
- 교재 : Deep Reinforcement Learning Hands-On 2/E
- github : https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Second-Edition
Intro
Deep Reinforcement Learning Hands-On 2/E 책을 바탕으로 강화학습 기초부터 비교적 최신 알고리즘까지 코드 중심으로 다뤄보도록 하겠습니다.
위에는 교보문고 교재 링크와 깃헙 링크도 올려두었습니다.
2판 코드에서는 텐서플로우와 파이토치, gym 버전도 업데이트되었습니다.
- gym==0.17.3
- torch==1.7.0
- tensorflow==2.3.1
2장에서는 OpenAI의 Gym의 기초에 대해서 다룹니다. OpenAI는 일론 머스크와 샘 알트만이 공동 설립한 인공지능 회사입니다. 인류에게 이익을 주는 것을 목표로 하는 인공지능 연구소입니다. Gym 은 OpenAI에서 만든 라이브러리로 RL agent 와 여러 RL 환경을 제공합니다.
The anatomy of the agent
에이전트와 환경을 파이썬으로 간단하게 구현한 코드를 보면서 감을 익히도록 하겠습니다.
에이전트의 행동과 무관하게 랜덤한 보상을 주는 환경을 만들었습니다. 지금 아래 코드는 사실 환경과 에이전트의 구조가 어떤 식인지를 보여주는 것이 목적이어서 진정한 상호작용 측면은 배제되어 있습니다.
import random
from typing import List
class Environment:
def __init__(self):
# 제한된 스텝 수를 가정
self.steps_left = 10
# 에이전트에게 전달할 현재 환경의 관찰값 반환
# 에이전트 행동에 따라서 상태가 변경되지 않음.
def get_observation(self) -> List[float]:
return [0.0, 0.0, 0.0]
# 가능한 행동 목록
def get_actions(self) -> List[int]:
return [0, 1]
# 남은 스텝이 있는지 아닌지
def is_done(self) -> bool:
return self.steps_left == 0
# 어떤 행동이 입력으로 들어오든 랜덤한 보상 지급
def action(self, action: int) -> float:
if self.is_done():
raise Exception("Game is over")
self.steps_left -= 1
return random.random()
다음은 에이전트입니다. 총 보상을 변수로 가지고, 각 스텝별로 환경의 관찰값을 바탕으로 가능한 행동을 고르고 그에 따른 보상을 누적합니다.
class Agent:
def __init__(self):
self.total_reward = 0.0
def step(self, env: Environment):
current_obs = env.get_observation()
actions = env.get_actions()
reward = env.action(random.choice(actions))
self.total_reward += reward
위 코드의 심플함은 RL 모델의 기본 개념의 중요성을 그리고 있습니다. 환경은 복잡한 물리적 모델이 될 수도 있고, 에이전트는 최신 RL 알고리즘을 구현한 뉴럴넷이 될 수도 있습니다. 하지만 이 기존 패턴은 동일하게 유지됩니다. “매 단계별로 에이전트는 환경으로부터 관찰값을 받고, 계산하고, 행동을 선택한다. 행동의 결과로 보상과 새로운 관찰값을 받는다.”
The OpenAI Gym API
Gym 의 주요 목적은 통일된 인터페이스로 다양하고 풍부한 RL 실험 환경을 제공하는 것입니다. 라이브러리의 중심 클래스 이름이 Env 인 것도 그 증거입니다. Env 클래스의 인스턴스가 제공하는 일부 메서드와 필드를 알아보겠습니다.
- 환경에서 실행할 수 있는 행동 집합
- 환경이 에이전트에게 제공하는 관찰값의 형태와 경계
- step : 행동을 실행하는 메서드로, 현재 관찰값과 보상, 에피소드가 끝났는지를 반환
- reset : 환경 초기 상태와 첫 번째 관찰값을 반환한다.
환경의 구성요소에 대해 자세히 알아보도록 하겠습니다.
The action space
에이전트의 행동은 이산적(discrete), 연속적, 혹은 둘 다 일 수 있습니다. 또한 행동을 하나로 제한할 필요도 없습니다. 이를 대비해서 Gym에서는 여러 행동을 단일한 행동으로 중첩할 수 있는 container class를 제공합니다.
