs))
log_losses는 매 이터레이션 완료시 엔진에 의해 호출되는 로깅 함수입니다. 그리고 마지막은 엔진을 실행시키는 코드입니다.
지금 규모가 작은 코드에서는 큰 차이를 못 느끼지만, 실제 프로젝트에서 Ignite는 코드를 더 깔끔하고 확장가능한 형태로 만들어주는 이점이 있습니다.
Summary
- PyTorch 기능 및 특징들 알아보았습니다.
- 손실함수, optimizer, 학습 모니터링 툴에 대해 알아보았습니다.
- 고급 인터페이스를 제공하는 라이브러리인 PyTorch Ignite에 대해 알아보았습니다.
다음 챕터에서는 강화학습의 메인 주제들에 대해 다뤄보도록 하겠습니다.
References
- Deep Reinforcement Learning Hands On 2/E Chapter 03 : Deep Learning with PyTorch
- https://brunch.co.kr/@mnc/9
- https://light-tree.tistory.com/141
- https://dalpo0814.tistory.com/29