The Observation space
관찰값은 매 스텝마다 환경이 에이전트에게 부여하는 정보의 일부입니다. 관찰값은 단순한 숫자 뭉치일 수도 있고 복잡한 2차원이상의 텐서일 수도 있습니다.
다음은 Gym에서 이 두 공간을 구현한 Space class를 다이어그램으로 표현한 것입니다.
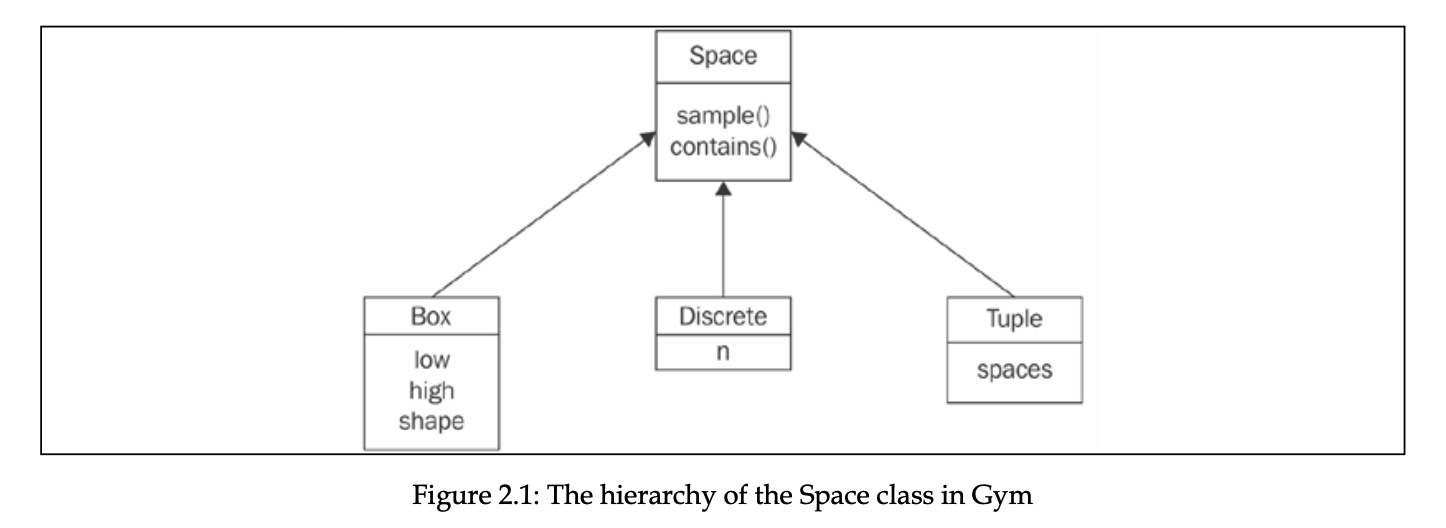
가장 기본인 abstract class인 Space는 두 가지 메서드를 포함하고 있습니다.
- sample() : 해당 공간으로부터 랜덤하게 뽑은 표본 반환
- contains(x) : x가 해당 공간에 속하는지 확인함
두 가지 메서드 모두 abstract method이고 Space의 subclass들로 재구성할 수 있습니다.
- Discrete class는 상호 배제적인 아이템들의 조합을 표현하며, 아이템 개수를 의미하는 n 이라는 필드만 존재합니다. 예들 들어, Discrete class를 이용해서 행동 공간을 상하좌우로 표현할 수 있습니다.
- Box class는 특정 구간 내에서의 n 차원의 tensor를 표현할 수 있습니다. 예를 들어, 엑셀 페달을 0.0 ~ 1.0 사이의 값으로 정의하여 표현할 수 있습니다.
- Tuple class는 여러 Space class를 함께 사용할 수 있도록 허용해줍니다. tuple에 여러 개를 담는다고 생각하면 쉽습니다.
위 세 가지 말고도 다른 subclass들이 있지만 이 세 가지가 가장 유용합니다.
The environment
Gym에서 환경은 Env class로 구현됩니다. Env class 는 다음과 같은 멤버들로 구성됩니다.
- action_space : Space class의 필드로, 해당 환경에서 가능한 행동들을 특정합니다.
- observation_space : Space class의 필드지만, 환경에 의해 제공되는 관찰값들을 특정합니다.
- reset() : 환경을 초기 상태로 바꾸며, 초기 관찰값 벡터를 반환합니다.
- step(action) : action을 입력받아서 행동에 대한 관찰값, 보상, 에피소드가 끝났는지 여부 등을 반환합니다.
- observation : 관찰값, numpy vector or matrix
- reward : 보상값, float
- done : 에피소드 종료 여부, Boolean
- info : 환경에 대한 추가 정보
- render() : 관찰값을 사람이 보기 편하게 보여주는 유틸리티 메서드로, 이 책에서는 다루지 않습니다.
Creating an environment
모든 환경은 고유의 환경이름을 가지고 있습니다. “EnvironmentName-vN” 형태로 되어 있으며, N은 버전 번호입니다. 환경을 만들 때는 gym.make(env_name) 로 선언합니다.
gym의 버전마다 보유하고 있는 환경이 다르고 동일한 환경이라도 버전에 따라 세팅이 다르니 유의할 필요가 있습니다.
환경은 몇 개의 그룹으로 구분됩니다.
- Classic control problems : optimal control theory나 RL 논문에서 벤치마크로 쓰였던 과제로 보통 간단하고 저차원의 관찰값과 행동공간을 구성되어 있습니다. 구현한 알고리즘을 빠르게 체크해볼 때 유용하게 사용할 수 있습니다. 예를 들어, “MNIST for RL”가 있습니다.
- Atari 2600 : 63개의 고전 게임
- Algorithmic : 관찰한 시퀀스를 카피하거나 숫자를 더하는 것과 같은 간단한 계산 과제를 수행하기 위한 문제들
- Board Games : 바둑과 Hex 게임
- Box2D : 걷기나 자동차 통제를 학습할 수 있는 물리적 시뮬레이터를 제공하는 환경
- MuJoCo : 몇몇 연속적인 통제 문제에 쓰이는 물리 시뮬레이터
- Parameter tuning : NN parameters를 최적화하는데 쓰이는 RL
- Toy test : 간단한 grid world를 텍스트로 표현한 환경
- PyGame : PyGame engine으로 만든 몇몇 환경들
- Doom : ViZDoom으로 만든 9개의 미니게임
환경의 전체 리스트는 https://gym.openai.com/envs 에서 확인할 수 있습니다.
The CartPole session
Gym에서 제공하는 가장 간단한 RL 환경인 CartPole에 대해 알아보도록 하겠습니다. CartPole은 아래 그림처럼 검정색 바닥 부분을 움직여서 막대의 균형을 맞추는 게임입니다.
이 환경의 관찰값은 바닥 부분의 중심 좌표(x선에서), 바닥 부분의 속도, 각도, 각도의 속도에 관한 부동 소수점들(floating-points)입니다. 수학적, 물리적 지식을 사용한다면 이 소수점들을 행동으로 바꿔서 막대의 균형을 잡는 것이 어려운 일은 아니지만, 우리의 초점은 “관찰값들에 대한 정확한 의미를 모르고, 보상만 받았을 때 에이전트가 균형 맞추는 것을 학습“하는 데에 있습니다.
The random CartPole agent
이번 세션에서는 액션을 랜덤하게 추출하여 CartPole에서 실험을 해보도록 하겠습니다.
코드는 Chapter02/02_cartpole_random.py 입니다.
import gym
if __name__ == "__main__":
env = gym.make("CartPole-v0")
total_reward = 0.0
total_steps = 0
# 환경 리셋
obs = env.reset()
while True:
# 그래픽으로 볼 수 있음
env.render()
# 랜덤하게 액션을 뽑는다
# 액션은 0 혹은 1 값으로 좌우를 대변한다.
action = env.action_space.sample()
# 액션을 입력받아 다음 단계로 진행
# 관찰값, 보상, 에피소드 종료 여부, 부가정보를 반환한다.
obs, reward, done, _ = env.step(action)
total_reward += reward
total_steps += 1
# 너무 빨리 끝나서 통제하려고 넣었음. 아무 글자나 넣으면 됨.
# input()
if done:
break
print("Episode done in %d steps, total reward %.2f" % (
total_steps, total_reward))
랜덤하게 좌우로 움직이다가 막대가 쓰러지면 끝납니다. 현재 관찰값에 대한 행동의 변화가 없기 때문에 큰 보상을 받기는 어렵습니다.
Extra Gym functionality - wrappers and monitors
Wrappers
환경에서 받는 관찰값이나 보상 등에 대해 처리를 하고 싶을 때가 있습니다. 예를 들어, 즉각적인 관찰값 뿐만 아니라 지난 N개의 관찰값도 같이 에이전트에게 제공하고자 할 수 있습니다. 동적인 컴퓨터 게임에서는 보통 이렇게 합니다. 또 다른 예시로는, 이미지 관찰값을 에이전트가 쉽게 이해하도록 자르거나 전처리를 할 수도 있습니다. Gym에서는 이런 요구사항을 반영할 수 있도록 Wrapper class를 제공합니다.
Wrapper class의 구조는 다음과 같습니다.
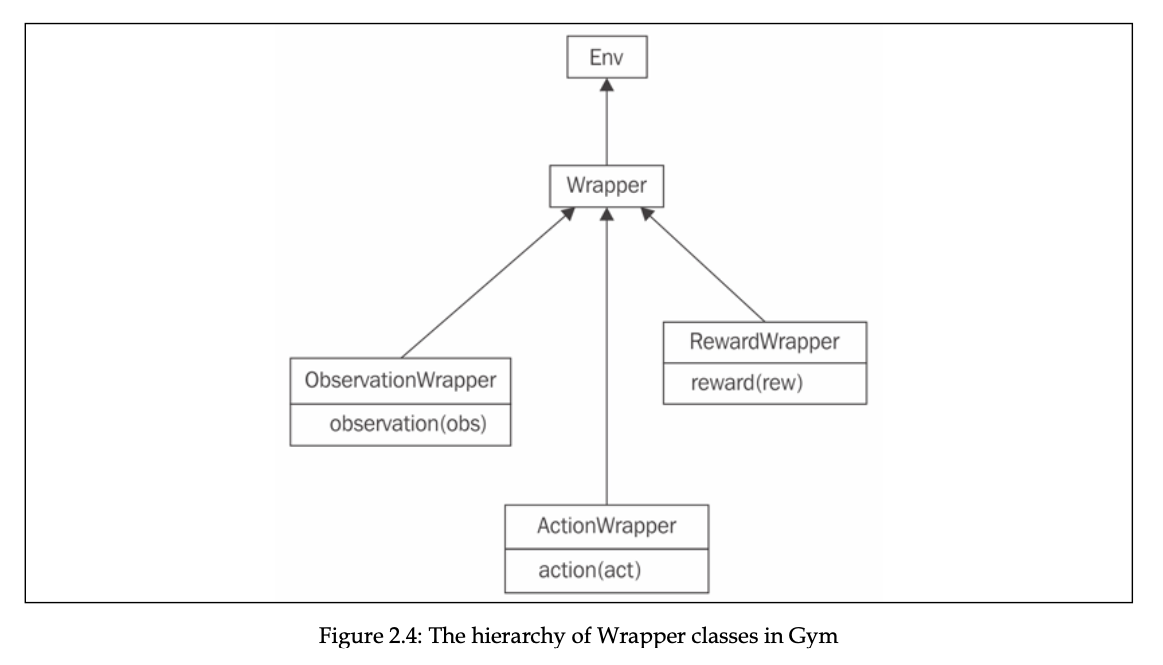
Wrapper class는 Env class를 상속하고 이를 활용할 때에는 gym.Wrapper 를 상속하면 됩니다. 추가 기능을 부여하고자 하면 step()이나 reset() 같은 method들을 재정의하면 됩니다.
class NewWrapper(gym.Wrapper):
def __init__(self, env):
gym.Wrapper.__init__(self, env)
...
def reset(self, **kwargs):
...
return self.env.reset(**kwargs)
def step(self, action):
...
return obs, reward, end, info
더 제한적으로 wrapper class를 사용할 수도 있습니다. 관찰값, 행동 각각에 대해서만 적용할 수 있습니다. 다음 subclass들을 사용하면 됩니다.
-
ObservationWrapper : 관찰값 수정
class NewObs(gym.ObservationWrapper): def __init__(self, env): gym.ObservationWrapper.__init__(self, env) self.observation_space = spaces.Box(...) def observation(self, obs): ... return obs -
RewardWrapper : 보상 수정
class NewRew(gym.RewardWrapper): def __init__(self, env): super(NewRew, self).__init__(env) ... def reward(self, reward): ... return reward -
ActionWrapper : 행동 수정
class NewAction(gym.ActionWrapper): def __init__(self, env): super(NewAction, self).__init__(env) ... def action(self, action: Action) -> Action: ... return action
각 wrapper마다 담당하는 메서드가 다르니 유의해야 합니다. Chapter02/03_random_action_wrapper.py 가 ActionWrapper 를 활용한 예제입니다.
import gym
from typing import TypeVar
import random
Action = TypeVar('Action')
class RandomActionWrapper(gym.ActionWrapper):
def __init__(self, env, epsilon=0.1):
super(RandomActionWrapper, self).__init__(env)
self.epsilon = epsilon
def action(self, action: Action) -> Action:
# 랜덤값이 엡실론값보다 작으면 "Random" 프린트하기
if random.random() < self.epsilon:
print("Random!")
return self.env.action_space.sample()
return action
if __name__ == "__main__":
env = RandomActionWrapper(gym.make("CartPole-v0"))
obs = env.reset()
total_reward = 0.0
total_steps=0
while True:
obs, reward, done, _ = env.step(0)
total_reward += reward
if done:
break
total_steps+=1
print("Total Reward got: %.2f" % total_reward)
ActionWrapper를 상속받아 재정의하였을 경우에 general하게 적용되기 때문에 gym이 제공하는 환경의 행동에는 모두 영향을 미친다. 심지어, 위 코드에서처럼 env.action_space.sample() 이 코드가 제외되고 step()의 argument를 0으로 주더라도 wrapper는 적용되어 있습니다.
Monitors
Monitor는 말그대로 에이전트의 성능을 파일에 저장할 수 있도록 하는 class입니다. 심지어 영상도 가능합니다.
(2017년 8월까지는 Monitor class의 recording을 https://gym.openai.com website에서 볼 수 있었다고 하는데 이 기능은 중단되었다고 합니다.)
Monitor 설정은 환경 설정에 이어서 합니다.
import gym
if __name__ == "__main__":
env = gym.make("CartPole-v0")
env = gym.wrappers.Monitor(env, "recording")
Monitor의 두 번째 argument는 기록한 결과를 저장할 디렉토리 이름입니다. 그래서 만약에 동일한 디렉토리 이름이 있으면 에러가 납니다. 기존 것을 지우고 새 것으로 갈아치우려면 Monitor에 force=True argument를 추가해주면 됩니다.
Monitor class는 FFmpeg utility가 시스템에 있어야 합니다. FFmpeg 는 캡쳐한 관찰값들을 결과 영상 파일로 변환하는 데 쓰입니다. 이게 없으면 에러가 나니 유의하시기 바랍니다. 설치 방법은 다음과 같습니다.
- OS X 일 경우(mac) : brew install ffmpeg
- ubuntu 일 경우 : sudo apt-get install ffmpeg
ffmpeg가 python 3.9 와 dependency가 있어서 파이썬 버전 중 3.9를 추가해주시면 됩니다. 예를 들어, 저는 pyenv 를 사용하고 있는데 pyenv install 3.9.0 으로 python 3.9.0 버전을 설치해두고 (에러가 났을 경우) 다시 설치했습니다.
성공적으로 설치하면 다음과 같이 명령어를 입력합니다.
$ Xvfb :1337 & export DISPLAY=:1337 & python 04_cartpole_random_monitor.py
아래와 같은 에러가 나긴 하는데 동작합니다.
zsh: command not found: Xvfb
정상적으로 실행이 완료되면 결과 디렉토리 아래에 3개의 json 파일과 1개의 동영상 파일이 떨어집니다. 저 영상 파일이 실행할 때 뜨는 그래픽과 동일합니다.
Summary
- OpenAI의 Gym을 설치해보고 기본적은 API를 다뤄보면서 랜덤하게 행동하는 에이전트를 만들어봄.
- 기존 환경의 확장판을 어떻게 만드는지 Wrapper class를 통해 알아봄.
- Monitor class로 에이전트의 행동 결과를 기록하는 방법에 대해 익힘.
다음 챕터에서는 PyTorch를 사용하여 모델을 만들어서 적용해보는 시간을 가질 예정입니다. 감사합니다.
References
- Deep Reinforcement Learning Hands On 2/E Chapter 02 : OpenAI Gym